選自arXiv
作者:Valerii Likhosherstov等
機器之心編譯
編輯:杜偉
Transformer 真的很全能。
Transformers 是一個靈活的神經端到端模型族(family),最開始是為自然語言處理任務設計的。近來,Transformers 已經在圖像分類、視訊和音頻等一系列感覺任務上得到應用。雖然近來在不同領域和任務上取得了進展,但目前 SOTA 方法隻能為手頭的每個任務訓練具有不同參數的單一模型。
近日,谷歌研究院、劍橋大學和阿蘭 · 圖靈研究所的幾位研究者在其論文《 PolyViT: Co-training Vision Transformers on Images, Videos and Audio 》提出了一種簡單高效的訓練單個統一模型的方法,他們将該模型命名為 PolyViT,它實作了有競争力或 SOTA 的圖像、視訊和音頻分類結果。
在設計上,研究者不僅為不同的模态使用一個通用架構,還在不同的任務和模态中共享模型參數,進而實作了潛在協同作用。從技術上來講,他們的方法受到了「transformer 是能夠在任何可以 tokenized 的模态上運作的通用架構」這一事實的啟發;從直覺上來講,是由于人類感覺在本質上是多模态的,并由單個大腦執行。
論文位址:https://arxiv.org/abs/2111.12993
下圖 1 為 PolyViT 的結構概覽。
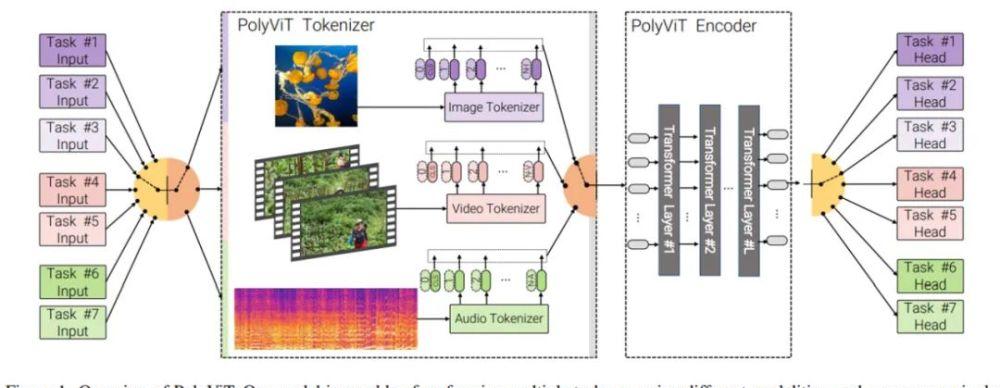
研究者主要使用的方法是協同訓練(co-training),即同時在多個分類任務(可能跨多個模态)上訓練單個模型。他們考慮了不同的設定,同時解決多達 9 個不同的圖像、視訊和音頻分類任務。如上圖 1 所示,PolyViT 模型能夠執行多個任務,但對于給定的輸入一次隻能執行一個任務。雖然計算機視覺和自然語言領域探索過類似的方法,但研究者不清楚以往的工作是否考慮了多種模态以及是否使用這種方法實作了 SOTA 結果。
我們的協同訓練設定簡單實用。它不需要對協同訓練資料集的每個組合進行超參數調整,因為我們可以很容易地調整标準單任務訓練的設定。此外,協同訓練也不會增加整體訓練成本,因為訓練步驟的總數不超過每個單任務基線的總和。
圖像、音頻和視訊上的 Co-training ViT
PolyViT 架構
PolyViT 是一個能夠處理來自多種模态的輸入的單一架構。如上圖 1 所示,研究者在不同的任務和模态中共享一個 transformer 編碼器,使得參數随任務數量呈線性減少。注意,在處理圖像時,具有 L 個層的 PolyViT 表現得像 L 層的 ViT,處理音頻時表現得像 L 層的 AST,處理視訊時表現得像 L 層的未因式分解(unfactorized)的 ViViT。雖然 PolyViT 能夠處理多種模态,但在給定前向傳遞時隻能基于一種模态執行一個任務。
PolyViT 部署模态特定的類 token,即、輸入嵌入算子和位置嵌入。這使得網絡可以編碼模态特定的資訊,這些資訊又可以被随後的、共享 transformer 主幹所利用。
為了實作大量任務和模态協同訓練的同時增加模型容量,研究者可以選擇性地納入 L_adapt ≥ 0 模态特定 transformer 層(他們表示為模态 - 擴充卡層),這些 transformer 層在 tokenization 之後直接應用。在這種情況下,所有模态和任務中會共享 L_=shared = L L_adapt 層。
協同訓練流程
在使用随機梯度下降(SGD)協同訓練的所有任務中,研究者同時優化所有的 PolyViT 模型參數 θ。是以,在決定如何建構訓練 batch、計算梯度以更新模型參數以及使用哪些訓練超參數時有很多設計上的選擇。
在所有情況下,研究者使用來自單個任務中的示例來建構自己的訓練 minibatch。這一設計選擇使得他們在使用相同的訓練超參數(如學習率、batch 大小和動量)作為傳統單一任務基線時,可以評估梯度和更新參數。這樣一來,與單一任務基線相比,研究者無需任何額外的超參數就可以執行多個任務上的協同訓練,進而使得協同訓練在實踐中易于執行,并減少執行大規模超參數掃描(sweep)的需求以實作具有競争力的準确性。
