Selected from arXiv
Author: Valerii Likhosherstov et al
Machine Heart Compilation
Editor: Du Wei
Transformer is really versatile.
Transformers is a flexible neural end-to-end model family designed for natural language processing tasks. Recently, Transformers has been applied to a range of perceptual tasks such as image classification, video and audio. While recent progress has been made in different areas and tasks, the current SOTA approach can only train a single model with different parameters for each task at hand.
Recently, Google Research, the University of Cambridge and Alain Several researchers at the Turing Institute proposed a simple and efficient way to train a single unified model in their paper PolyViT: Co-training Vision Transformers on Images, Videos and Audio, which they named PolyViT, which achieves competitive or SOTA image, video and audio classification results.
In terms of design, researchers not only use a common architecture for different modes, but also share model parameters across different tasks and modes, enabling potential synergies. Technically, their approach is inspired by the fact that transformer is a universal architecture capable of running on any modality that can tokenized; intuitively, it is because human perception is multimodal in nature and executed by a single brain.
Address of the paper: https://arxiv.org/abs/2111.12993
Figure 1 below provides an overview of the structure of PolyViT.
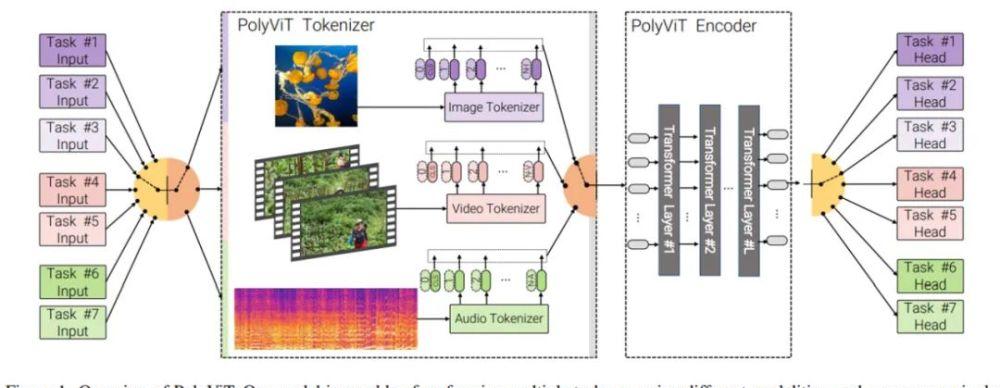
The main method used by researchers is co-training, that is, training a single model on multiple classification tasks at the same time(perhaps across multiple modes). They considered different settings and solved up to 9 different image, video, and audio classification tasks simultaneously. As shown in Figure 1 above, the PolyViT model is capable of performing multiple tasks, but only one task at a time for a given input. While similar approaches have been explored in the fields of computer vision and natural language, it is unclear whether previous work has taken into account multiple modes and whether SOTA results have been achieved using this approach.
Our collaborative training setup is simple and practical. It doesn't require hyperparameter tuning for each combination of collaborative training datasets, as we can easily adjust the setup for standard single-task training. In addition, collaborative training does not increase the overall training cost because the total number of training steps does not exceed the sum of each single-task baseline.
Co-training ViT on images, audio, and video
PolyViT architecture
PolyViT is a single architecture capable of handling inputs from multiple modes. As shown in Figure 1 above, the researchers share a transformer encoder across different tasks and modes, so that the parameters decrease linearly with the number of tasks. Note that polyViTs with L layers behave like L-layer ViTs when working with images, like L-layer AST when processing audio, and uninactorized ViViTs in L-layers when processing video. Although PolyViT is capable of handling multiple modes, only one task can be performed based on one mode given forward transfer.
PolyViT deploys modal-specific class tokens, that is, input embedding operators and position embeddings. This allows the network to encode modal-specific information that can be exploited by subsequent, shared transformer backbones.
To increase model capacity while enabling a large number of tasks and modal co-training, researchers can optionally incorporate L_adapt ≥ 0 modal-specific transformer layers (which they represent as modal-adapter layers) that are applied directly after tokenization. In this case, all modalities and tasks share the L_=shared=L L_adapt layer.
