Selected from IEEE Spectrum
Author: ELIZA STRICKLAND
Machine Heart Compilation
Machine Heart Editorial Department
Is the current AI conscious? How to define consciousness? Is AI moving forward to improving supervised learning through better data labeling, or is it a strong push for self-supervised/unsupervised learning? In a recent interview with IEEE Spectrum, Turing Award-winning Chief AI Scientist Yann LeCun expressed his opinion.
In his speech, Yann LeCun once played a famous painting from the French Revolution, "Freedom Leads the People", with the caption: "The revolution will not be supervised"
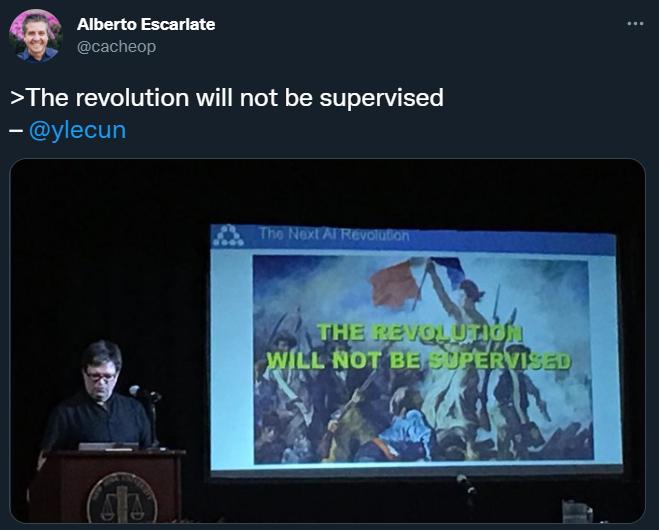
LeCun believes that when AI systems no longer need supervised learning, the next AI revolution will come. At that point, these systems will no longer rely on carefully labeled datasets. AI systems need to learn as little as possible from humans.
In a recent interview with IEEE Spectrum, he talked about how self-supervised learning can create powerful AI systems with common sense. At the same time, he also expressed his views on some recent community remarks, such as Ng's embrace of "data-centric AI" and Ilya Sutskever, chief scientist of OpenAI, speculating that current AI may be conscious.
Here's what the interviews are:
Q: You've said that the limitations of supervised learning are sometimes mistaken for the limitations of deep learning itself, so which limitations can be overcome by self-supervised learning
A: Supervised learning is ideal for well-defined domains where you can collect a lot of labeled data and the type of input the model sees during deployment is not much different from the input type used during training. Collecting large amounts of unbiased labeled data is very difficult. Bias here does not necessarily refer to social bias, but can be understood as correlation between data that the system should not use. For example, when you're training a system that recognizes cattle, and all the samples are cows on the grass, the system uses the grass as a context cue for identifying cattle. That way, if you give it a picture of a cow on the beach, it may not recognize it.
Self-supervised learning (SSL) allows the system to learn a good representation of input in a task-independent manner. Because SSL training uses unlabeled data, we can use very large training sets and let the system learn a more robust, complete representation of inputs. Then, using a small amount of annotation data, it can achieve good performance on supervision tasks. This greatly reduces the amount of labeled data required for purely supervised learning and makes the system more robust and capable of handling inputs that differ from labeled training samples. Sometimes, it also reduces the system's sensitivity to data bias.
In the direction of practical AI systems, we are moving towards a larger architecture that is pre-trained on large amounts of unlabeled data with SSL. These systems can be used for a wide variety of tasks, such as using a neural network to process translations in hundreds of languages, constructing multilingual speech recognition systems, and so on. These systems can handle languages where data is difficult to obtain.
Q: Other leaders say ai is moving forward to improving supervised learning through better data labeling. Ng recently talked about data-centric AI, and NVIDIA's Rev Lebaredian talked about synthetic data with all the labels. Is there any disagreement in the industry on the path of AI?
