1.开局扯犊子
最近正在学习Java爬虫技术,于是乎接触到了jsoup这个东西。
继爬取美女图片后的第二个小项目,爬取笔趣阁小说,
2.页面分析
首先我们进入笔趣阁选择一本喜欢的小说,f12后拿到他的title与每一章的地址。
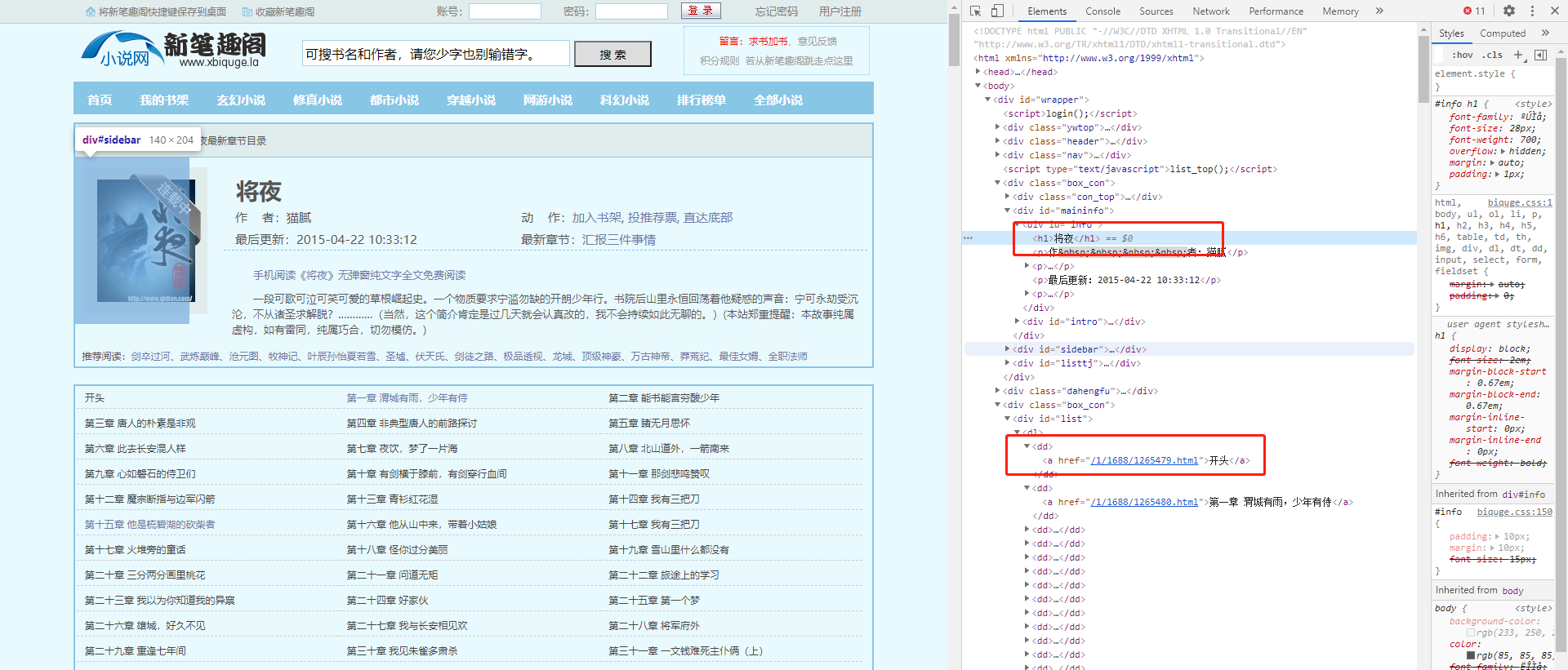
然后我们继续分析进入章节后的内容

在这我们可以拿到每一章里面的 标题 内容 以及下一章的地址
3.代码实现
经过我这一通严谨的分析。我们已经知道大致的一个页面布局,接下来就是我们的一个代码实现了
public class ArticleSpider {
/**
* 保存地址
*/
private String path ;
/**
* 启动
*/
public void start(String url){
try {
Document document = Jsoup.connect(url).get();
//拿到列表第一个连接
String listUrl = document.select("#list>dl>dd>a").attr("abs:href");
String fileName = document.select("h1").text();
//文件保存地址,这里我根据书名做为文件夹
path = "D:/novel/" + fileName;
each(listUrl);
}catch (Exception e){
e.printStackTrace();
}
}
/**
* 遍历获取每一章的数据
*/
private void each(String url){
try{
Document document = Jsoup.connect(url).get();
//拿到小说信息及进行换行处理
Element elm = document.getElementById("content");
String content = elm.text().replaceAll(" ", "\n").replaceAll("。","。\n");
String title = document.getElementsByTag("h1").text();
//下一章地址
String next = document.getElementsByClass("bottem1").get(0).child(3).attr("abs:href");
//创建文件
File file = createFile(title);
mergeBook(file,content);
//判断是否到最后一章
if(next.indexOf("html") != -1){
//我们学习为主 要做爬取限制 不要干扰人正常运营
Thread.sleep(5000);
System.out.println("休息5秒继续爬");
each(next);
}
}catch (Exception e){
e.printStackTrace();
}
}
/**
* 创建文件
*/
public File createFile(String fileName) {
//创建空白文件夹:networkNovel
File file = new File( path +"/"+ fileName + ".txt");
try {
//获取父目录
File fileParent = file.getParentFile();
if (!fileParent.exists()) {
fileParent.mkdirs();
}
//创建文件
if (!file.exists()) {
file.createNewFile();
}
} catch (Exception e) {
file = null;
System.err.println("新建文件操作出错");
e.printStackTrace();
}
return file;
}
/**
* 写入文本
*/
public void mergeBook(File file, String content) {
//字符流
try {
FileWriter resultFile = new FileWriter(file, true);//true,则追加写入
PrintWriter myFile = new PrintWriter(resultFile);
//写入
myFile.println(content);
myFile.println("\n");
myFile.close();
resultFile.close();
} catch (Exception e) {
System.err.println("写入操作出错");
e.printStackTrace();
}
}
}
还有用来储存标题和内容的实体类
@Data
public class NovelAttribute {
//标题
private String title;
//内容
private String content;
private String url;
public NovelAttribute(String title, String content) {
this.title = title;
this.content = content;
}
}
最后启动
public static void main(String[] args){
ArticleSpider articleSpider = new ArticleSpider();
//传入你喜欢的小说的地址
articleSpider.start("https://www.xbiquge.la/1/1688/");
}
4.运行效果
5.总结
爬小说的步骤就是这些了,挺简单的。后续有时间我会研究研究爬取音乐的方法。
如果此文章帮到了你,不妨点个赞 <_>