Reporting by XinZhiyuan
Source: Specialized
In recent years, with the development of artificial intelligence and big data technology, deep neural networks have made breakthroughs in speech recognition, natural language processing, image understanding, video analysis and other application fields. Deep neural networks have many model layers, large parameters and complex calculations, which have high requirements on hardware computing power, memory bandwidth and data storage.
As a programmable logic device, an FPGA is characterized by programmability, high performance, low power consumption, high stability, parallelism, and security. Its combination with deep neural networks has become a research hotspot to promote the application of artificial intelligence industry.
This paper first briefly describes the 70-year development process of artificial neural networks and the current mainstream deep neural network model, and introduces the mainstream hardware that supports the development and application of deep neural networks; next, on the basis of introducing the development process, development methods, development processes and model selection of FPGAs, the industrial application research hotspots combining FPGA and deep neural networks are analyzed from six directions.
Then, based on the hardware structure of FPGA and the model characteristics of deep neural network, the design ideas, optimization directions and learning strategies of deep neural network based on FPGA are summarized; next, the evaluation indicators and metric analysis principles of FPGA model selection and related research are summarized; finally, we summarize the five main factors affecting the application of FPGA to deep neural network and conduct a summary analysis.

Thesis link: https://cjc.ict.ac.cn/online/onlinepaper/jlc315.pdf
introduction
With the advent of the intelligent era, the application of artificial intelligence has penetrated into all walks of life in society. As the main research branch of artificial intelligence, the research and development of neural networks has become the main force dominating the current degree of intelligence.
Simply put, neural networks implement brain-like information processing by simulating the connection of neurons in the human brain. In the past seven decades of development history, the development of neural networks has also experienced doubts and troughs, thanks to the persistence of researchers to explore it has made it universally recognized and has the opportunity to better benefit mankind. In order to allow machines to better simulate the human brain to understand the world, neural network models have been continuously innovated and developed, and have undergone important changes from shallow neural networks to deep neural networks.
At present, deep neural networks can use deep structures to extract and fit data features well, and have made breakthroughs in speech recognition, natural language processing, image understanding, video analysis and other application fields. While researchers are pursuing better accuracy, the number of layers and parameters of deep neural network models is also increasing, resulting in higher and higher requirements for hardware computing power, memory bandwidth and data storage. Therefore, high-performance hardware platforms with strong computing power, parallel acceleration, and high data throughput are particularly important for model training and industrial applications.
This section will outline the history of neural networks and current popular deep neural network models, and analyze the mainstream hardware platforms that drive the application of deep neural networks in the industry.
The development of deep neural networks
Compared with the development speed of today's neural networks, its basic theoretical research has experienced many twists and turns in the early stage.
The earliest mathematical model of neural networks was proposed in 1943 by psychologist Professor McCulloch and mathematician Professor Pitts as the McCulloch Pitt neuron model, which mimics neurons in the human brain and is known as the M-P model. The model is a simple linear weighting that enables simulations of human neurons processing signals, a work known as the starting point for artificial neural networks (ANNs), on which subsequent neural network models are based. However, the performance is completely determined by the weights assigned, which makes it difficult for the model to achieve optimal results.
In order to improve the model and allow computers to automatically set weights reasonably, psychologist Hebb proposed the Hebb learning rules in 1949 and was endorsed by Nobel Prize winner Kandel in medicine. Subsequently, Rosenblatt, an experimental psychologist at Cornell University, proposed a perceptron model in 1958, which was the first artificial neural network in the true sense, marking the first climax of neural network research.
Scholars such as Minsky and Papert have analyzed the perceptron model and concluded that the model cannot solve simple XOR isolinear indivisible problems, and the development of neural networks has since entered a low ebb or even almost stagnant state.
Parallel distribution processing, backpropagation algorithms, and the 1982 continuous and discrete Hopfield neural network model were re-opened for researchers, opening another spring in the development of neural networks, and since then neural network model research has begun to develop problem-oriented.
In 1985, Sejnowski and Hinton proposed the Boltzmann machine model inspired by the Hopfield neural network model. The model solves the problem of difficult learning through the inherent representation of the learning data, and then further proposes the restricted Boltzmann machine model and the deep Boltzmann machine model for the model limitations.
The backpropagation algorithm was further developed in 1986 as the cornerstone of subsequent neural network model development, and in 1990 a recurrent neural network for solving data structure relationships appeared.
After half a century of research, Hinton, a professor at the University of Toronto in Canada, and others proposed a deep confidence network model in 2006, which not only proposed a multi-hidden neural network, but also proposed a solution to the training problem of deep neural networks, which opened a boom in the study of deep neural networks. Since then, deep neural network models for specific research problems have sprung up.
