Author | Sarah Wells
Translated by | Wang Qiang
Planning | Ding Xiaoyun
Driven by waves such as cloud migrations, widespread adoption of continuous delivery, and the rise of microservices, software development teams are likely to move forward much faster than they did five years ago. But to do that, these teams need to control their own speed and pace, without having to wait for someone to sign or start a server and submit a ticket every time they publish.
Companies still need teams working on infrastructure, tools, and platforms, but the way they work has to change to avoid bottlenecks. These teams need to realize that their real function is to enable product teams to deliver business value. Investments in this area pay off because it can speed up many other teams, allowing engineers on product teams to focus on solving business problems and delivering value to the organization.
I spent four years as Technical Director at the Financial Times, leading multiple teams focused on engineering capacity building. In this post, I'll talk about how our team is built and some of the important things we've found in the process of really driving the capabilities of other teams to build.
1
Engineering Capacity Building Group
The Ft's product and technology teams are divided into several groups. Each group has a clear focus area. The Engineering Capacity Building Group is made up of a team of all the engineers who have built the tools to support the Financial Times.
There are many teams in this group responsible for providing a layer of toolchain and documentation around the capabilities of key vendors, involving tools like AWS or Fastly; teams need to work closely with key vendors and have a deep understanding of the products they offer and how to best leverage them.
Then, there are teams with domain-specific expertise, such as cybersecurity or web component design.
Other teams are responsible for operations and platform management – we want the engineering team to be the best person to solve the big problems with their systems, but these teams do triage, help manage incidents, patch our supported operating systems to support EC2 instances, and make recommendations on changing instance types or downsizing, and so on.
Finally, we have a team dedicated to engineering insights: create a chart of all our systems, teams, hosts, source libraries, and more, and give our engineers insight into what documents they need to improve/add more scans, and more.
2
principle
We define a set of principles that help us be confident that we are building engineering capabilities that are valuable to our customers. These principles are naturally grouped around specific concerns.
In my opinion, the most important thing is.
Can one use it without the expensive cost of coordination?
In general, engineers should be able to solve their own problems.
This means that, for example, if someone wants to create a DNS entry, they should first be able to easily discover what toolchain can help them. These toolchains should be discoverable.
The general things that engineers need to do should then be documented. There are always people who need to do something complicated, and our team has a couple of slack channels and the people who support those channels — but for that 80% simple transaction, documentation should be sufficient. Recently, we merged engineers' documents into a "Tech Hub." If you go there and search for DNS keywords, you should be able to find what you need.
This screenshot shows the high-level technical topics and DNS-specific subtopics on the Technology Center today.
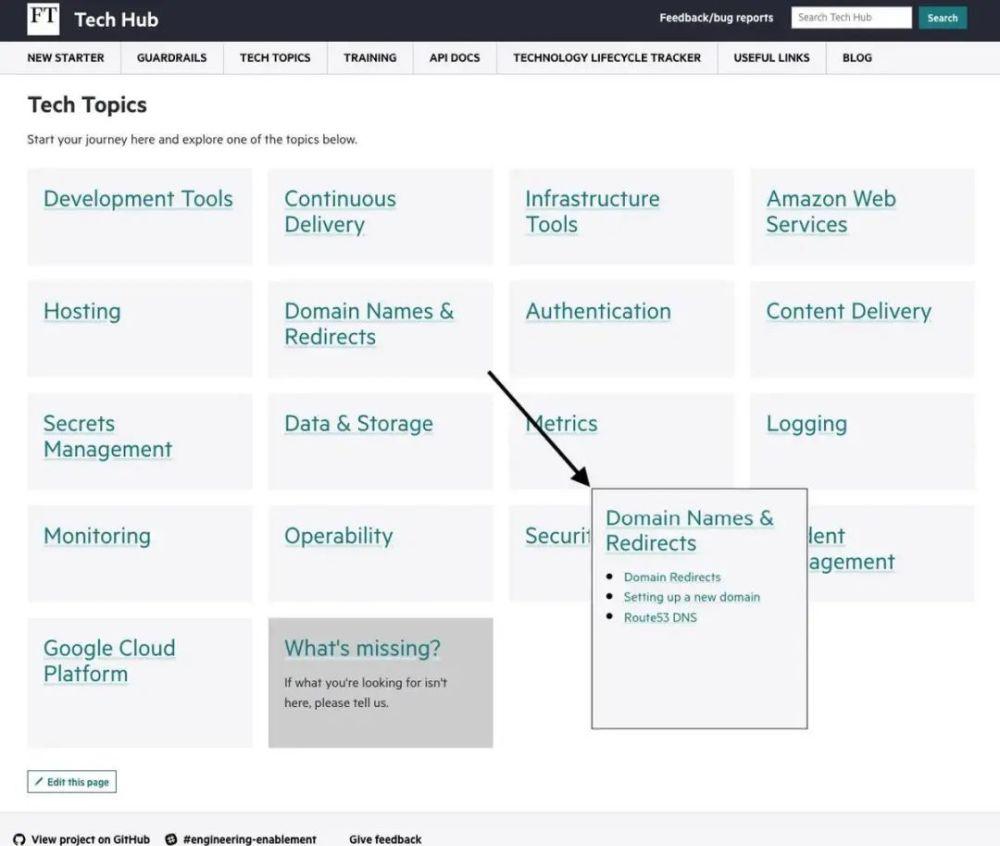
We want everything to be self-serving. There shouldn't be anything to stop engineers from using this feature at any time; they don't need to wait for a ticket or PR to be signed.
