時間順序:
FCN 、SegNet 、U-Net、Dilated Convolutions 、DeepLab (v1 & v2) 、RefineNet 、PSPNet 、Large Kernel Matters 、DeepLab v3 。
1、Fully Convolution Networks (FCNs) 全卷積網絡
相應連接配接:Arxiv
我們将目前分類網絡(AlexNet, VGG net 和 GoogLeNet)修改為全卷積網絡,通過對分割任務進行微調,将它們學習的表征轉移到網絡中。然後,我們定義了一種新的架構,它将深的、粗糙的網絡層的語義資訊和淺的、精細的網絡層的表層資訊結合起來,來生成精确和詳細的分割。我們的全卷積網絡在 PASCAL VOC(在2012年相對以前有20%的提升,達到了62.2%的平均IU),NYUDv2 和 SIFT Flow 上實作了最優的分割結果,對于一個典型的圖像,推斷隻需要三分之一秒的時間。
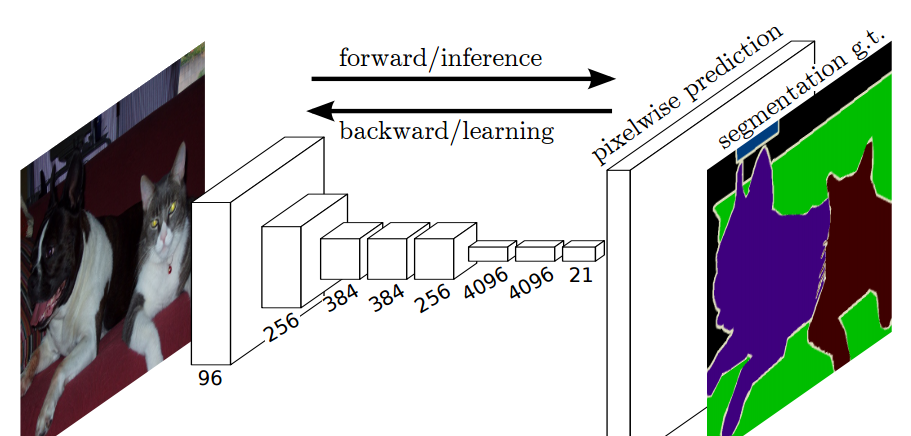
FCN端到端的密集預測流
關鍵點:
1、端到端預測,做pixel-wise級别的預測
2、對AlexNet、VGG等延展(全連接配接層轉換成全卷積層)
3、fine-tune相關的網絡
4、任意輸入,輸出分類熱力圖map(因為輸出類沒有确定,是以可以任意輸入)
5、特征是由編碼器中的不同階段合并而成的,它們在語義資訊的粗糙程度上有所不同
6、低分辨率語義特征圖的上采樣使用經雙線性插值濾波器初始化的反卷積操作完成
7、損失函數是在最後一層的 spatial map上的 pixel 的 loss 和,在每一個 pixel 使用 softmax loss
8、

第2點: 将全連接配接層轉換成卷積層,使得分類網絡可以輸出一個類的熱圖
第5點:FCN-8s 網絡架構
FCN-8
如上圖所示,對原圖像進行卷積conv1、pool1後原圖像縮小為1/2;之後對圖像進行第二次conv2、pool2後圖像縮小為1/4;接着繼續對圖像進行第三次卷積操作conv3、pool3縮小為原圖像的1/8,此時保留pool3的featureMap;接着繼續對圖像進行第四次卷積操作conv4、pool4,縮小為原圖像的1/16,保留pool4的featureMap;最後對圖像進行第五次卷積操作conv5、pool5,縮小為原圖像的1/32,然後把原來CNN操作中的全連接配接變成卷積操作conv6、conv7,圖像的featureMap數量改變但是圖像大小依然為原圖的1/32,此時進行32倍的上采樣可以得到原圖大小,這個時候得到的結果就是叫做FCN-32s.
這個時候可以看出,FCN-32s結果明顯非常平滑,不精細. 針對這個問題,作者采用了combining what and where的方法,具體來說,就是在FCN-32s的基礎上進行fine tuning,把pool4層和conv7的2倍上采樣結果相加之後進行一個16倍的上采樣,得到的結果是FCN-16s.
之後在FCN-16s的基礎上進行fine tuning,把pool3層和2倍上采樣的pool4層和4倍上采樣的conv7層加起來,進行一個8倍的上采樣,得到的結果就是FCN-8s.
可以看出結果明顯是FCN-8s好于16s,好于32s的.