A deep convolutional neural network is a neural network model inspired by the human brain's process of understanding the signals received in the eye. The network was proposed as one of the typical models of artificial neural networks and applied brilliantly in the field of computer vision.
The LeNet model proposed by LeCun et al. was initially applied to handwriting recognition as a prototype of a convolutional neural network. In 2012, Hinton et al. proposed the AlexNet model and applied it to the ImageNet image recognition competition, and its accuracy subverted the field of image recognition, making convolutional neural networks enter the public eye.
Subsequently, a large number of classical convolutional neural network models such as NIN, GoogLeNet, VGGNet, etc. that deepen at the network level, Inception V2/V3, which improve efficiency by splitting convolutional kernels, and ResNet and DenseNet, which introduce continuous hop structures in deep networks to alleviate gradient disappearance, etc. In addition, there are SENet, which models the interdependencies between feature channels, ResNext, and ResNeSt, which are improved based on ResNet.
In different research fields, there are also a large number of classic convolutional neural network models, such as UPSNet, FPSNet and OANet dedicated to panoramic segmentation, Faster-RCNN, YOLO v1/v2/v3, SSD, EfficientDet, LRF-Net, etc., dedicated to target tracking, SimeseNet, MDNet. At present, with the continuous progress of society, various variant models of convolutional neural networks have been applied to the fields of unmanned driving, intelligent monitoring and robotics.
The capsule network is a new network architecture proposed by the Hinton team in 2017 to compensate for the lack of understanding of convolutional neural networks in the spatial relationships of objects.
Its difference from convolutional neural networks is that the network is a new type of neural network composed of capsules containing a small group of neurons, and these capsules transmit features through dynamic routing. The unique data representation of the capsule network enables it to consider the location, direction, deformation and other characteristics of the target, and to understand the extracted features.
Subsequently, in order to improve the performance of the capsule network, the method of optimizing the capsule and optimizing the dynamic routing was proposed. At present, the achievements of capsule networks mainly include resisting adversarial attacks, combining graph convolutional neural networks for image classification, and combining attention mechanisms for zero-sample intent recognition.
Deep reinforcement learning is a neural network model that integrates perception and decision-making ability, and its application results really entered the public eye after the emergence of Alpha Go.
The deep reinforcement learning model proposed by Google DeepMind Deep Q-Network has made this model closer to the human way of thinking more favored by more scholars. Subsequently, improvements to deep Q-Network computing methods, network structures, and data structures emerged as three reinforcement learning models: Double DQN, Dueling Network, and Prioritized Replay. In addition, deep Q-Network added recursive thinking to generate deep Recurrent Q-Network. Tian Chunwei et al. used reinforcement learning ideas in the field of goal tracking and proposed the ADNet model.
In addition, following Alpha Go, DeepMind has launched AlphaZero and MuZero based on reinforcement learning, which improves the intelligence level of deep neural networks. Generative adversarial networks (GANs), proposed by Goodfellow et al. in 2014, are a new type of neural network model using game adversarial theory.
This model breaks the dependence of existing neural networks on labels, and has been welcomed by the industry as soon as it appeared and derived many widely popular architecture models, mainly including: the DCGAN model that combines GAN and convolutional neural networks for the first time, the StyleGAN model that uses GAN to refresh face generation tasks, the StackGAN model that explores text and image synthesis, the CycleGAN that converts image styles, Pix2Pix and StyleGAN. For the first time, BigGAN with high fidelity and low symbol gap images can be generated for a VITAL network model that solves sample imbalance in video tracking problems.
Graph neural network is a kind of neural network model developed for graph structure data, which can process and analyze the relationship between data that can be transformed into graph structure, which overcomes the shortcomings of existing neural network models in processing irregular data.
Graph neural network models first originated in 2005, and then Dr. Franco first defined the theoretical basis of the model in 2009, and at the beginning of the proposal, the model did not cause much waves, until 2013 Graph neural networks did not get widespread attention.
In recent years, graph neural networks have been widely used, combined with existing network models. Different extension models of graph neural networks have been proposed continuously, such as Graph Convolutional Networks, Graph Attention Networks, Graph Auto-encoder, Graph Spatial-Temporal Networks, Graph Reinforcement Learning, Graph Adversarial Network Models, etc.
At present, graph neural network models are widely used, not only in computer vision, recommendation systems, social networks, intelligent transportation and other fields, but also in physics, chemistry, biology and knowledge graphs.
Lightweight neural network is a small-volume network model that compresses, quantizes, prunes, decomposes, teacher-student networks, and lightweight designs the neural network structure under the accuracy of the model.
Before 2015, with the continuous improvement of neural network model performance, the increasing network volume and complexity also had a high demand for computing resources, which limited the flexible application of current high-performance network models on mobile devices. In order to solve this problem, on the basis of ensuring accuracy, some lightweight networks came into being. Since 2016, SqueezeNet, ShuffleNet, NasNet, mobileNet, MobileNetV2, MobileNetV3 and other lightweight network models have emerged, and the emergence of these lightweight networks has made it possible for some embedded devices and mobile terminals to run neural networks, and has also made neural networks more widely used.
