5月24日,在新版本alphago首戰以1/4子微弱優勢戰勝中國圍棋職業九段棋手柯潔之後,“alphago之父”deepmind創始人兼ceo demis hassabis、alphago團隊負責人david silver在人工智能高峰論壇上詳解了alphago的研發并就“alphago意味着什麼?”的問題進行了詳細解答。
“alphago已經展示出了創造力,也已經可以模仿人類直覺了。在過去一年,我們繼續打造alphago,我們想打造完美的alphago,彌補它知識方面的空白。因為在與李世石的比賽中,它是有缺陷的。”demis hassabis說:“在未來我們能看到人機合作的巨大力量,人類智慧将通過人工智能進一步放大。強人工智能是人類研究和探尋宇宙的終極工具。”
為什麼計算機下圍棋非常困難?
demis hassabis坦言圍棋非常困難,因為其複雜程度讓窮舉搜尋都難以解決。對于計算機來說,圍棋有兩項難題:“不可能”寫出評估程式以決定誰赢,搜尋空間太過龐大。
圍棋不像象棋等遊戲靠計算,而是靠直覺。圍棋中沒有等級概念,所有棋子都一樣。圍棋是築防遊戲,是以需要盤算未來。小小一子可撼全局,“妙手”如受天啟。
alphago如何進行訓練?
david silver從技術角度詳細解釋了alphago如何進行訓練。
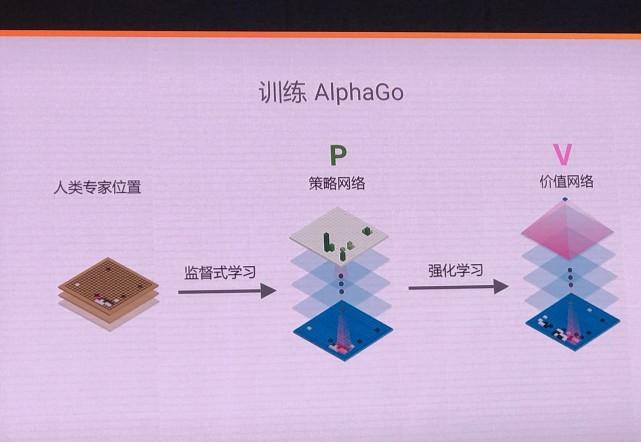
圍棋對于機器的難點之一是評估程式的撰寫。而alphago團隊用兩種卷積神經網絡去完成:政策網絡和估值網絡。政策網絡的卷積神經網絡用于決定下一步落子可能的位置,價值網絡用于評估目前棋局獲勝的機率。
為了應對圍棋的巨大複雜性,alphago 采用機器學習技術,結合了監督學習和強化學習的優勢。通過訓練形成一個政策網絡(policy network),将棋盤上的局勢作為輸入資訊,并對所有可行的落子位置生成一個機率分布。
然後,訓練出一個價值網絡(value network)對自我對弈進行預測,以 -1(對手的絕對勝利)到1(alphago的絕對勝利)的标準,預測所有可行落子位置的結果。這兩個網絡自身都十分強大,而 alphago将這兩種網絡整合進基于機率的蒙特卡羅樹搜尋(mcts)中,實作了它真正的優勢。
最後,新版的alphago 産生大量自我對弈棋局,為下一代版本提供了訓練資料,此過程循環往複。

alphago 如何決定落子?
在擷取棋局資訊後,alphago會根據政策網絡探索哪個位置同時具備高潛在價值和高可能性,進而決定最佳落子位置。在配置設定的搜尋時間結束時,模拟過程中被系統最頻繁考察的位置将成為 alphago的最終選擇。在經過先期的全盤探索和過程中對最佳落子的不斷揣摩後,alphago的搜尋算法就能在其計算能力之上加入近似人類的直覺判斷。
david silver總結:政策網絡減少寬度,價值網絡減少深度。alphago做出多種模拟,不斷反複,最終形成判斷哪種方案是獲勝機率最高的。
今年的alphago和去年的alphago有什麼差別?
david silver透露,去年的alphago lee在雲上有50tpus在運作,搜尋50個棋步為10000個位置/秒。而今年的alphago master是在單個tpu機器上進行遊戲,它已經成為了自己的老師,從自己的搜尋裡學習,擁有更強大的政策網絡和價值網絡。
alphago如何進行自我學習?
demis hassabis将alphago歸類為強人工智能,強人工智能和弱人工智能的差別在于弱人工智能是預設定的,例如ibm的“深藍”就不能自我學習。
他提到強化學習架構的概念:智能體有一個特定目标要完成,它有兩種方式和環境打交道,一是觀察,智能體通過觀察進行見面,這有可能不全面。二是行動。
david silver稱,alphago先自己與自己對弈,政策網絡以p預測alphago的移動。
人工智能的元解決方案
demis hassabis表示,目前資訊過載和系統冗雜是人類面臨的巨大挑戰。開發人工智能技術可能是這些問題的元解決方案。元解決方案的目标是實作“人工智能科學家”或“人工智能輔助科學”。“人工智能和所有強大的新技術一樣,在倫理和責任的限制中造福人類。
原文釋出時間為:2017年5月24日
本文來自雲栖社群合作夥伴至頂網,了解相關資訊可以關注至頂網。