26 | Superscalar和VLIW:如何讓CPU的吞吐率超過1?
到今天為止,專欄已經過半了。過去的 20 多講裡,我給你講的内容,很多都是圍繞着怎麼提升 CPU 的性能這個問題展開的。
我們先回顧一下第 4 講,不知道你是否還記得這個公式:
程式的 CPU 執行時間 = 指令數 × CPI × Clock Cycle Time
這個公式裡,有一個叫 CPI 的名額。我們知道,CPI 的倒數,又叫作 IPC(Instruction Per Clock),也就是一個時鐘周期裡面能夠執行的指令數,代表了 CPU 的吞吐率。那麼,這個名額,放在我們前面幾節反複優化流水線架構的 CPU 裡,能達到多少呢?
答案是,最佳情況下,IPC 也隻能到 1。因為無論做了哪些流水線層面的優化,即使做到了指令執行層面的亂序執行,CPU 仍然隻能在一個時鐘周期裡面,取一條指令。
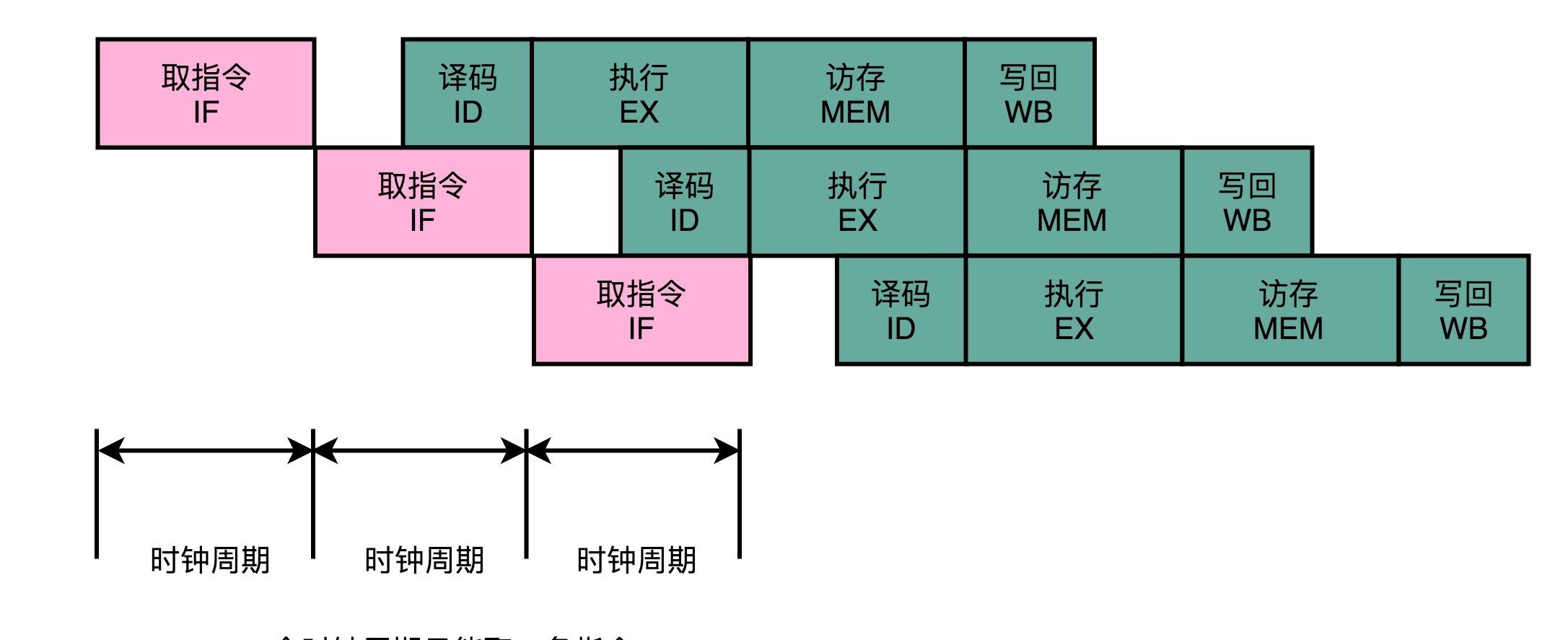
這說明,無論指令後續能優化得多好,一個時鐘周期也隻能執行完這樣一條指令,CPI 隻能是 1。但是,我們現在用的 Intel CPU 或者 ARM 的 CPU,一般的 CPI 都能做到 2 以上,這是怎麼做到的呢?