Collaborative training process
In all tasks co-trained using stochastic gradient descent (SGD), the researchers simultaneously optimized all PolyViT model parameters θ. Therefore, there are many design choices when deciding how to build the training batch, calculating gradients to update model parameters, and which training hyperparameters to use.
In all cases, the researchers used examples from a single task to build their own training minibatch. This design choice allowed them to evaluate gradients and update parameters when using the same training hyperparameters such as learning rate, batch size, and momentum as a baseline for a traditional single task. This way, researchers can perform collaborative training on multiple tasks without any additional hyperparameters compared to a single task baseline, making collaborative training easy to perform in practice and reducing the need to perform large-scale hyperparameter sweeps to achieve competitive accuracy.
During collaborative training, for each SGD step, the investigator samples a task (or dataset) and then samples a minibatch from that task, evaluates the gradient, and then performs parameter updates. What needs to be important to consider is the order of the sampling tasks and whether gradients accumulate on different minibatches and tasks. The researchers describe several task sampling plans in Figure 2 below, including the following:
Task-by-task
Task 2: Alternating
Task 3: Uniform task sampling
Task 4: Weighted task sampling
Task 5: Accumulating gradients

experiment
The researchers trained PolyViT simultaneously on nine different classification tasks in three modes: image, audio, and video. For image classification co-training, they used the ImageNet-1K, CIFAR-10/100, Oxford-IIIT Pets, and RESISC45 datasets; for video tasks, they used kinetics 400 and Moments in Time datasets; and for audio tasks, they used AudioSet and VGGSound datasets.
Table 6 below sets up specific experiments:
Table 1 below shows the effect of different task sampling plans on co-training performance on different modes and tasks, with bold for the highest accuracy and underscores for the highest accuracy. Among them, the "Task-by-task" sampling plan performed poorly, achieving good performance on only one task, which was caused by catastrophic forgetting.
The "Accumulated" sampling scheme requires a single learning rate on all tasks, due to the cumulative gradient on all tasks being used to perform parameter updates. Therefore, the program only performs well on image datasets.
The "Alternating", "Uniform", and "Weighted" sampling schemes performed best, indicating that task-specific learning rates and transitions between gradient updates for different tasks are critical to accuracy.
Collaborative training using PolyViT
Table 2 below shows the model training methods for solving nine different tasks across the three modes of image, audio, and video, including the ViT-Im21K Linear probe, Single-task baseline, and the PolyViT and variants of this article (PolyViT L_adapt = 0 and PolyViT Ladapt = L/2, respectively).
The results showed that PolyViTs trained on single-mode achieved SOTA performance on 7 of the 9 datasets, with a negligible difference of 0.3% in accuracy on the remaining 2 datasets. In addition, the total number of parameters is 2/3 less than the baseline for a single task. At the same time, multimodal PolyViT achieves competitive performance with much less parameters in use.
Use the linear probe to evaluate the learned representation
By simply adding and training a new linear head for a new task, the researchers evaluate the feature representations learned by PolyViT. Table 3 below shows how PolyViTs trained on multiple modes learn to perform well on 11 linear evaluation tasks across image, audio, and video modes. Table 3 also shows how collaborative training on multiple modes can be beneficial for learning powerful, transferable, and feature representations that can be used for multiple downstream tasks.
Achieve SOTA performance using single-mode co-training
Inspired by the performance of single-mode collaborative training in Table 2 above, the researchers used this method to perform large-scale collaborative training experiments on audio and video classification tasks. Table 4 and Table 5 show that they implemented SOTA results while using significantly fewer parameters.
As shown in Table 4 below, for audio classification, the researchers compared PolyViT with the current SOTA method MBT (audio-only) and related variants MBT: AS-500kVGGSound and MBT: VGGSoundAS-500k. The results show that PolyViT surpasses the SOTA method on both datasets, using about half the parameters of MBT (audio-only). In addition, PolyViT achieved a 2.8% Improvement in Top 1 accuracy on the smaller dataset VGGSound.
For video classification, the researchers collaboratively trained PolyViT-Large models with smaller tubelet sizes on kinetics-400, Kinetics-600, and Moments in Time datasets and compared them to the current SOTA model ViViT (using the same initialization, backbone, and token count). The results, shown in Table 5 below, show that PolyViT outperforms ViViT on all three datasets.