選自IEEE Spectrum
作者:ELIZA STRICKLAND
機器之心編譯
機器之心編輯部
現在的 AI 到底有沒有意識?如何定義意識?AI 的前進方向是通過更好的資料标簽來改善監督學習,還是大力發展自監督 / 無監督學習?在 IEEE Spectrum 的最近的一次訪談中,圖靈獎得主、Meta 首席 AI 科學家 Yann LeCun 表達了自己的看法。
Yann LeCun 在演講時曾經放過一張法國大革命時期的著名畫作《自由引導人民》,并配文:「這場革命将是無監督的(THE REVOLUTION WILL NOT BE SUPERVISED)」。
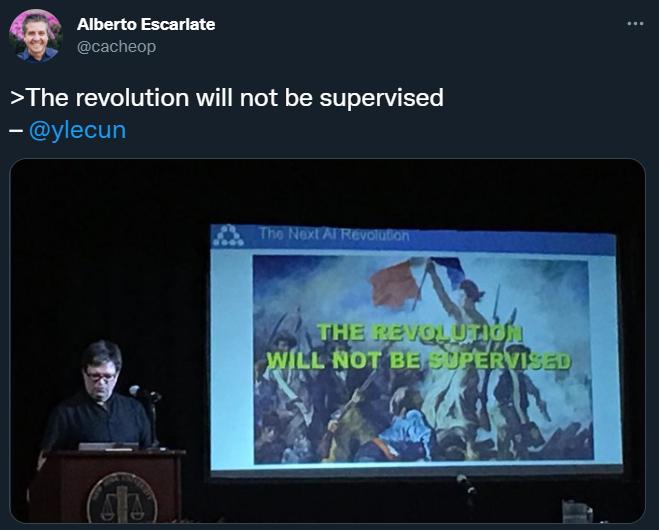
LeCun 相信,當 AI 系統不再需要監督學習時,下一次 AI 革命就會到來。屆時,這些系統将不再依賴于精心标注的資料集。他表示,AI 系統需要在學習時盡可能少得從人類這裡擷取幫助。
在最近接受 IEEE Spectrum 的訪談時,他談到了自監督學習如何能夠創造具備常識的強大人工智能系統。同時,他也對最近的一些社群言論發表了自己的看法,比如吳恩達對「以資料為中心的 AI」的擁護、 OpenAI 首席科學家 Ilya Sutskever 對于目前 AI 可能具備意識的推測等。
以下是訪談内容:
Q:您曾經說過,監督學習的限制有時會被誤以為是深度學習自身的局限性所緻,那麼哪些限制可以通過自監督學習來克服
A:監督學習非常适用于邊界清晰的領域,在這類領域中,你可以收集大量标記資料,而且模型在部署期間看到的輸入類型和訓練時使用的輸入類型差别不大。收集大量不帶偏見的标記資料是非常困難的。這裡的偏見不一定是指社會偏見,可以了解為系統不該使用的資料之間的相關性。舉個例子,當你在訓練一個識别牛的系統時,所有的樣本都是草地上的牛,那麼系統就會将草作為識别牛的上下文線索。如此一來,如果你給它一張沙灘上的牛的照片,它可能就認不出來了。
自監督學習(SSL)可以讓系統以獨立于任務的方式學習輸入的良好表示。因為 SSL 訓練使用的是未标注的資料,是以我們可以使用非常大的訓練集,并讓系統學習更加穩健、完整的輸入表示。然後,再利用少量的标注資料,它就可以在監督任務上達到良好的性能。這大大減少了純監督學習所需的标記資料量,并使系統更加穩健、更能夠處理與标注訓練樣本不同的輸入。有時,它還會降低系統對資料偏見的敏感性。
在實用 AI 系統這一方向,我們正朝着更大的架構邁進,即用 SSL 在大量未标注資料上進行預訓練。這些系統可以用于各種各樣的任務,比如用一個神經網絡處理數百種語言的翻譯,構造多語言語音識别系統等。這些系統可以處理資料難以擷取的語言。
Q:其他領軍人物表示,AI 的前進方向是通過更好的資料标簽來改善監督學習。吳恩達最近談到了以資料為中心的 AI,英偉達的 Rev Lebaredian 談到了帶有所有标簽的合成資料。在 AI 的發展路徑方面,業界是否存在分歧?
