Author | Tina
Internet technology has developed in 2021, and cloud migration is more common, but downtime does not seem to have decreased much.
In October of that year, Facebook, with its 3 billion users, experienced a massive outage, disrupting services for about 7 hours before most of them went live. It is said to be facebook's worst web access accident since its inception, causing Facebook to lose about $47.3 billion (about 304.9 billion yuan) overnight.
Earlier, a domestic video website also crashed due to the failure of the computer room, a large number of users "wandered" to other websites, and the huge traffic peak also paralyzed other platforms. In addition, Salesforce, with 150,000 customers, suffered a global downtime of a global nature of up to 5 hours during the year, and the online gaming platform Roblox also had a 73-hour downtime...
The development of Internet technology to the present, in theory, can achieve "never downtime", but why are there so many large-scale, long-term system failures? How to reduce the occurrence of downtime accidents? InfoQ interviewed Alibaba Cloud's global highly available technology team to talk about how to ensure business sustainability in complex systems.
Speaking from the many downtime incidents
The vigorous development of cloud computing has spawned more and more "national applications", but the traditional disaster recovery architecture has been difficult to meet the needs of rapid business recovery.
Statistics show that 96% of businesses have experienced at least one system outage in the past three years. For small businesses, an hour of downtime can cost an average of $25,000. For large enterprises, the average cost can be as high as $540,000. Nowadays, the longer the downtime, the greater the likelihood of permanent losses.
However, downtime accidents are unpredictable, so it is also known as the "black swan" in the system. Zhou Yang, head of Alibaba Cloud's global high-availability technology team, said that the current large-scale Internet system architecture is becoming more and more complex, stability risks are also increasing, and there will be some undiscovered black swans lurking in the system.
Although it is impossible to predict when the "black swan" will appear, it can seek some classification from the fault and defend against a class of problems in a targeted manner. For example, the current disaster recovery architecture is a disaster prevention method, which is mainly aimed at the failure scenario of the computer room level.
From the perspective of IDC, the main fault scenarios at the machine room level are the network failure of the entrance to the organic room, the network failure of the machine room and the power loss of the computer room. If it is refined to the application layer, it can be divided into access gateway failure, service application failure and database failure, etc., and the cause of the failure behind it may be software BUG or some hardware failure, such as cabinet power failure, access switch failure and so on.
The goal of the disaster recovery architecture is to be able to quickly recover business and protect RTOs and RPOs in the event of any failure in a single room.
RTO (Recovery Time Objective) is the maximum amount of time a user is willing to spend recovering from a disaster. In general, the larger the amount of data, the longer it takes to recover.
RPO (Recovery Point Objective) is the maximum amount of data loss that can be tolerated in the event of a disaster. For example, if a user can afford 1 day of data loss, the RPO is 24 hours.
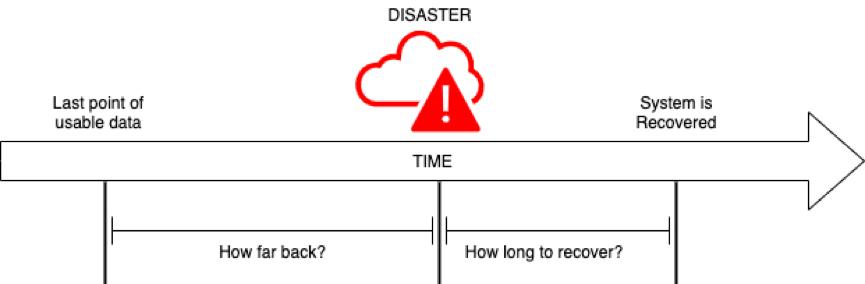
RTO 和 RPO
For different types of failures, the disaster recovery industry has three different levels of defense methods: data level, application level, and service level. At present, the mainstream disaster recovery structure in the industry is still disaster preparedness and disaster recovery, which belongs to the data-level disaster recovery scheme. Because the disaster recovery center does not work normally, the integrity and operation status of the application service are unknown, and it will face the problem of daring to cut at the critical moment of failure.
Some enterprises will not dare to cut because they cannot determine whether they can carry traffic, and some enterprises that decide to switch may not be able to fully restore business because the application state of the standby machine room is not correct, and the final impact is that the RTO or RPO is long, and the reaction to the outside world is a large "downtime" event.
Sourced from Alibaba Practice's AppActive
In 2021, many well-known companies and cloud platforms at home and abroad have serious service interruptions and downtime incidents, which has sounded the alarm for enterprises, and more and more enterprises have put disaster recovery construction on the agenda. While solving disaster recovery problems, many enterprises choose to try to adopt a multi-active disaster recovery approach in order to maintain cost control, support future multi-cloud architecture evolution, and determine disaster recovery.
When a disaster occurs, multi-active disaster recovery can realize minute-level service traffic switching, and users cannot even feel the disaster occurring. There are three typical architectures for different deployment scenarios: the construction of multi-activity applications in the same city under the physical distance of the same city computer room is less than 100 kilometers, the construction of off-site application multi-activity in the scene of the physical distance of the off-site computer room is greater than 300 kilometers, and the construction of hybrid cloud application multi-activity under the scenario of hybrid cloud multi-cloud fusion. In the multi-activity mode, resources are not idle or wasted, and can break through the capacity limit of a single region, so as to obtain cross-regional capacity expansion.
Multi-active disaster recovery has been practiced within Alibaba for many years.
As early as 2007 to 2010, Alibaba adopted the same-city multi-activity architecture to support business capacity and availability.
