Reports from the Heart of the Machine
Editors; Zenan, Du Wei
Jen-Hsun Huang: The performance of the chip has doubled every generation, and the next "TensorFlow" level AI tool is my NVIDIA.
Every spring, AI practitioners and gamers look forward to NVIDIA's new releases, and this year is no exception.
On the evening of March 22, Beijing time, the new year's GTC conference was held as scheduled, and Huang Jenxun, founder and CEO of NVIDIA, walked out of his kitchen this time and entered the meta-universe to give a Keynote speech:
"We have witnessed the ability of AI to discover new drugs and compounds in science. AI now learns biology and chemistry just as it did to understand images, sounds, and speech." "Once computer power catches up, industries like pharmaceuticals will undergo the same changes in technology as they did before," Huang said.
The WAVE of AI triggered by the development of GPUs has not passed since the beginning of today, and pre-trained models and self-supervised learning models such as Transformer have more than once appeared "unaffordable".
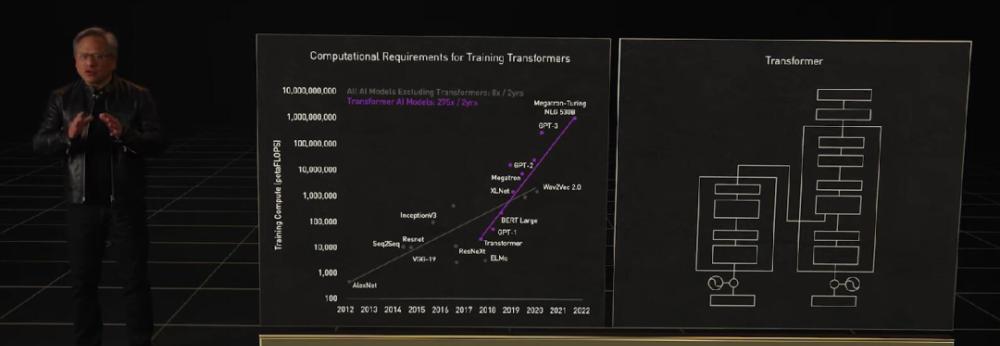
The demand for computing power has risen exponentially because of the large model, and Lao Huang has come up with a next-generation Hopper architecture for high-performance computing (HPC) and data centers this time, and the first acceleration card equipped with a new generation of chips is named H100, which is an alternative to A100.
The Hopper architecture, which takes its name from computer science pioneer Grace Hopper, continues NVIDIA's "tradition" of doubling the performance of every generation of architecture, with many more unexpected capabilities.
Chips are specially designed for large models such as the GPT-3
The H100 is built using A TSMC's 5nm custom version of the process (4N), with a single chip containing 80 billion transistors. It is also the world's first PCI-E 5 and HBM 3 graphics card, and the IO bandwidth of an H100 is 40 terabytes per second.
"To illustrate what this number is, 20 NVIDIA H100 bandwidths are equivalent to global Internet communications," Mr. Wong said.
Huang Renxun listed five major innovations in the Hopper architecture compared to the previous generation of amperes:

The first is a leap in performance, achieved through the new tensor processing format FP8. The FP8 hash rate for the H100 is 4PetaFLOPS, the FP16 is 2PetaFLOPS, the TF32 hash rate is 1PetaFLOPS, and the hash rate for FP64 and FP32 is 60 TeraFLOPS.
Although a little smaller than apple's M1 Ultra's 114 billion transistors, the H100 can be as high as 700W — the previous generation A100 was still 400W. "On AI missions, the FP8 precision hash rate of the H100 is six times that of the FP16 on the A100. This is the biggest performance improvement in our history," Huang said.
Image source: anandtech
Transformer-like pre-trained models are currently the hottest direction in the FIELD of AI, and NVIDIA even optimized the design of the H100 specifically for this purpose, proposing the Transformer Engine, which combines the new Tensor Core, FP8 and FP16 precision computation, as well as the dynamic processing power of Transformer neural networks, which can shorten the training time of such machine learning models from weeks to days.
The Transformer engine lives up to its name and is a new, highly specialized tensor core. In short, the goal of the new unit is to train the Transformer with the lowest possible precision without losing the final model performance.
For server applications, the H100 can also be virtualized for use by 7 users, each user obtaining computing power equivalent to two full-power T4 GPUs. And even better for business users, the H100 implements the industry's first GPU-based confidential computing.
Hopper also introduced the DPX instruction set, which is designed to speed up dynamic programming algorithms. Dynamic programming breaks down complex problems into subproblems that are recursively solved, and the Hopper DPX instruction set reduces the processing time of such tasks by a factor of 40.
