資訊檢索式的方法通常先确定問題的中心實體,繼而生成問題的若幹候選答案,再使用打分、排序等方式找出最适合原問題的答案。這類方法的整體架構比較簡潔,對于簡單問題有較好的效果。
資訊檢索式的方法通常假設問題足夠簡單,大多數系統認為問題中有且僅有一個實體,這個實體被稱作中心實體(Topic Entity),這是使用者輸入自然語言問題的核心,同時假設問題答案在知識圖譜中離中心實體足夠近,例如在離中心實體θ步以内(θ通常取2)。例如問題“What is the budget of Resident Evil? ”的中心實體是Resident Evil,疑問詞是What。對于較複雜的問題,這類方法通常使用啟發式規則和模闆将複雜問題分解成若幹簡單問題,依次處理簡單問題再對各答案集合求交集。
确定中心實體的本質任務是實體識别(Entity Recognition),其目标是檢測出自然語言問題中代表實體的短語,并進一步将這些短語映射到特定的實體上。後一步工作常被稱作實體連接配接(Entity Linking)或者實體消歧。若識别出多個實體,通常選擇其中置信度最高的實體,或依次作為中心實體進行後續步驟。
在确定中心實體後,自然語言問題就在知識圖中有了一個定位。由于問題規模有限,通常假設答案在知識圖中離中心實體的距離足夠近。這樣,一種簡單直覺的方法就是将中心實體θ步之内的鄰居節點都作為候選答案(θ通常取2)。
确定中心實體,以及候選答案後,需要給各候選答案進行評分或排序,進而決定最終的結果。這是基于資訊檢索方式的問答系統重要階段。評分或排序的方法包括基于特征抽取的方法[3],也包括基于深度學習的Graph Embedding的方法[4]。
用來計算答案最終得分的特征多種多樣,這些特征通常從實體、關系和答案三個角度出發。與實體相關的特征主要包括實體連結的置信度,實體的表征短語和實體之間的單詞重疊數等。與關系相關的特征主要包括關系抽取的置信度,關系兩側可以接受的類型等。與答案相關的特征主要包括答案的數目、答案的類型等。除此之外,不同的問答系統還可能考慮各自獨有的特征。在計算出候選答案的特征之後,需要使用某種排序模型進行排序,以選擇最合适的結果。排序學習(Learningto Rank)在資訊抽取(Information Retrieval)領域中已經受到廣泛關注和系統研究[14],主要分為單文檔方法(PointWise Approach)、文檔對方法(PairWise Approach)和文檔清單方法(ListWise Approach)。其中文檔對方法将排序問題轉化為分類問題,在KB-QA任務中的表現較好,一些較成熟的算法可以直接使用,例如SVM-rank[15]。
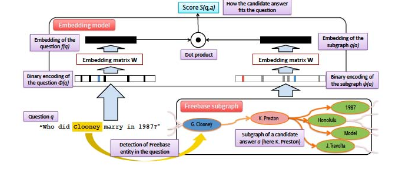
另一方面,一些系統利用神經網絡和各類Embedding的方法,直接評價候選答案與原問題之間的比對程度。文獻[1]将候選答案和原問題分别向量化,再使用多通道卷積神經網絡(MCCNN)計算候選答案與原問題之間的相似度。文獻[2]将候選實體生成與關系抽取(Relation Extraction)結合起來,利用原問題的上下文資訊,使用卷積神經網絡為候選實體對應的關系進行打分。文獻[4]将候選答案周圍的邊和節點一同作為子圖進行Embedding,再與原問題的向量做點乘作為得分(如圖2所示)。
![吳恩達logistic回歸實作[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)