今天,我們就一起來看看,現代 CPU 都使用了什麼“黑科技”。
多發射與超标量:同一實踐執行的兩條指令
之前講 CPU 的硬體組成的時候,我們把所有算術和邏輯運算都抽象出來,變成了一個 ALU 這樣的“黑盒子”。你應該還記得第 13 講到第 16 講,關于加法器、乘法器、乃至浮點數計算的部分,其實整數的計算和浮點數的計算過程差異還是不小的。實際上,整數和浮點數計算的電路,在 CPU 層面也是分開的。
一直到 80386,我們的 CPU 都是沒有專門的浮點數計算的電路的。當時的浮點數計算,都是用軟體進行模拟的。是以,在 80386 時代,Intel 給 386 配了單獨的 387 晶片,專門用來做浮點數運算。那個時候,你買 386 晶片的話,會有 386sx 和 386dx 這兩種晶片可以選擇。386dx 就是帶了 387 浮點數計算晶片的,而 sx 就是不帶浮點數計算晶片的。
其實,我們現在用的 Intel CPU 晶片也是一樣的。雖然浮點數計算已經變成 CPU 裡的一部分,但并不是所有計算功能都在一個 ALU 裡面,真實的情況是,我們會有多個 ALU。這也是為什麼,在第 24 講講亂序執行的時候,你會看到,其實指令的執行階段,是由很多個功能單元(FU)并行(Parallel)進行的。
不過,在指令亂序執行的過程中,我們的取指令(IF)和指令譯碼(ID)部分并不是并行進行的。
既然指令的執行層面可以并行進行,為什麼取指令和指令譯碼不行呢?如果想要實作并行,該怎麼辦呢?
其實隻要我們把取指令和指令譯碼,也一樣通過增加硬體的方式,并行進行就好了。我們可以一次性從記憶體裡面取出多條指令,然後分發給多個并行的指令譯碼器,進行譯碼,然後對應交給不同的功能單元去處理。這樣,我們在一個時鐘周期裡,能夠完成的指令就不隻一條了。IPC 也就能做到大于 1 了。

這種 CPU 設計,我們叫作多發射(Mulitple Issue)和超标量(Superscalar)。
什麼叫多發射呢?這個詞聽起來很抽象,其實它意思就是說,我們同一個時間,可能會同時把多條指令發射(Issue)到不同的譯碼器或者後續處理的流水線中去。
在超标量的 CPU 裡面,有很多條并行的流水線,而不是隻有一條流水線。“超标量“這個詞是說,本來我們在一個時鐘周期裡面,隻能執行一個标量(Scalar)的運算。在多發射的情況下,我們就能夠超越這個限制,同時進行多次計算。
你可以看我畫的這個超标量設計的流水線示意圖。仔細看,你應該能看到一個有意思的現象,每一個功能單元的流水線的長度是不同的。事實上,不同的功能單元的流水線長度本來就不一樣。我們平時所說的 14 級流水線,指的通常是進行整數計算指令的流水線長度。如果是浮點數運算,實際的流水線長度則會更長一些。
Intel 的失敗之作:安騰的超長指令字設計
無論是之前幾講裡講的亂序執行,還是現在更進一步的超标量技術,在實際的硬體層面,其實實施起來都挺麻煩的。這是因為,在亂序執行和超标量的體系裡面,我們的 CPU 要解決依賴沖突的問題。這也就是前面幾講我們講的冒險問題。
CPU 需要在指令執行之前,去判斷指令之間是否有依賴關系。如果有對應的依賴關系,指令就不能分發到執行階段。因為這樣,上面我們所說的超标量 CPU 的多發射功能,又被稱為動态多發射處理器。這些對于依賴關系的檢測,都會使得我們的 CPU 電路變得更加複雜。
于是,計算機科學家和工程師們就又有了一個大膽的想法。我們能不能不把分析和解決依賴關系的事情,放在硬體裡面,而是放到軟體裡面來幹呢?