Automatic Machine Learning (AutoML) is a truly automated machine learning system in response to the growing demand for machine learning practitioners and required funds in the field of machine learning.
AutoML replaces manual work with automated network model selection, target feature selection, network parameter optimization, and model evaluation. That is, AutoML can automatically build a machine learning model structure having a limited computing budget.
AutoML entered the industry with the Google I/O Conference in May 2017 and received a lot of attention. As the depth and number of neural networks continue to increase, most AutoML research will focus on neural architecture search algorithms (NAS), the pioneering work of NAS that GoogleBrain proposed in 2016.
Subsequently, MIT and GoogleBrain made a series of improvements on its basis, adding reinforcement learning, optimization based on sequence models, transfer learning and other reasonable logical ideas, followed by NasNet, NasNet based on regular evolution, PNAS and ENAS. He Xin et al. summarized in detail the current research progress of neural network search algorithms.
Google launched the Cloud AutoML platform, just upload your data, Google's NAS algorithm will find a quick and easy architecture for you.
The emergence of AutoML has reduced the requirements of some industries for machine learning, especially the users of neural networks, in terms of quantity and knowledge reserves, and further broadened the scope of application of machine learning and neural networks.
The mainstream hardware platform for deep neural networks
With the development of hardware technology and deep neural networks, a deep neural network research platform based on heterogeneous mode servers of "CPU + GPU" has been formed, such as NVIDIA's DGX-2. It has 16 Tesla V100 GPUs that provide up to 2 PFLOPs of computing power.
In the face of complex practical application needs and deepening neural network structures, diversified deep neural network hardware platforms have also continued to develop, forming a hardware platform market dominated by general-purpose chips (CPUs, GPUs), semi-formulated chips (FPGAs), fully formulated chips (ASICs), integrated circuit chips (SoCs) and brain-like chips. Computing performance, flexibility, ease of use, cost, and power consumption are factors and criteria for evaluating deep neural network hardware platforms.
GPU
The Graphic Processing Unit was originally dedicated to graphics tasks and consisted primarily of controllers, registers, and logic units. The GPU contains thousands of stream processors that can parallelize the execution of operations, greatly reducing the computing time of the model. Due to its powerful computing power, it is currently mainly used to handle large-scale computing tasks.
NVIDIA introduced the unified computing device architecture CUDA and the corresponding G80 platform in 2006, making the GPU programmable for the first time, so that the GPU's streaming processor has the ability to process single-precision floating-point numbers in addition to processing graphics.
In deep neural networks, most calculations are linear operations on matrices, which involve a large number of data operations, but the control logic is simple. For these huge computing tasks, the parallel processors of GPUs show great advantages. Since AlexNet achieved excellent results in the ImageNet competition in 2012, GPUs have been widely used in the training and inference of deep neural networks.
The advent of a large number of deep neural network software frameworks that rely on GPU operations (such as TensorFlow, PyTorch, Caffe, Theano, and Paddle-Paddle, among others) has greatly reduced the difficulty of using GPUs. Therefore, it has also become the first choice for artificial intelligence hardware, which has been first applied in various scenarios in the cloud and terminals, and is also the MOST widely used and flexible AI hardware at present.
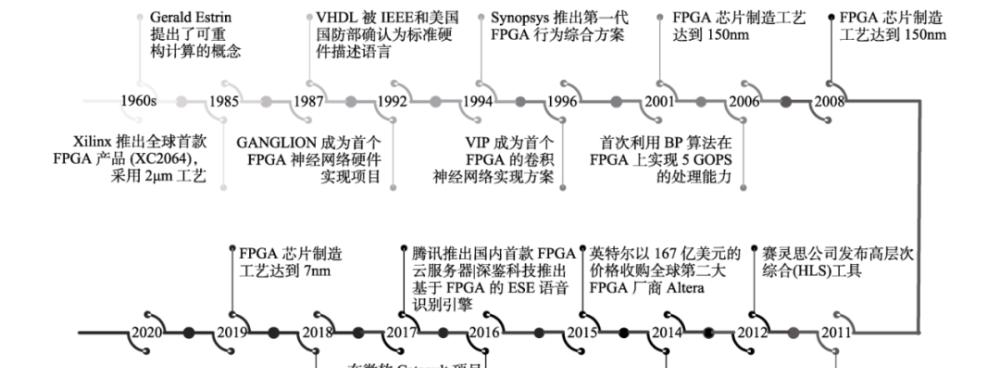
FPGA
The FPGA (Field Programmable Gate Array) is a field programmable gate array that allows an unlimited number of programming and utilizes a small lookup table to implement combinatorial logic.
