機器之心報道
編輯;澤南、杜偉
黃仁勳:晶片每代性能都翻倍,而且下個「TensorFlow」級 AI 工具可是我英偉達出的。
每年春天,AI 從業者和遊戲玩家都會期待英偉達的新釋出,今年也不例外。
中原標準時間 3 月 22 日晚,新一年度的 GTC 大會如期召開,英偉達創始人、CEO 黃仁勳這次走出了自家廚房,進入元宇宙進行 Keynote 演講:
「我們已經見證了 AI 在科學領域發現新藥、新化合物的能力。人工智能現在學習生物和化學,就像此前了解圖像、聲音和語音一樣。」黃仁勳說道「一旦計算機能力跟上,像制藥這樣的行業就會經曆此前科技領域那樣的變革。」
GPU 發展引爆的 AI 浪潮從開始到今天還沒過去十年,Transformer 這樣的預訓練模型和自監督學習模型,已經不止一次出現「算不起」的情況了。
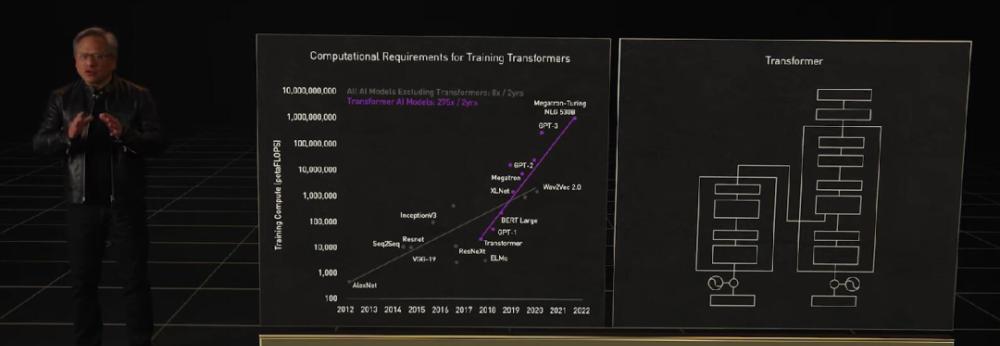
算力需求因為大模型呈指數級上升,老黃這次拿出的是面向高性能計算(HPC)和資料中心的下一代 Hopper 架構,搭載新一代晶片的首款加速卡被命名為 H100,它就是 A100 的替代者。
Hopper 架構的名稱來自于計算機科學先驅 Grace Hopper,其延續英偉達每代架構性能翻倍的「傳統」,還有更多意想不到的能力。
為 GPT-3 這樣的大模型專門設計晶片
H100 使用台積電 5nm 定制版本制程(4N)打造,單塊晶片包含 800 億半導體。它同時也是全球首款 PCI-E 5 和 HBM 3 顯示卡,一塊 H100 的 IO 帶寬就是 40 terabyte 每秒。
「為了形象一點說明這是個什麼數字,20 塊英偉達 H100 帶寬就相當于全球的網際網路通信,」黃仁勳說道。
黃仁勳列舉了 Hopper 架構相對上代安培的五大革新:

首先是性能的飛躍式提升,這是通過全新張量處理格式 FP8 實作的。H100 的 FP8 算力是 4PetaFLOPS,FP16 則為 2PetaFLOPS,TF32 算力為 1PetaFLOPS,FP64 和 FP32 算力為 60TeraFLOPS。
雖然比蘋果 M1 Ultra的 1140 億半導體數量要小一些,但 H100 的功率可以高達 700W——上代 A100 還是 400W。「在 AI 任務上,H100 的 FP8 精度算力是 A100 上 FP16 的六倍。這是我們曆代最大的性能提升,」黃仁勳說道。
圖檔來源:anandtech
Transformer 類預訓練模型是目前 AI 領域裡最熱門的方向,英偉達甚至以此為目标專門優化 H100 的設計,提出了 Transformer Engine,它集合了新的 Tensor Core、FP8 和 FP16 精度計算,以及 Transformer 神經網絡動态處理能力,可以将此類機器學習模型的訓練時間從幾周縮短到幾天。
Transformer 引擎名副其實,是一種新型的、高度專業化的張量核心。簡而言之,新單元的目标是使用可能的最低精度來訓練 Transformer 而不損失最終模型性能。
針對伺服器實際應用,H100 也可以虛拟化為 7 個使用者共同使用,每個使用者獲得的算力相當于兩塊全功率的 T4 GPU。而且對于商業使用者來說更好的是,H100 實作了業界首個基于 GPU 的機密計算。
Hopper 還引入了 DPX 指令集,旨在加速動态程式設計算法。動态程式設計可将複雜問題分解為子問題遞歸解決,Hopper DPX 指令集把這種任務的處理時間縮短了 40 倍。
Hopper 架構的晶片和 HBM 3 記憶體用台積電 CoWoS 2.5D 工藝封裝在闆卡上,形成「超級晶片模組 SXM」,就是一塊 H100 加速卡:
這塊顯示卡拿着可得非常小心——它看起來整體異常緊湊,整個電路闆上塞滿各種元器件。另一方面,這樣的結構也适用于液冷——H100 設計 700W 的 TDP 已經非常接近散熱處理的上限了。
自建全球第一 AI 超算
「科技公司處理、分析資料,建構 AI 軟體,已經成為智能的制造者。他們的資料中心就是 AI 的工廠,」黃仁勳說道。
基于 Hopper 架構的 H100,英偉達推出了機器學習工作站、超級計算機等一系列産品。8 塊 H100 和 4 個 NVLink 結合組成一個巨型 GPU——DGX H100,它一共有 6400 億半導體,AI 算力 32 petaflops,HBM3 記憶體容量高達 640G。