A: I don't think there is a difference of ideas. In NLP, SSL pre-training is a very standard practice. It has shown excellent performance gains in speech recognition and is becoming increasingly useful in terms of vision. However, there are still many unexplored applications of "classical" supervised learning, so whenever possible, one should of course use synthetic data in supervised learning. Even so, Nvidia is actively developing SSL.
Back in the 000s, Geoff Hinton, Yoshua Bengio, and I were convinced that the only way to train larger, deeper neural networks was through self-supervised (or unsupervised) learning. It was also at this time that Ng became interested in deep learning. His work at the time also focused on what we now call the method of self-supervision.
Q: How to build an AI system with common sense based on self-supervised learning? How far can common sense allow us to go in constructing intelligence at the level of human intelligence?
A: I think ai is going to make significant progress once we figure out how to make machines learn how the world works like humans and animals. Therefore, artificial intelligence must learn to observe the world and act in it. Humans understand how the world works because they have learned the internal models of the world that allow us to fill in missing information, predict what is going to happen, and predict the impact of our actions. Our model of the world enables us to perceive, interpret, reason, plan and act ahead.
So the question is: How do machines learn the world model?
This can be broken down into two questions:
First, what learning paradigm should we use to train world models?
Second, what architecture should the world model use?
For the first question, my answer is self-supervised learning (SSL). For example, let the machine watch the video and pause it, and then let the machine learning video characterize what happens next. In the process, machines can learn a great deal of background knowledge about how the world works, which may be similar to how babies and animals learn during the first weeks or months of life.
My answer to the second question is a new type of macro-architecture, which I call hierarchical joint embedding predictive architecture (H-JEPA). It is difficult to explain in detail here, taking the above prediction video as an example, JEPA does not predict the future frame of the video clip, but learns the abstract representation and future of the video clip so that it can easily predict the latter based on the understanding of the former. This can be achieved by some recent advances using non-contrasting SSL methods, especially one called VICReg that we recently proposed.
Q: A few weeks ago, you responded to a tweet from Ilya Sutskever, Chief Scientist at OpenAI. He speculated that there might be some consciousness in today's large neural networks, and then you dismissed this view outright. So in your opinion, what does it take to build a conscious neural network? What would a conscious system look like?
A: First of all, consciousness is a very vague concept. Some philosophers, neuroscientists, and cognitive scientists think it's just an illusion, and I agree with that view.
I have a conjecture about the illusion of consciousness. My hypothesis is that we have a world model "engine" in the prefrontal cortex of our brains. The world model can be configured according to the actual situation faced. For example, the helmsman of a sailing ship simulates the air and water flow around the ship with a world model; for example, if we build a wooden table, the world model imagines the result of cutting wood and assembling it... We need a module in our brain, which I call a configurator, that sets goals and sub-goals for us, configures our world model to simulate the real situation at the moment, and starts our perceptual system to extract relevant information and discard the rest. The presence of a supervised configurator may be what gives us the illusion of consciousness. But here's the interesting thing: we need this configurator because we only have one world model engine. If our brains are large enough to accommodate many models of the world, we don't need consciousness. So, in this sense, consciousness is the result of the limitations of our brains!
Q: What role will self-supervised learning play in the metaverse?
A: There are many specific applications of deep learning in the metaverse, such as motion tracking for VR and AR, capturing and synthesizing body movements, and facial expressions.
New and innovative AI-driven tools provide a vast creative space for everyone to create new things in the metaverse and the real world. But the metaverse also has an "AI-complete" application: a virtual AI assistant. We should have virtual AI assistants that can help us in our daily lives, answer any questions we may have, and help us process the massive amounts of information we have on a daily basis. To this end, AI systems need to have a certain understanding of how the world (including the physical world and the virtual world of the metacosm) works, have a certain ability to reason and plan, and master a certain degree of common sense. In short, we need to figure out how to build autonomous AI systems that can learn like humans. This will take time, and Meta has been preparing for this for a long time.
![Light of the post-00s: This app developed by 4 high school students has allowed the visually impaired to regain their freedom of travel[fig]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)