Microsoft Teams is about to launch the "Hide My Videos" feature
IT Home December 31 news that microsoft teams can't currently hide their video previews when it comes to video conferencing, but the company is planning to provide this feature soon.
Microsoft Teams is about to launch the "Hide My Videos" feature
Microsoft says constantly looking at your own video previews in Microsoft Teams can cause fatigue, and the new Hide My Videos feature will give users the ability to hide their video footage while others can still see the video without ruining the video experience during a call.
"Seeing yourself puts pressure on your brain because you have to deal with extra information, not to mention distraction — you can avoid that by hiding your videos," Microsoft said. ”
IT House understands that for most users, the feature will begin rolling out in January and will be fully available in February, though MoD and GCC-H users may have to wait until February to March 2022, and the change will only affect Windows and Mac desktop clients.
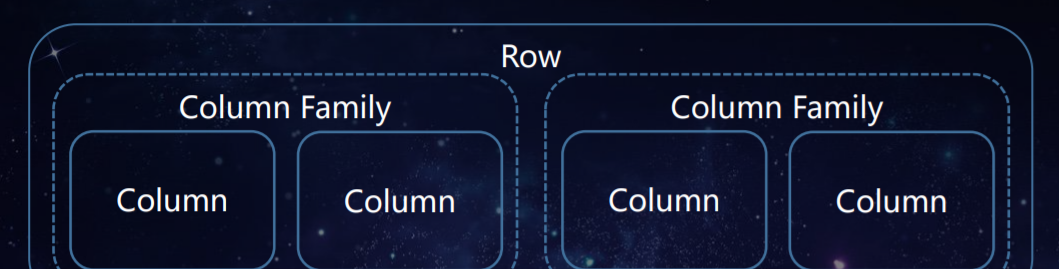
一行(Row)資料是可以包含一個或多個 Column Family,但是我們并不推薦一張 HBase 表的 Column Family 超過三個。Column 是屬于 Column Family 的,一個 Column Family 包含一個或多個 Column。
Region:一段資料的集合;
RegionServer:用于存放Region的服務。
在實體層面上,所有的資料其實是存放在 Region 裡面的,而 Region 又由 RegionServer 管理,其對于的關系如下:
HBase基本知識介紹及典型案例分析
一個 RegionServer 管理多個 Region;而一個 Region 管理一個或多個 Column Family。
HBase基本知識介紹及典型案例分析
這張表有兩個 Column Family ,分别為 personal 和 office。而 personal 又有三列name、city 以及 phone;office 有兩列 tel 以及 address。由于存儲在 HBase 裡面的表一般有上億行,是以 HBase 表會對整個資料按照 RowKey 進行字典排序,然後再對這張表進行橫向切割。切割出來的資料是存儲在 Region 裡面,而不同的 Column Family 雖然屬于一行,但是其在底層存儲是放在不同的 Region 裡。是以這張表我用了六種顔色表示,也就是說,這張表的資料會被放在六個 Region 裡面的,這就可以把資料盡可能的分散到整個叢集。