如果你還記得的話,我在第 4 講也講過,要想優化 CPU 的執行時間,關鍵就是拆解這個公式:
程式的 CPU 執行時間 = 指令數 × CPI × Clock Cycle Time
當時我們說過,這個公式裡面,我們可以通過改進編譯器來優化指令數這個名額。那接下來,我們就來看看一個非常大膽的 CPU 設計想法,叫作超長指令字設計(Very Long Instruction Word,VLIW)。這個設計呢,不僅想讓編譯器來優化指令數,還想直接通過編譯器,來優化 CPI。
圍繞着這個設計的,是 Intel 一個著名的“史詩級”失敗,也就是著名的 IA-64 架構的安騰(Itanium)處理器。隻不過,這一次,責任不全在 Intel,還要拉上可以稱之為矽谷起源的另一家公司,也就是惠普。
之是以稱為“史詩”級失敗,這個說法來源于惠普最早給這個架構取的名字,顯式并發指令運算(Explicitly Parallel Instruction Computer),這個名字的縮寫EPIC,正好是“史詩”的意思。
好巧不巧,安騰處理器和和我之前給你介紹過的 Pentium 4 一樣,在市場上是一個失敗的産品。在經曆了 12 年之久的設計研發之後,安騰一代隻賣出了幾千套。而安騰二代,在從 2002 年開始反複掙紮了 16 年之後,最終在 2018 年被 Intel 宣告放棄,退出了市場。自此,世上再也沒有這個“史詩”伺服器了。
那麼,我們就來看看,這個超長指令字的安騰處理器是怎麼回事兒。
在亂序執行和超标量的 CPU 架構裡,指令的前後依賴關系,是由 CPU 内部的硬體電路來檢測的。而到了超長指令字的架構裡面,這個工作交給了編譯器這個軟體。
我從專欄第 5 講開始,就給你看了不少 C 代碼到彙編代碼和機器代碼的對照。編譯器在這個過程中,其實也能夠知道前後資料的依賴。于是,我們可以讓編譯器把沒有依賴關系的代碼位置進行交換。然後,再把多條連續的指令打包成一個指令包。安騰的 CPU 就是把 3 條指令變成一個指令包。
CPU 在運作的時候,不再是取一條指令,而是取出一個指令包。然後,譯碼解析整個指令包,解析出 3 條指令直接并行運作。可以看到,使用超長指令字架構的 CPU,同樣是采用流水線架構的。也就是說,一組(Group)指令,仍然要經曆多個時鐘周期。同樣的,下一組指令并不是等上一組指令執行完成之後再執行,而是在上一組指令的指令譯碼階段,就開始取指令了。
值得注意的一點是,流水線停頓這件事情在超長指令字裡面,很多時候也是由編譯器來做的。除了停下整個處理器流水線,超長指令字的 CPU 不能在某個時鐘周期停頓一下,等待前面依賴的操作執行完成。編譯器需要在适當的位置插入 NOP 操作,直接在編譯出來的機器碼裡面,就把流水線停頓這個事情在軟體層面就安排妥當。
雖然安騰的設想很美好,Intel 也曾經希望能夠讓安騰架構成為替代 x86 的新一代架構,但是最終安騰還是在前前後後折騰将近 30 年後失敗了。2018 年,Intel 宣告安騰 9500 會在 2021 年停止供貨。
安騰失敗的原因有很多,其中有一個重要的原因就是“向前相容”。
一方面,安騰處理器的指令集和 x86 是不同的。這就意味着,原來 x86 上的所有程式是沒有辦法在安騰上運作的,而需要通過編譯器重新編譯才行。