The team in charge of DNS recently made a change by adding a bot to our github repository to handle DNS changes so that simple changes can be automatically approved.
Of course, you have to balance the risk here – there will still be areas where we need to exert some control, such as those where going wrong exposes the FT to costs, risks, or security issues. This leads to another set of principles.
Are we directing people to do the right thing?
All abilities should be safe to use; the default configuration should be secure, and we should protect engineers from making mistakes that are easy to avoid.
Capabilities should also be safe and compliant – we will ensure that these shared capabilities are up-to-date and in line with our own policies.
Finally, we need to consider what factors will give people peace of mind when it comes to adopting capabilities.
Is there a risk when the team uses it?
Competencies require accountability and support to minimize the impact of upgrades, migrations and maintenance, and provide years-long coverage.
We should be able to provide transparent usage and cost insights so that teams can understand how their design and architecture choices affect costs. We've found that sharing this information makes teams more likely to take action to reduce their costs.
3
Team autonomy
The FT team has a lot of autonomy, and those powers have their own boundaries. In general, you touch boundaries when you want to make changes that have an impact outside of your team, for example, when you want to introduce a new tool but something already works, or you as a department can get a lot of benefits from a single approach, you can't make your own decisions.
For example, if you want to use another kind of data storage from AWS, that's not a problem; but if you want to bring in a new cloud vendor, you have to justify the additional cost and complexity. Similarly, if you want to start publishing logs in different locations, it affects people's ability to see all the logs for an event in the same place, which can be important when an event occurs.
Sometimes, teams need something that doesn't have a solution yet, and then they can usually try some options. For a brand new supplier, the team goes through a multi-step procurement process — but the team can go through a much shorter process when doing the assessment, as long as they don't plan to do something dangerous, such as sending PII data to the supplier.
Teams do use their autonomy. They decide for themselves the architecture, libraries, and frameworks they use. About five years ago, as the Ft. began adopting microservices, moving to the public cloud, and developing a "you build, you operate" culture, the way the different teams at the FT did things became vastly more diverse.
Since then, there have been more integration processes within the company, as many teams realized they could replicate off-the-shelf patterns to save time and effort. For example, once one team successfully uses CircleCI to build a service, it's easy for other teams to adopt it that way. Some time later, the Central Engineering Capacity Building Team took over the relationship with CircleCI. This process of finding new tools can be very powerful – you already know people want to adopt it!
Move boundaries
Sometimes, we do need to change the boundaries of team autonomy.
A few years ago, we introduced a fairly light process for technology proposals. Anything that affects more than one group or introduces significant changes should be documented in a template format that includes requirements, impacts, costs, and alternatives. The alternative in the documentation must include a "do nothing" scenario so that we can understand what will happen in this case. For example, a few years ago, we needed to move to a new DNS vendor because our existing vendor Dyn was dying. In this case, "doing nothing" is not feasible – and it still makes sense to state this in the documentation.
These documents are sent out for comment and then taken to a meeting called the Technical Management Group for approval. This conference is open to all, and we encourage you to attend the conference to observe and learn. Once the meeting started running online, we found that the number of attendees often reached 40 to 50 people.