在協同訓練過程中,對于每個 SGD 步,研究者采樣一個任務(或資料集),然後采樣來自這個任務中的 minibatch,評估梯度并随後執行參數更新。需要着重考慮的是采樣任務的順序以及是否在不同的 minibatch 和任務上累積梯度。研究者在下圖 2 中描述了幾個任務采樣計劃,包括如下:
任務 1:逐任務(Task-by-task)
任務 2:交替(Alternating)
任務 3:統一任務采樣(Uniform task sampling)
任務 4:權重任務采樣(Weighted task sampling)
任務 5:累積梯度(Accumulating gradients)

實驗
研究者在圖像、音頻和視訊三種模态的 9 個不同分類任務上同時訓練了 PolyViT。在圖像分類協同訓練時,他們使用了 ImageNet-1K、 CIFAR-10/100、Oxford-IIIT Pets 和 RESISC45 資料集;對于視訊任務,他們使用了 Kinetics 400 和 Moments in Time 資料集;對于音頻任務,他們使用了 AudioSet 和 VGGSound 資料集。
下表 6 為具體實驗設定:
下表 1 展示了不同任務采樣計劃在不同模态和任務上對協同訓練性能的影響,粗體表示最高準确率,下劃線表示次最高準确率。其中,「Task-by-task」采樣計劃表現糟糕,僅在一項任務上實作了不錯的性能,這是災難性遺忘(catastrophic forgetting)造成的。
「Accumulated」采樣計劃需要在所有任務上使用單一的學習率,這是由于所有任務上的累積梯度被用于執行參數更新。是以,該計劃僅在圖像資料集上表現良好。
「Alternating」、「Uniform」和「Weighted」采樣計劃表現最好,表明任務特定的學習率以及不同任務的梯度更新之間的轉換對于準确率至關重要。
使用 PolyViT 的協同訓練
下表 2 展示了用于解決跨圖像、音頻和視訊三種模态的 9 個不同任務的模型訓練方法,包括 ViT-Im21K Linear probe、Single-task baseline 和本文的 PolyViT 及變體(分别是 PolyViT L_adapt = 0 和 PolyViT Ladapt = L/2)。
結果顯示,在單模态上訓練的 PolyViT 在 9 個資料集的 7 個上實作了 SOTA 性能,其餘 2 個資料集上的準确率差異可以忽略不計,不超過 0.3%。此外,參數的總數量比單個任務基線少了 2/3。同時,在使用參數大大減少的情況下,多模态 PolyViT 也實作了有競争力的性能。
使用 linear probe 評估學習到的表示
通過為一個新任務僅僅添加和訓練一個新的線性頭(linear head),研究者對 PolyViT 學習到的特征表示進行評估。下表 3 展示了多種模态上訓練的 PolyViT 如何學習「在跨圖像、音頻和視訊三種模态的 11 個線性評估任務上均表現良好的」跨模态特征表示。同時,表 3 還展示了多種模态上的協同訓練如何有益于學習強大、可遷移且可用于多個下遊任務的特征表示。
使用單模态協同訓練實作 SOTA 性能
受到上表 2 中單模态協同訓練性能的啟發,研究者使用這種方法在音頻和視訊分類任務上執行了大規模協同訓練實驗。下表 4 和表 5 顯示,在使用的參數明顯更少的同時,他們實作了 SOTA 結果。
如下表 4 所示,對于音頻分類,研究者将 PolyViT 與目前 SOTA 方法 MBT(audio-only) 及相關變體 MBT: AS-500kVGGSound 和 MBT: VGGSoundAS-500k。結果表明,PolyViT 在兩個資料集上超越了 SOTA 方法,同時使用的參數大約是 MBT(audio-only) 的一半。此外,PolyViT 在更小的資料集 VGGSound 上實作了 2.8% 的 Top 1 準确率提升。
對于視訊分類,研究者在 Kinetics-400、Kinetics-600 和 Moments in Time 資料集上協同訓練了具有較小 tubelet size 的 PolyViT-Large 模型,并與目前 SOTA 模型 ViViT(使用相同的初始化、主幹和 token 數量)進行了比較。結果如下表 5 所示,表明 PolyViT 在三個資料集上均超越了 ViViT。