新的 NVLINK Swith System 又可以最多把 32 台 DGX H100 直接并聯,形成一台 256 塊 GPU 的 DGX POD。
「DGX POD 的帶寬是每秒 768 terbyte,作為對比,目前整個網際網路的帶寬是每秒 100 terbyte,」黃仁勳說道。
基于新 superPOD 的超級計算機也在路上,英偉達宣布基于 H100 晶片即将自建一個名叫 EoS 的超級計算機,其由 18 個 DGX POD 組成,一共 4608 個 H100 GPU。以傳統超算的标準看,EoS 的算力是 275petaFLOPS,是目前美國最大超算 Summit 的 1.4 倍,Summit 目前是基于 A100 的。
從 AI 計算的角度來看,EoS 輸出 18.4 Exaflops,是當今全球第一超算富嶽的四倍。
總而言之,EoS 将會是世界上最快的 AI 超級計算機,英偉達表示它将會在幾個月之後上線。
下面看看 H100 在具體任務上的性能提升:單看 GPU 算力的話訓練 GPT-3 速度提升 6.3 倍,如果結合新的精度、晶片互聯技術和軟體,提升增至 9 倍。在大模型的推理工作上,H100 的吞吐量是 A100 的 30 倍。
對于傳統伺服器,英偉達提出了 H100 CNX,通過把網絡與 H100 直接并聯的方式繞過 PCIE 瓶頸提升 AI 性能。
英偉達更新了自家的伺服器 CPU,新的 Grace Hopper 可以在同一塊主機闆上兩塊并聯,形成一個擁有 144 核 CPU,功耗 500W,是目前産品性能的 2-3 倍,能效比也是兩倍。
在 Grace 上,幾塊晶片之間的互聯技術是新一代 NVlink,其可以實作晶粒到晶粒、晶片到晶片、系統到系統之間的高速互聯。黃仁勳特别指出,Grace CPU 與 Hopper 可以通過 NVlink 進行各種定制化配置。英偉達的技術可以滿足所有使用者需求,在未來英偉達的 CPU、GPU、DPU、NIC 和 SoC 都可以通過這種技術實作晶片端高速互聯。
英偉達計劃在今年三季度推出配備 H100 的系統,包括 DGX、DGX SuperPod 伺服器,以及來自 OEM 合作夥伴使用 HGX 基闆和 PCIe 卡伺服器。
至于價格,昨天老黃并沒有說「the more you buy, the more you save.」
此前有傳聞說專用于遊戲的 Ada Lovelace 架構,昨天并沒有出現在黃仁勳的 keynote 中,看來還要再等等。
人人可見的元宇宙
「第一波 AI 學習了生物的預測推斷能力,如圖像識别、語言了解,也可以向人們推薦商品。下一波 AI 将是機器人:AI 做出計劃,在這裡是數字人、實體的機器人進行感覺、計劃并行動,」黃仁勳說道。「TensorFlow 和 PyTorch 等架構是第一波 AI 必須的工具,英偉達的 Omniverse 是第二波 AI 的工具,将會開啟下一波 AI 浪潮。」
在元宇宙這件事上,英偉達可以說一直走在最前面,其提出的 Omniverse 是連接配接所有元宇宙的門戶。但在以往,Omniverse 是面向資料中心設計的,其中的虛拟世界偏向于工業界。
黃仁勳表示,英偉達的 Omniverse 涵蓋了數字孿生、虛拟世界和網際網路的下一次演進。下圖為幾種典型應用場景:
而對于數字孿生而言,Omniverse 軟體和計算機必須具備可擴充、低延遲和支援精确時間的特點。是以,建立同步的資料中心非常重要。基于此,英偉達推出了 NVIDIA OVX——用于工業數字孿生的資料中心可擴充 Omniverse 計算系統。
第一代 NVIDIA OVX Omniverse 計算機由 8 個 NVIDIA A40 GPU、3 個 NVIDIA ConnectX-6 200 Gbps 網卡、2 個 Intel Ice Lake 8362 CPU 以及 1TB 系統記憶體和 16TB NVMe 存儲組成。
然後,英偉達利用 Spectrum-3 200 Gpbs 交換機連接配接 32 台 OVX 伺服器構成了 OVX SuperPOD。
目前,全球各大計算機制造商紛紛推出 OVX 伺服器。第一代 OVX 正由英偉達和早期客戶運作,第二代 OVX 也正從骨幹網絡開始建構當中。會上,英偉達宣布推出帶寬高達 51.2Tbps 且帶有 1000 億個半導體的 Spectrum-4 交換機,它可以在所有端口之間公平配置設定帶寬,提供自适應路由和擁塞控制功能,顯著提升資料中心的整體吞吐量。