FPGA can be customized hardware assembly line, can handle multiple applications at the same time or at different times to deal with different applications, with programmable, high performance, low energy consumption, high stability, parallelism and security characteristics, in communications, aerospace, automotive electronics, industrial control, test and measurement and other fields have made a large application market.
Artificial intelligence products are often customized for some specific application scenarios, and the applicability of customized chips is significantly higher than that of general-purpose chips. FPGAs are low cost and highly reconfigurable, allowing for unlimited programmability. Therefore, when the demand for chips is not large or the algorithm is unstable, FPGA is often used to achieve semi-customized artificial intelligence chips, which can greatly reduce the cost from the algorithm to the chip circuit.
With the development of artificial intelligence technology, FPGAs have performed prominently in accelerating data processing, neural network inference, parallel computing, etc., and have made good applications in the fields of face recognition, natural language processing, and network security.
ASIC
ASIC (Application Specific Integrated Circuit) is an application-specific integrated circuit, which refers to an integrated circuit designed and manufactured according to the requirements of specific users and the needs of specific electronic systems.
Compared with the same process FPGA implementation, asEIC can achieve 5 to 10 times faster computing, and the cost of ASICs after mass production will be greatly reduced.
Unlike programmable GPUs and FPGAs, ASICs cannot be changed once manufactured, so they have high development costs, long cycles, and high barriers to entry. For example, in recent years, chips such as Google's TPU, Cambrian NPU, Horizon's BPU, Intel's Nervana, Microsoft's DPU, Amazon's Inderentia, Baidu's XPU and so on are essentially ASIC customization based on specific application-specific artificial intelligence algorithms.
Compared with general-purpose integrated circuits, because ASICs are designed for specific purposes, GoogleBrain has the advantages of smaller size, lower power consumption, improved performance, enhanced confidentiality, etc., and has high commercial value, especially suitable for industrial applications in the field of consumer electronics of mobile terminals.
SoC
SoC (System on Chip) is a system-level chip, generally the central processing unit, memory, controller, software system, etc. integrated on a single chip, usually for special purposes of the specified products, such as mobile phone SoC, TV SoC, automotive SoC and so on.
System-on-chip can reduce development and production costs, compared to ASIC chips, the development cycle is shorter, so it is more suitable for mass production and commercial use.
At present, Qualcomm, AMD, ARM, Intel, Nvidia, Alibaba, etc. are all committed to the research and development of SoC hardware, and the artificial intelligence acceleration engine is integrated into the product to meet the market's demand for artificial intelligence applications.
In 2017, Movidius, a subsidiary of Intel, launched the world's first SoC (Myriad X) equipped with a dedicated neural network computing engine, which integrates hardware modules designed for high-speed, low-power neural networks, mainly used to accelerate deep neural network inference calculations on the device side.
Xilinx's programmable system-on-chip (Zynq family) is an ARM processor-based SoC that offers high performance, low power, multi-core, and development flexibility. Huawei's Ascend 310 is an artificial intelligence SoC chip for computing scenarios.
Brain-like chips
Brain-inspired chip is a low-power chip modeled on the information processing method of the human brain, breaking the separation of storage and computing architecture, and realizing parallel transmission of data and distributed processing.
In von Neumann-based computing chips, the compute module and the memory module are processed separately, introducing delay and wasted power consumption. Brain-like chips focus on modeling human brain neurons and their information processing mechanisms, using flat design structures to efficiently complete computing tasks while reducing energy consumption.
In the era of artificial intelligence, governments, universities, and companies have invested in the research of brain-like chips, typical of which are IBM's TrueNorth, Intel's Loihi, Qualcomm's Zeroth, Tsinghua University's Sky Movement, etc.
At present, deep neural network chips are under continuous research and development, and each chip is designed for a certain problem. Therefore, different chips have their own unique advantages and disadvantages. From the above description of the different chips, we can understand that FPGAs have more computing power and lower power consumption than GPUs. FPGAs offer lower design costs and flexible programmability compared to ASICs and SoCs.
Compared with brain-like chips, the development and design of FPGAs is simpler. Based on the characteristics of the current deep neural network chip, it can be seen that the design performance of FPGAs is more suitable for the development and application of deep neural networks in the general field. With the application of FPGAs in the field of deep neural networks, relevant scholars have analyzed and sorted them out.
This paper summarizes the design principles, model selection, application areas, accelerators and specific acceleration principles, experimental evaluation indicators to the final FPGA applications and influencing factors of deep neural networks, etc., and comprehensively introduces the use of FPGAs for neural network acceleration and provides readers with theoretical and practical guidance.
Resources:
https://cjc.ict.ac.cn/online/onlinepaper/jlc315.pdf