梯度消失,梯度爆炸_解決辦法
本文主要參考:詳解機器學習中的梯度消失、爆炸原因及其解決方法
在上一篇博文中分析了,梯度消失與梯度爆炸的原因,其問題主要出現在誤差反向傳播上,如下:
對于 n n n層神經網絡,根據反向傳播的公式,到第 n − i n-i n−i層的權重 w n − i − 1 w_{n-i-1} wn−i−1更新規則為:
δ n − i = ( ω n − i ⋅ ⋅ ⋅ ( ω n − 2 ( ω n − 1 ( ω n δ n ∗ f n − 1 ′ ) ∗ f n − 2 ′ ) ∗ f n − 3 ′ ) ⋅ ⋅ ⋅ ∗ f n − i ′ ) \delta ^{n-i}=(\omega _{n-i}\cdot\cdot\cdot(\omega _{n-2}(\omega _{n-1}(\omega _{n}\delta ^{n}* f_{n-1}')* f_{n-2}')* f_{n-3}')\cdot\cdot\cdot* f_{n-i}') δn−i=(ωn−i⋅⋅⋅(ωn−2(ωn−1(ωnδn∗fn−1′)∗fn−2′)∗fn−3′)⋅⋅⋅∗fn−i′)
Δ w n − i − 1 = η δ n − i x n − i \Delta w_{n-i-1}=\eta \delta ^{n-i}x_{n-i} Δwn−i−1=ηδn−ixn−i
也就是說問題出現在激活函數的導數 f ′ f' f′還有權重 w w w上,下面從就從這兩方面入手,來解決梯度消失,梯度爆炸問題.
激活函數方面
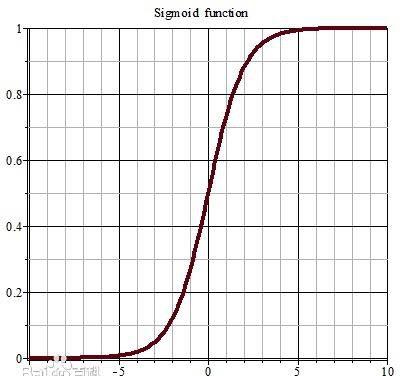
如果激活函數選擇不合适,比如使用sigmoid,梯度消失就會很明顯了,原因看下圖,左圖是sigmoid的損失函數圖,右邊是其導數的圖像,如果使用sigmoid作為損失函數,其梯度是不可能超過0.25的,這樣經過連乘之後,很容易發生梯度消失. sigmoid函數數學表達式為: s i g m o i d ( x ) = 1 1 + e − x sigmoid(x)=\dfrac {1}{1+e^{-x}} sigmoid(x)=1+e−x1

relu激活函數
如果激活函數的導數為1,那麼就不存在梯度消失爆炸的問題了,每層的網絡都可以得到相同的更新速度,relu就這樣應運而生。先看一下relu的數學表達式:
r e l u ( x ) = m a x ( x , 0 ) = { 0 , x < 0 x , x ≥ 0 relu(x)=max(x,0)=\begin{cases}0,x <0\\ x,x\geq 0\end{cases} relu(x)=max(x,0)={0,x<0x,x≥0
其函數圖像為:
優點:
- 解決了梯度消失、爆炸的問題
- 計算友善,計算速度快
- 加速了網絡的訓練
缺點
- 由于負數部分恒為0,會導緻一些神經元無法激活(可通過設定國小習率部分解決)
- 輸出不是以0為中心的
leakrelu激活函數
leakrelu就是為了解決relu的0區間帶來的影響,其數學表達為: l e a k r e l u = m a x ( k ∗ x , x ) leakrelu=max(k∗x,x) leakrelu=max(k∗x,x)其中k是leak系數,一般選擇0.01或者0.02,或者通過學習而來.
elu激活函數
elu激活函數也是為了解決relu的0區間帶來的影響,但是elu相對于leakrelu來說,計算要更耗時間一些,其函數及其導數數學形式為:
e l u ( x ) = { x , x > 0 a ( e − x − 1 ) , x ≤ 0 elu(x)=\begin{cases}x,x >0\\ a\left( e^{-x}-1\right) ,x\leq 0\end{cases} elu(x)={x,x>0a(e−x−1),x≤0
權重 w w w方面
批規範化Batchnorm
Batchnorm是深度學習發展以來提出的最重要的成果之一了,目前已經被廣泛的應用到了各大網絡中,具有加速網絡收斂速度,提升訓練穩定性的效果。batchnorm全名是batch normalization,簡稱BN,即批規範化,通過規範化操作将輸出信号x規範化保證網絡的穩定性。
反向傳播式子中有 w w w的存在,是以 w w w的大小影響了梯度的消失和爆炸,batchnorm就是通過對每一層的輸出規範為均值和方差一緻的方法,消除了 w w w帶來的放大縮小的影響,進而解決梯度消失和爆炸的問題,或者可以了解為BN将輸出從飽和區拉倒了非飽和區。有關batch norm詳細的内容可以參考部落格
權重正則化(weithts regularization)
正則化是通過對網絡權重做正則限制過拟合,如果發生梯度爆炸,權值的範數就會變的非常大,通過正則化項,可以部分限制梯度爆炸的發生.關于正則化的解釋見機器學習之正則化(Regularization),機器學習中 L1 和 L2 正則化的直覺解釋.
其它方面
梯度剪切
梯度剪切這個方案主要是針對梯度爆炸提出的,其思想是設定一個梯度剪切門檻值,然後更新梯度的時候,如果梯度超過這個門檻值,那麼就将其強制限制在這個範圍之内。這可以防止梯度爆炸。
殘差結構
事實上,就是殘差網絡的出現導緻了image net比賽的終結,自從殘差提出後,幾乎所有的深度網絡都離不開殘差的身影,相比較之前的幾層,幾十層的深度網絡,在殘差網絡面前都不值一提,殘差可以很輕松的建構幾百層,一千多層的網絡而不用擔心梯度消失過快的問題,原因就在于殘差的捷徑(shortcut)部分,其中殘差單元如下圖所示:
相比較于以前網絡的直來直去結構,殘差中有很多這樣的跨層連接配接結構,這樣的結構在反向傳播中具有很大的好處,見下式:
式子的第一個因子 ∂ l o s s ∂ x L \dfrac {\partial loss}{\partial x_{L}} ∂xL∂loss 表示的損失函數到達 L L L 的梯度,小括号中的1表明短路機制可以無損地傳播梯度,而另外一項殘差梯度則需要經過帶有weights的層,梯度不是直接傳遞過來的。殘差梯度不會那麼巧全為-1,而且就算其比較小,有1的存在也不會導緻梯度消失。是以殘差學習會更容易。