1.開局扯犢子
最近正在學習Java爬蟲技術,于是乎接觸到了jsoup這個東西。
繼爬取美女圖檔後的第二個小項目,爬取筆趣閣小說,
2.頁面分析
首先我們進入筆趣閣選擇一本喜歡的小說,f12後拿到他的title與每一章的位址。
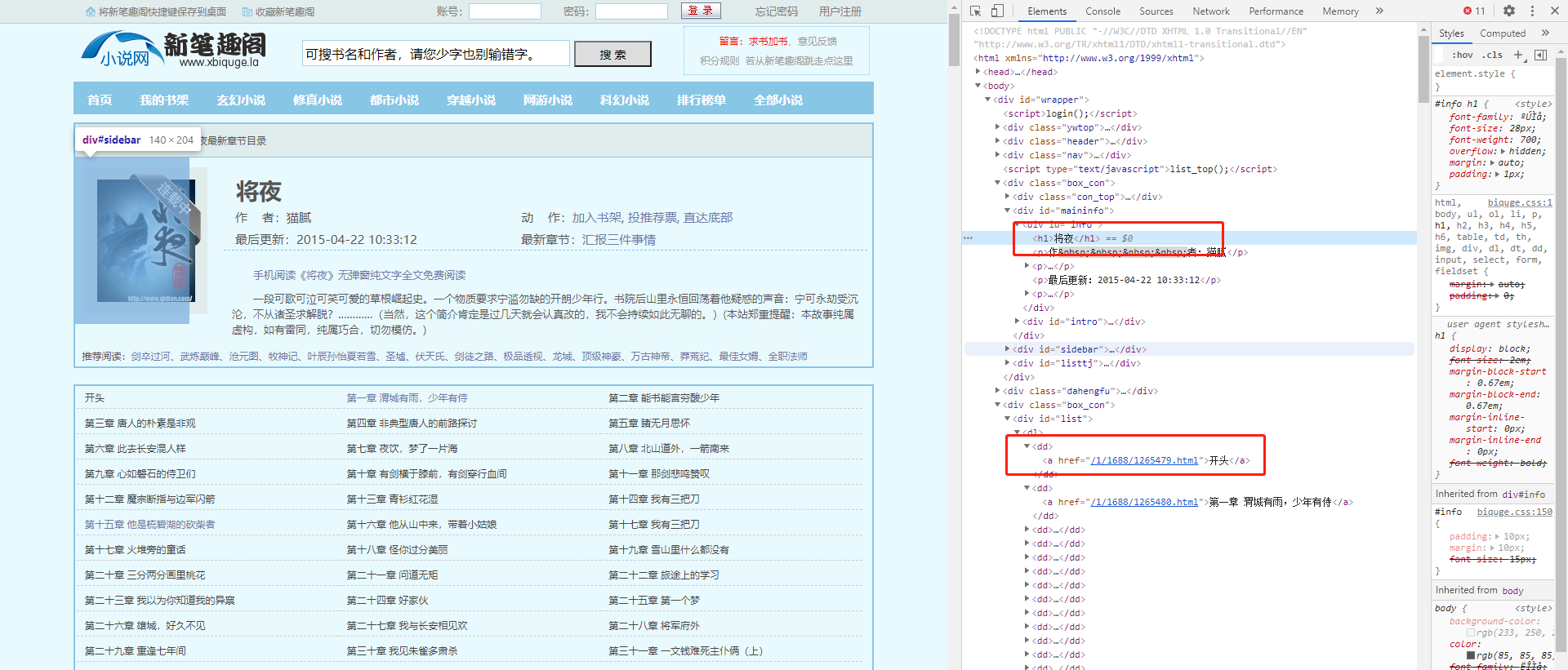
然後我們繼續分析進入章節後的内容

在這我們可以拿到每一章裡面的 标題 内容 以及下一章的位址
3.代碼實作
經過我這一通嚴謹的分析。我們已經知道大緻的一個頁面布局,接下來就是我們的一個代碼實作了
public class ArticleSpider {
/**
* 儲存位址
*/
private String path ;
/**
* 啟動
*/
public void start(String url){
try {
Document document = Jsoup.connect(url).get();
//拿到清單第一個連接配接
String listUrl = document.select("#list>dl>dd>a").attr("abs:href");
String fileName = document.select("h1").text();
//檔案儲存位址,這裡我根據書名做為檔案夾
path = "D:/novel/" + fileName;
each(listUrl);
}catch (Exception e){
e.printStackTrace();
}
}
/**
* 周遊擷取每一章的資料
*/
private void each(String url){
try{
Document document = Jsoup.connect(url).get();
//拿到小說資訊及進行換行處理
Element elm = document.getElementById("content");
String content = elm.text().replaceAll(" ", "\n").replaceAll("。","。\n");
String title = document.getElementsByTag("h1").text();
//下一章位址
String next = document.getElementsByClass("bottem1").get(0).child(3).attr("abs:href");
//建立檔案
File file = createFile(title);
mergeBook(file,content);
//判斷是否到最後一章
if(next.indexOf("html") != -1){
//我們學習為主 要做爬取限制 不要幹擾人正常營運
Thread.sleep(5000);
System.out.println("休息5秒繼續爬");
each(next);
}
}catch (Exception e){
e.printStackTrace();
}
}
/**
* 建立檔案
*/
public File createFile(String fileName) {
//建立空白檔案夾:networkNovel
File file = new File( path +"/"+ fileName + ".txt");
try {
//擷取父目錄
File fileParent = file.getParentFile();
if (!fileParent.exists()) {
fileParent.mkdirs();
}
//建立檔案
if (!file.exists()) {
file.createNewFile();
}
} catch (Exception e) {
file = null;
System.err.println("建立檔案操作出錯");
e.printStackTrace();
}
return file;
}
/**
* 寫入文本
*/
public void mergeBook(File file, String content) {
//字元流
try {
FileWriter resultFile = new FileWriter(file, true);//true,則追加寫入
PrintWriter myFile = new PrintWriter(resultFile);
//寫入
myFile.println(content);
myFile.println("\n");
myFile.close();
resultFile.close();
} catch (Exception e) {
System.err.println("寫入操作出錯");
e.printStackTrace();
}
}
}
還有用來儲存标題和内容的實體類
@Data
public class NovelAttribute {
//标題
private String title;
//内容
private String content;
private String url;
public NovelAttribute(String title, String content) {
this.title = title;
this.content = content;
}
}
最後啟動
public static void main(String[] args){
ArticleSpider articleSpider = new ArticleSpider();
//傳入你喜歡的小說的位址
articleSpider.start("https://www.xbiquge.la/1/1688/");
}
4.運作效果
5.總結
爬小說的步驟就是這些了,挺簡單的。後續有時間我會研究研究爬取音樂的方法。
如果此文章幫到了你,不妨點個贊 <_>