憑借 ConenctX-7 和 BlueField-3 擴充卡以及 DOCA 資料中心基礎架構軟體,Spectrum-4 成為世界上第一個 400Gbps 的端到端網絡平台。與典型資料中心數毫秒的抖動相比,Spectrum-4 可以實作納秒級計時精度,即 5 到 6 個數量級的改進。黃仁勳表示,樣機預計将于第四季度末釋出。
說到元宇宙,則不得不提英偉達 Omniverse Avatar 平台。在本次 GTC 大會上,黃仁勳與「自己」(虛拟人)展開了一番對話。
同時,英偉達還希望 Omniverse 為設計師、創作者、AI 研究人員提供幫助,因而推出了 Omniverse Cloud。隻需點選幾下,使用者及其協作者可以完成連接配接。使用 NVIDIA RTX PC、筆記本電腦和工作站,設計師們可以實時協同工作。即使沒有 RTX 計算機,他們也可以從 GeForce Now 上一鍵啟動 Omniverse。
比如下圖中遠端工作的幾位設計師在網絡會議中使用 Omniverse View 來評審項目,他們可以連接配接彼此,并喚出一個 AI 設計師。也即是,他們通過 Omniverse Cloud 協作建立了一個虛拟世界。
在這場 GTC 大會上,黃仁勳打開了元宇宙的大門。
持續加注自動駕駛和電動汽車
既然機器人系統會是下一波 AI 浪潮,黃仁勳表示,英偉達正在建構多個機器人平台——用于自動駕駛汽車的 DRIVE、用于操縱和控制系統的 ISAAC、用于自主式基礎架構的 Metropolis 和用于機器人醫療器械的 Holoscan。這裡隻介紹 DRIVE 自動駕駛汽車系統。
機器人系統的工作流程很複雜,通常可以簡化為四個支柱:收集和生成真值資料、建立 AI 模型、使用數字孿生進行仿真和操作機器人。Omniverse 是整個工作流程的核心。
DRIVE 自動駕駛汽車系統本質上是「AI 司機」。與其他平台一樣,NVIDIA DRIVE 是全棧式端到端平台,對開發者開放,他們可以使用整個平台或者其中一部分。在運作過程中,英偉達使用 DeepMap 高清地圖等收集和生成真值資料,使用 DGX 上的 NVIDIA AI 來訓練 AI 模型。Omniverse 中的 DRIVE Sim 在 OVX 上運作,它屬于數字孿生。DRIVE AV 是一款運作在車載 Orin 計算平台上的自動駕駛應用。
在使用最新版 DRIVE 系統的實際行駛中,駕駛員可以啟動 DRIVE Pilot 導航,語音輸入指令。信心視圖(Confidence View)向車上的人展示汽車看到和打算要做的事。AI 助手可以探測到特定的人,多模态 AI 助手可以回答駕駛員的問題,AI 輔助停車可以檢測可用的停車位,環繞視圖(Surround View)和進階可視化(Advanced Visualization)友善駕駛員泊車。
所有這一切都離不開英偉達自動駕駛汽車硬體結構——Hyperion 8,它也是整個 DRIVE 平台的建構基礎。Hyperion 8 是由多個傳感器、網絡、兩台 Chauffeur AV 計算機、一台 Concierge AI 計算機、一個任務記錄儀以及(網絡)安全系統組成。它可以使用 360 度攝像頭、雷達、雷射雷達和超音波傳感器套件實作全自動駕駛,并将分别從 2024 年起在梅賽德斯奔馳汽車、2025 年起在捷豹路虎汽車中搭載。
DRIVE Sim 中建構的 Hyperion 8 傳感器可以提供真實世界的視圖。
今天,英偉達宣布 Hyperion 9 将從 2026 年起在汽車上搭載。相較于前代,Hyperion 9 将擁有 14 個攝像頭、9 個雷達、3 個雷射雷達和 20 個超聲傳感器。整體而言,它處理的傳感器資料量是 Hyperion 8 的兩倍。
在電動汽車領域,英偉達 DRIVE Orin 是理想汽車的集中式自動駕駛和 AI 計算平台。黃仁勳在會上宣布,Orin 将于本月發售。不僅如此,比亞迪也将為 2023 年上半年投産的電動汽車搭載英偉達 DRIVE Orin 系統。
「Omniverse 在英偉達 AI 和機器人領域的工作中非常重要,下一波 AI 浪潮需要這樣的平台,」黃仁勳最後說道。
參考内容:https://www.anandtech.com/show/17327/nvidia-hopper-gpu-architecture-and-h100-accelerator-announced