In 2013, due to the limited capacity of the computer room and the limited power risk of the Hangzhou computer room, Alibaba began to explore the architecture scheme of multi-life in different places, which is the so-called "unitization" that everyone later knew. The unitized architecture completed the pilot verification in 2014, and in 2015, it officially realized three places and four centers thousands of miles away, thus having the ability to multi-activity at the production level in the field, and completed the cut flow in the early morning of double 11 in 2017.
In 2019, Alibaba's system was fully launched to the cloud, and the off-site multi-activity architecture followed the rhythm of the cloud and incubated into AHAS-MSHA, a native product of Alibaba Cloud, serving Alibaba and cloud customers, and helping large enterprises in more than ten different industries such as digital government, logistics, energy, communications, and the Internet to successfully build an application multi-activity architecture, including Cainiao Rural City Application Multi-Activity, China Unicom New Customer Service Off-site Application Multi-Activity, Huitongda Hybrid Cloud Application Multi-Activity, etc.
When interviewing Alibaba Cloud's global highly available technology team, the general feeling is that "there is no unified understanding of multi-activity in the industry, and there is not enough attention." ”
First of all, different people will have different definitions of the word "multi-live", everyone says that they are "multi-live", but when the failure comes, it is found that the current system is not really multi-live. Secondly, some enterprises do not understand the multi-life in different places, and some enterprises that understand it will think that the cost of multi-life in different places is high and difficult to land. Some enterprises, after understanding the "multi-activity", subconsciously want to invest resources in technical pre-research within the enterprise to resist the commercial product input of cloud vendors.
The cognitive bias of "multi-activity" will make users misuse or use it, so as not to enjoy the stability dividend brought by "multi-activity".
In the view of Alibaba Cloud's global high-availability technology team, application multi-activity will become a trend in the field of cloud-native disaster recovery, rather than waiting for the trend to come, it is better to promote the development of application multi-activity through open source. They hope to form a set of technical specifications and standards for application multi-activity through open source collaboration, making application multi-activity technology more easy to use, universal, stable and scalable.
On January 11, 2022, Alibaba Cloud officially open sourced the AHAS-MSHA code and named appActive. (Project address: https://github.com/alibaba/Appactive) This is also the first time in the open source field to propose the concept of "application multi-activity".
AppActive implementation and future planning
Alibaba Cloud also open-sourced its own chaos engineering project ChaosBlade (https://github.com/chaosblade-io/chaosblade) in 2019, which aims to help enterprises solve the problem of high availability in cloud-native processes through chaos engineering. AppActive is more defensive, ChaosBlade is more attacking, and the combination of attack and defense forms a more sound landing safety production mechanism.
AppActive is designed to provide simultaneous external services for multi-site production systems. In order to achieve this goal, there are difficulties in the technical implementation, such as traffic route consistency, data read and write consistency, and multi-active O&M consistency.
To address these challenges, Alibaba Cloud's global highly available technology team has abstracted various technology stacks and defined interface standards.
Zhou Yang introduced that they abstracted AppActive into three parts: application layer, data layer and cloud platform:
The application layer is the main path of the service traffic link, including the access gateway, microservices and message components, the core is to solve the global traffic route consistency problem, through the layer of route error correction to ensure the correctness of traffic routing. Among them, the access gateway, which is at the entrance of the data room traffic, is responsible for the traffic scheduling of layer seven, and corrects the routing error by identifying the service attributes in the traffic and according to certain traffic rules. Microservices and messaging components, in the form of synchronous or asynchronous invocation, ensure that traffic enters the correct machine room for logical processing and data reading and writing through routing error correction, traffic protection, fault isolation, and other capabilities.
The core of the data layer is to solve the problem of data consistency, through data consistency protection, data synchronization, data source switching capabilities to ensure that data is not dirty and has data disaster recovery capabilities.
Cloud platform is the cornerstone of supporting the operation of business applications, because the cloud form may include self-built IDC, multi-cloud, hybrid cloud, heterogeneous chip cloud and other forms, cloud platform disaster recovery requires multi-cloud integration and data interoperability, on this basis to build and have the cloud platform, cloud service PaaS layer disaster recovery capabilities.

6 major catastrophic failures that are dealt with with by the application of multi-activity
AppActive is currently in v0.1, and the open source content includes all the standard interface definitions of the above application layer and data layer on the data plane, and provides the basic implementation based on Nginx, Dubbo, and MySQL. Developers can run and verify the basic functions of multi-activity applications based on their current capabilities.
In the short term, AppActive's planning aligns the application of multi-activity standards to improve the integrity of AppActive, including the following points:
Rich access layer, service layer, data layer plug-ins, support more technical components to the AppActive support list.
Expand the standards and implementations for application multi-activity, such as increasing the standards and implementations for message application multi-activity.
Establish the AppActive control plane to improve the integrity of the Multi-Activity Implementation of appActive applications.
Follow the application of multi-active LRA standard extension to support multi-active forms in the same city.
Extended to support hybrid cloud multi-activity forms following the application multi-active HCA standard.
In the future, Alibaba Cloud will continue to polish AppActive and strive to make it a best practice under the application multi-activity standard to meet the strict requirements of large-scale production and availability, and will also follow the development trend of the cloud, explore distributed clouds, and achieve cross-cloud, cross-platform, and cross-geolocation application multi-activity full-scenario coverage.
With the gradual conclusion of the consensus of "no disaster recovery and no cloud", Alibaba Cloud hopes to help more enterprise application systems build escape capabilities to deal with disaster failures, and also hopes to build multi-active disaster recovery standards with developers in the GitHub community.
Extended Reading:
Alibaba Cloud's Application Multi-Active Technology White Paper:
https://developer.aliyun.com/topic/download?spm=a2c6h.12873639.0.0.5b222e55fukQsa&id=8266