The Hopper architecture chip and HBM 3 memory are packaged on the board using the TSMC CoWoS 2.5D process to form a "super chip module SXM", which is an H100 accelerator card:
This graphics card can be held with great care – it looks incredibly compact and stuffed with components throughout the board. On the other hand, such a structure is also suitable for liquid cooling – the H100 design 700W TDP is already very close to the upper limit of heat dissipation.
Self-built the world's first AI supercomputer
"Technology companies that process and analyze data, build AI software, and have become intelligent manufacturers. Their data centers are AI factories," Mr. Huang said.
Based on the Hopper architecture of the H100, NVIDIA launched a series of products such as machine learning workstations and supercomputers. Eight H100 and 4 NVLinks combine to form a giant GPU, the DGX H100, which has a total of 640 billion transistors, 32 petaflops of AI hash rate, and HBM3 has a memory capacity of up to 640G.
The new NVLINK Swith System can also directly parallel up to 32 DGX H100s to form a DGX POD with 256 GPUs.
"The bandwidth of the DGX POD is 768 terbytes per second, which is currently 100 terbytes per second for the entire Internet," Huang said.
A supercomputer based on a new superPOD is also on the way, and Nvidia announced that it will build its own supercomputer called EoS based on the H100 chip, which consists of 18 DGX PODs, a total of 4608 H100 GPUs. By traditional supercomputing standards, EoS hash rate of 275petaFLOPS, which is 1.4 times that of the current largest supercomputer Summit in the United States, which is currently based on A100.
From an AI computing perspective, EoS outputs 18.4 Exaflops, which is four times that of Fugaku, the world's first supercomputer today.
All in all, EoS will be the world's fastest AI supercomputer, and Nvidia says it will come online in a few months.
Here's a look at the H100's performance improvements on specific tasks: Training GPT-3s is 6.3 times faster based on GPU computing power alone, and up to 9 times faster when combined with new precision, chip interconnect technology, and software. For the inference work of the big model, the H100 is 30 times more throughput than the A100.
For traditional servers, NVIDIA proposed the H100 CNX, which bypasses the PCIE bottleneck by directly paralleling the network with the H100 to improve AI performance.
Nvidia updated its own server CPU, the new Grace Hopper can be two pieces in parallel on the same motherboard, forming a CPU with 144 cores, power consumption of 500W, which is 2-3 times the performance of the current product, and the energy efficiency ratio is also twice.
On Grace, the interconnection technology between several chips is a new generation of NVlink, which enables high-speed interconnection from grain to grain, chip to chip, and system to system. Huang Jenxun pointed out that grace CPUs and Hopper can be customized through NVlink. Nvidia's technology can meet all user needs, and in the future, Nvidia's CPUs, GPUs, DPU, NICs and SoCs can all achieve chip-side high-speed interconnection through this technology.
Nvidia plans to launch H100-equipped systems in the third quarter of this year, including DGX, DGX SuperPod servers, and servers from OEM partners using HGX substrates and PCIe cards.
As for the price, yesterday Lao Huang did not say "the more you buy, the more you save."
There were rumors that the Ada Lovelace architecture dedicated to games did not appear in Huang Jenxun's keynote yesterday, and it seems that there will be more waiting.
A metaverse that is visible to everyone
"The first wave of AI learned about the predictive inferences of organisms, such as image recognition, language understanding, and the ability to recommend goods to people. The next wave of AI will be robots: AI makes plans, where digital, physical robots perceive, plan and act," Huang said. "Frameworks such as TensorFlow and PyTorch are the necessary tools for the first wave of AI, and Nvidia's Omniverse is a tool for the second wave of AI that will start the next wave of AI."
In the case of the metaverse, Nvidia can be said to have been at the forefront, and its proposed Omniverse is the gateway to connect all metaverses. But in the past, Omniverse was designed for the data center, where the virtual world was biased toward industry.
Jen-Hsun Huang said Nvidia's Omniverse covers the next evolution of the digital twin, the virtual world and the internet. The following figures show several typical application scenarios:
For digital twins, Omniverse software and computers must be scalable, low latency, and support for precise time. Therefore, it is important to create a synchronized data center. Based on this, Nvidia introduced NVIDIA OVX, a scalable Omniverse computing system for data centers for industrial digital twins.
The first generation of NVIDIA OVX Omniverse computers consisted of eight NVIDIA A40 GPUs, three NVIDIA ConnectX-6 200 Gbps nics, two Intel Ice Lake 8362 CPUs, and 1 TB of system memory and 16 TB of NVMe storage.