If you want to contribute, you should read the proposal beforehand and give feedback. Our aim was to get the meeting to focus more on the final details and communication; all work on consensus had to be done ahead of schedule. In the case of the DNS proposal, the DNS team pre-evaluated several alternatives, with a focus on how to reduce the impact of the change on other teams. They also explained in the documentation how the new approach will move the team to a more streamlined DNS change process through infrastructure-as-code in the github repository. They spoke to each development team before the meeting, so during the review, they were committed to the methodology and timeline.
I don't think every major change is automatically committed to the technical management team, but a lot of things are discussed in this way, and you can go back a year later to understand why we made a certain decision because all the documentation was linked to a github repository.
4
Challenge: Measuring our impact on engineering productivity
I find it often difficult to measure engineering productivity by looking at metrics such as completed work orders. For example, when we assess the speed of sprinting from one sprint to another, I never find any definite trends! Also, it's easy to assess the amount of work done, but it's not the same thing to assess the value that the work provides; it's not a good thing to build the wrong stuff quickly.
In my opinion, the DORA or Accelerate metric is a very good entry-level assessment criterion for businesses. If you're low or moderate in these areas, setting up a CI/CD pipeline and optimizing the speed of release of small changes will give you huge benefits.
Over the past five to ten years, FT has made a lot of changes — moving to the cloud, adopting DevOps, moving to microservices architectures — that have affected our score on these DORA metrics. Important changes during this period include the time it takes to start a new server, and the time it takes from writing code to going live. Both figures went from months to minutes.
This means you can quickly test the value of the work you do. You can do experiments. This means we don't spend months building something and it turns out that our customers hate it or that it doesn't have the impact we expected. An example from a few years ago – we wanted to increase engagement with the Ft. movie reviews, which meant we wanted people to read more movie reviews or spend more time reading them. We quickly added a comment score to the page that listed all the comments – again, when we found out that it was causing the actual comment to be read less, we quickly removed it.
Once you've done well on these metrics (FT has been achieving this for several years), you'll have to figure out something else that can be measured to see the impact of engineering capacity building. This is a challenge for teams today: identify new metrics that best reflect the impact we're having. We do use qualitative metrics such as developer surveys and interviews, and we've been trying to measure the health of the system in various ways.
5
The main lessons I learned
The first is the importance of communication.
You should try to talk to people about what you're doing and why. This means you need to explain why you're setting all kinds of restrictions: whether it's because of cost, complexity, or risk.
Second, providing insight to your team is very valuable.
Try to make your team see all kinds of information and use that information to motivate them to do things. We've found that once we're able to show the team what they need to improve the operational manual, they're more likely to do it. We created a dashboard with a service operability score, so the team could see where the focus of their work should be.

We all have a lot of needs to catch up. If you have a link on your email or dashboard that pinpoints exactly where I need to go and explains exactly what I need to do and why, I'll be more likely to do it.
But finally, and I think the most important point is to focus on decoupling — don't let people wait. Be responsive and help. But at the same time, to decouple further through automation and well-established documentation, you won't spend as much time on boring tasks.
6
My advice to people who are thinking about how to build an organization
I think every organization has to provide at least some centralized engineering services. The question is how far you should go with it.
For me, it depends on what your starting point is. For the Financial Times, moving everyone to a standardized golden path is a daunting task. Given the Financial Times, it's a good idea to establish several golden paths for the main technologies used by the company — for example, one for deploying node applications to Heroku, and the other for serverless using AWS lambdas and standard AWS resources like DynamoDB, S3, and SQS. Many of the steps in these golden paths are common across paths: for example, using the same source control, the same DNS provider, and the same CDN.
For an organization with a more standard set of technologies, I look at where the pain points are: ask engineers what pain points they've encountered and what's holding them back. I bet a centralized team can create a greater impact than having these engineers scattered across feature teams.
But the most important thing is to make sure that the teams that deliver these centralized services understand that their role is for other teams to be able to: respond quickly, get things self-serving and automated, write really well-established documentation, and talk to other engineers so that what they build has the most positive impact on those engineers and organizations.
About the Author:
Sarah Wells has been in development for 20 years, leading delivery teams in consulting, financial services and media. Building FT's content and metadata publishing platform using a microservices-based architecture led to a keen interest in operability, observability, and DevOps, and in early 2018 she took over operational and reliability responsibilities for the Financial Times. More recently, Wells has taken over engineering capacity building, adding platform and security engineering to it. She led a team at the Financial Times to build tools and services for other engineers. Wells leaves FT at the end of 2021 and is taking a break before deciding on her next move. Wells can be contacted via @sarahjwells.
https://www.infoq.com/articles/financial-times-engineering-enablement/