A:我不認為存在思想上的分歧。在 NLP 中,SSL 預訓練是非常标準的實踐。它在語音識别方面表現出了卓越的性能提升,在視覺方面也變得越來越有用。然而,「經典的」監督學習仍有許多未經探索的應用,是以隻要有可能,人們當然應該在監督學習中使用合成資料。即便如此,英偉達也在積極開發 SSL。
早在零幾年的時候,Geoff Hinton、Yoshua Bengio 和我就确信,訓練更大、更深的神經網絡的唯一方法就是通過自監督(或無監督)學習。也是從這時起,吳恩達開始對深度學習感興趣。他當時的工作也集中在我們現在稱之為自監督的方法上。
Q:如何基于自監督學習建構具有常識的人工智能系統?常識能讓我們在構造人類智能水準的智能上走多遠?
A:我認為,一旦我們弄清楚如何讓機器像人類和動物一樣學習世界是如何運作的,人工智能必将會取得重大進展。是以人工智能要學會觀察世界,并在其中采取行動。人類了解世界是如何運作的,是因為人類已經了解了世界的内部模型,使得我們能夠填補缺失的資訊,預測将要發生的事情,并預測我們行動的影響。我們的世界模型使我們能夠感覺、解釋、推理、提前規劃和行動。
那麼問題來了:機器如何學習世界模型?
這可以分解為兩個問題:
第一,我們應該使用什麼樣的學習範式來訓練世界模型?
第二,世界模型應該使用什麼樣的架構?
對于第一個問題,我的答案是自監督學習(SSL)。舉個例子,讓機器觀看視訊并暫停視訊,然後讓機器學習視訊中接下來發生事情的表征。在這個過程中,機器可以學習大量關于世界如何運作的背景知識,這可能類似于嬰兒和動物在生命最初的幾周或幾個月内的學習方式。
對于第二個問題,我的答案是一種新型的深度宏架構(macro-architecture),我稱之為分層聯合嵌入預測架構(H-JEPA)。這裡很難詳細解釋,以上述預測視訊為例,JEPA 不是預測視訊 clip 的未來幀,而是學習視訊 clip 的抽象表征和未來,以便能很容易地基于對前者的了解預測後者。這可以通過使用非對比 SSL 方法的一些最新進展來實作,特别是我們最近提出的一種稱為 VICReg 的方法。
Q:幾周前,您回複了 OpenAI 首席科學家 Ilya Sutskever 的一條推文。他推測當今的大型神經網絡可能存在一些意識,随後您直接否定了這種觀點。那麼在您看來,建構一個有意識的神經網絡需要什麼?有意識的系統會是什麼樣子?
A:首先,意識是一個非常模糊的概念。一些哲學家、神經科學家和認知科學家認為這隻是一種錯覺(illusion),我非常認同這種觀點。
我有一個關于意識錯覺的猜想。我的假設是:我們的腦前額葉皮質中有一個世界模型「引擎」。該世界模型可根據實際面對的情況進行配置。例如帆船的舵手用世界模型模拟了船周圍的空氣和水流;再比如我們要建一張木桌,世界模型就會想象切割木頭群組裝它們的結果...... 我們的大腦中需要一個子產品,我稱之為配置器(configurator),它為我們設定目标和子目标,配置我們的世界模型以模拟當下實際的情況,并啟動我們的感覺系統以提取相關資訊并丢棄其餘資訊。監督配置器的存在可能是讓我們産生意識錯覺的原因。但有趣的是:我們需要這個配置器,因為我們隻有一個世界模型引擎。如果我們的大腦足夠大,可以容納許多世界模型,我們就不需要意識。是以,從這個意義上說,意識是我們大腦存在局限的結果!
Q:在元宇宙中,自監督學習将扮演一個什麼樣的角色?
A:元宇宙中有很多深度學習的具體應用,例如用于 VR 和 AR 的運動跟蹤、捕捉和合成身體運動及面部表情等。
人工智能驅動的新型創新工具提供了廣闊的創造空間,讓每個人都能在元宇宙和現實世界中創造新事物。但元宇宙也有一個「AI-complete」應用程式:虛拟 AI 助手。我們應該擁有虛拟 AI 助手,他們可以在日常生活中為我們提供幫助,回答我們的任何問題,并幫助我們處理日常的海量資訊。為此,人工智能系統需要對世界(包括實體世界和元宇宙的虛拟世界)如何運作有一定的了解,有一定的推理和規劃能力,并掌握一定程度的常識。簡而言之,我們需要弄清楚如何建構可以像人類一樣學習的自主人工智能系統。這需要時間,而 Meta 已為此準備良久。
![OpenAI o1與人工智能的過去與未來[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)