另一方面,安騰處理器的 VLIW 架構決定了,如果安騰需要提升并行度,就需要增加一個指令包裡包含的指令數量,比方說從 3 個變成 6 個。一旦這麼做了,雖然同樣是 VLIW 架構,同樣指令集的安騰 CPU,程式也需要重新編譯。因為原來編譯器判斷的依賴關系是在 3 個指令以及由 3 個指令組成的指令包之間,現在要變成 6 個指令和 6 個指令組成的指令包。編譯器需要重新編譯,交換指令順序以及 NOP 操作,才能滿足條件。甚至,我們需要重新來寫編譯器,才能讓程式在新的 CPU 上跑起來。
于是,安騰就變成了一個既不容易向前相容,又不容易向後相容的 CPU。那麼,它的失敗也就不足為奇了。
可以看到,技術思路上的先進想法,在實際的業界應用上會遇到更多具體的實踐考驗。無論是指令集向前相容性,還是對應 CPU 未來的擴充,在設計的時候,都需要更多地去考慮實踐因素。
總結延伸
這一講裡,我和你一起向 CPU 的性能發起了一個新的挑戰:讓 CPU 的吞吐率,也就是 IPC 能夠超過 1。
我先是為你介紹了超标量,也就是 Superscalar 這個方法。超标量可以讓 CPU 不僅在指令執行階段是并行的,在取指令和指令譯碼的時候,也是并行的。通過超标量技術,可以使得你所使用的 CPU 的 IPC 超過 1。
在 Intel 的 x86 的 CPU 裡,從 Pentium 時代,第一次開始引入超标量技術,整個 CPU 的性能上了一個台階。對應的技術,一直沿用到了現在。超标量技術和你之前看到的其他流水線技術一樣,依賴于在硬體層面,能夠檢測到對應的指令的先後依賴關系,解決“冒險”問題。是以,它也使得 CPU 的電路變得更複雜了。
因為這些複雜性,惠普和 Intel 又共同推出了著名的安騰處理器。通過在編譯器層面,直接分析出指令的前後依賴關系。于是,硬體在代碼編譯之後,就可以直接拿到調換好先後順序的指令。并且這些指令中,可以并行執行的部分,會打包在一起組成一個指令包。安騰處理器在取指令和指令譯碼的時候,拿到的不再是單個指令,而是這樣一個指令包。并且在指令執行階段,可以并行執行指令包裡所有的指令。
雖然看起來,VLIW 在技術層面更具有颠覆性,不僅僅隻是一個硬體層面的改造,而且利用了軟體層面的編譯器,來組合解決提升 CPU 指令吞吐率的問題。然而,最終 VLIW 卻沒有得到市場和業界的認可。
惠普和 Intel 強強聯合開發的安騰處理器命運多舛。從 1989 開始研發,直到 2001 年才釋出了第一代安騰處理器。然而 12 年的開發過程後,第一代安騰處理器最終隻賣出了幾千套。而 2002 年釋出的安騰 2 處理器,也沒能拯救自己的命運。最終在 2018 年,Intel 宣布安騰退出市場。自此之後,市面上再沒有能夠大規模商用的 VLIW 架構的處理器了。
推薦閱讀
關于超标量和多發射的相關知識,你可以多看一看《計算機組成與設計:硬體 / 軟體接口》的 4.10 部分。其中,4.10.1 和 4.10.2 的推測和靜态多發射,其實就是今天我們講的超長指令字(VLIW)的知識點。4.10.2 的動态多發射,其實就是今天我們講的超标量(Superscalar)的知識點。
課後思考
在超長指令字架構的 CPU 裡面,我之前給你講到的各種應對流水線冒險的方案還是有效的麼?操作數前推、亂序執行,分支預測能用在這樣的體系架構下麼?安騰 CPU 裡面是否有用到這些相關政策呢?