Nvidia then used a Spectrum-3 200 Gpbs switch to connect 32 OVX servers to form the OVX SuperPOD.
At present, major computer manufacturers around the world are launching OVX servers. The first generation of OVX is being run by NVIDIA and early customers, and the second generation of OVX is also being built from the backbone network. At the meeting, Nvidia announced the availability of Spectrum-4 switches with up to 51.2Tbps bandwidth and 100 billion transistors, which can distribute bandwidth fairly across all ports, provide adaptive routing and congestion control, and significantly improve the overall throughput of the data center.
With ConenctX-7 and BlueField-3 adapters and DOCA data center infrastructure software, Spectrum-4 became the world's first 400Gbps end-to-end networking platform. Compared to typical data center jitter of milliseconds, Spectrum-4 achieves nanosecond timing accuracy of 5 to 6 orders of magnitude improvement. Huang said the prototype is expected to be released by the end of the fourth quarter.
Speaking of metaverses, we have to mention the NVIDIA Omniverse Avatar platform. At the GTC conference, Wong Hadhito had a conversation with "himself" (a virtual person).
At the same time, Nvidia also wanted Omniverse to help designers, creators, and AI researchers, so it launched Omniverse Cloud. With just a few clicks, users and their collaborators can connect. Using NVIDIA RTX PCs, laptops, and workstations, designers can work together in real time. Even without an RTX computer, they can launch Omniverse with a single click from GeForce Now.
For example, in the image below, several designers working remotely use Omniverse View to review projects in a web conference, and they can connect with each other and call up an AI designer. That is, they collaborated to create a virtual world through Omniverse Cloud.
At this GTC conference, Huang Jenxun opened the door to the metaverse.
Continuously refueling autonomous and electric vehicles
Since robotic systems will be the next wave of AI, Jen-Hsun Huang said NVIDIA is building multiple robotic platforms — DRIVE for self-driving cars, ISAAC for manipulation and control systems, Metropolis for autonomous infrastructure, and Holoscan for robotic medical devices. Only drive self-driving car systems are introduced here.
Workflows for robotic systems are complex and can often be simplified to four pillars: collecting and generating truth data, creating AI models, simulating and operating robots using digital twins. Omniverse is at the heart of the entire workflow.
Drive self-driving car systems are essentially "AI drivers." Like other platforms, NVIDIA DRIVE is a full-stack, end-to-end platform that is open to developers who can use the entire platform or part of it. During operation, NVIDIA uses DeepMap HD maps, for example, to collect and generate truth data, and NVIDIA AI on DGX to train AI models. Drive Sim in Omniverse runs on OVX and is a digital twin. DRIVE AV is an autonomous driving application that runs on the in-vehicle Orin computing platform.
In actual driving with the latest version of the DRIVE system, the driver can activate drive Pilot navigation and enter commands by voice. Confidence View shows the person in the car what the car sees and intends to do. AI assistants can detect specific people, multimodal AI assistants can answer driver questions, AI-assisted parking can detect available parking spaces, surround view and advanced visualization make it easy for drivers to park.
All of this is inseparable from the hardware structure of NVIDIA's self-driving car , Hyperion 8, which is also the basis for the entire DRIVE platform. Hyperion 8 consists of multiple sensors, a network, two Chauffeur AV computers, a Concierge AI computer, a task recorder, and a (network) security system. It can be fully autonomous using a suite of 360-degree cameras, radar, lidar and ultrasonic sensors, and will be installed in Mercedes-Benz cars from 2024 and Jaguar Land Rovers from 2025.
Hyperion 8 sensors built in DRIVE Sim provide a real-world view.
Today, Nvidia announced that the Hyperion 9 will be available in cars from 2026 onwards. Compared to its predecessor, hyperion 9 will have 14 cameras, 9 radars, 3 lidars, and 20 ultrasonic sensors. Overall, it processes twice as much sensor data as hyperion 8.
In the field of electric vehicles, NVIDIA DRIVE Orin is the centralized autonomous driving and AI computing platform for the ideal car. Huang Announced at the meeting that Orin will go on sale this month. Not only that, BYD will also install NVIDIA's DRIVE Orin system for electric vehicles put into production in the first half of 2023.
"Omniverse's work in NVIDIA's AI and robotics is very important, and the next wave of AI will need such a platform," Jen-Hsun Huang concluded.
Reference: https://www.anandtech.com/show/17327/nvidia-hopper-gpu-architecture-and-h100-accelerator-announced