缺點:
1、首先是訓練比較麻煩,需要訓練三次才能夠得到FCN-8s
2、是得到的結果還是不夠精細。進行8倍上采樣雖然比32倍的效果好了很多,但是上采樣的結果還是比較模糊和平滑,對圖像中的細節不敏感
3、是對各個像素進行分類,沒有充分考慮像素與像素之間的關系。忽略了在通常的基于像素分類的分割方法中使用的空間規整(spatial regularization)步驟,缺乏空間一緻性。
2、SegNet(A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation)
相應連接配接:Arxiv
SegNet 的新穎之處在于解碼器對其較低分辨率的輸入特征圖進行上采樣的方式。具體地說,解碼器使用了在相應編碼器的最大池化步驟中計算的池化索引來執行非線性上采樣。這種方法消除了學習上采樣的需要。經上采樣後的特征圖是稀疏的,是以随後使用可訓練的卷積核進行卷積操作,生成密集的特征圖。我們将我們所提出的架構與廣泛采用的 FCN 以及衆所周知的 DeepLab-LargeFOV,DeconvNet 架構進行比較。比較的結果揭示了在實作良好的分割性能時所涉及的記憶體與精度之間的權衡。
SegNet 架構
關鍵點:
1、在解碼器中使用反池化對特征圖進行上采樣,并在分割中保持高頻細節的完整性
2、編碼器不使用全連接配接層(和 FCN 一樣進行卷積),是以是擁有較少參數的輕量級網絡
反池化
如上圖所示,編碼器中的每一個最大池化層的索引都被存儲起來,用于之後在解碼器中使用那些存儲的索引來對相應的特征圖進行反池化操作。雖然這有助于保持高頻資訊的完整性,但當對低分辨率的特征圖進行反池化時,它也會忽略鄰近的資訊。
3、U-Net(Convolutional Networks for Biomedical Image Segmentation)
相應連接配接:Arxiv
U-Net 架構包括一個捕獲上下文資訊的收縮路徑(下采樣)和一個支援精确本地化的對稱擴充路徑(上采樣)。我們證明了這樣一個網絡可以使用非常少的圖像進行端到端的訓練,并且在ISBI神經元結構分割挑戰賽中取得了比以前最好的方法(一個滑動視窗的卷積網絡)更加優異的性能。我們使用相同的網絡,在透射光顯微鏡圖像(相位對比度和 DIC)上進行訓練,以很大的優勢獲得了2015年 ISBI 細胞追蹤挑戰賽。此外,網絡推斷速度很快。一個512x512的圖像的分割在最新的 GPU 上花費了不到一秒。
U-Net 架構
關鍵點:
1、U-Net 簡單地将編碼器的特征圖拼接至每個階段解碼器的上采樣特征圖,進而形成一個梯形結構。該網絡非常類似于 Ladder Network 類型的架構。
2、通過跳躍
拼接
連接配接的架構,在每個階段都允許解碼器學習在編碼器池化中丢失的相關特征。
3、上采樣采用轉置卷積
4、Unet隻需要一次訓練,FCN需要三次訓練.
5、資料增強:形變
6、overlap-tile政策
相關介紹:
(1)左邊的網絡contracting path:使用卷積和maxpooling。
(2)右邊的網絡expansive path:使用上采樣與左側contracting path ,pooling層的featuremap相結合,然後逐層上采樣到392X392的大小heatmap。(pooling層會丢失圖像資訊和降低圖像分辨率且是不可逆的操作,對圖像分割任務有一些影響,對圖像分類任務的影響不大,為什麼要做上采樣?:因為上采樣可以補足一些圖檔的資訊,但是資訊補充的肯 定不完全,是以還需要與左邊的分辨率比較高的圖檔相連接配接起來(直接複制過來再裁剪到與上采樣圖檔一樣大小),這就相當于在高分辨率和更抽象特征當中做一個折衷,因為随着卷積次數增多,提取的特征也更加有效,更加抽象,上采樣的圖檔是經曆多次卷積後的圖檔,肯定是比較高效和抽象的圖檔,然後把它與左邊不怎麼抽象但更高分辨率的特征圖檔進行連接配接)
(3)最後再經過兩次卷積,達到最後的heatmap,再用一個1X1的卷積做分類,這裡是分成兩類,得到最後的兩張heatmap,例如第一張表示的是第一類的得分(即每個像素點對應第一類都有一個得分),第二張表示第二類的得分heatmap,然後作為softmax函數的輸入,算出機率比較大的softmax類,選擇它作為輸入給交叉熵進行反向傳播訓練
(4)訓練
采用随機梯度下降法訓練。為了最大限度的使用GPU顯存,比起輸入一個大的batch size,更傾向于大量輸入tiles。使用了很高的momentum(0.99)。 最後一層使用交叉熵函數與softmax。(交叉熵函數如下所示)
為了使某些像素點更加重要,引入了w(x)。我們對每一張标注圖像預計算了一個權重圖,來補償訓練集中每類像素的不同頻率,使網絡更注重學習互相接觸的細胞之間的小的分割邊界。使用形态學操作計算分割邊界。權重圖計算公式如下:
wc是用于平衡類别頻率的權重圖,d1代表到最近細胞的邊界的距離,d2代表到第二近的細胞的邊界的距離。基于經驗我們設定w0=10,σ≈5像素。 網絡中權重的初始化:我們的網絡的權重由高斯分布初始化,分布的标準差為(N/2)^0.5,N為每個神經元的輸入節點數量。例如,對于一個上一層是64通道的3*3卷積核來說,N=9*64。 (5)overlap-tile政策 為了預測框中圖像,缺失區域通過鏡像輸入圖像擴張。這種tiling方法對于應用網絡到大圖像很重要,因為否則結果會被gpu記憶體限制。為了預測黃色區域的分割,需要藍色區域作為輸入。
(6)資料增加 在隻有少量樣本的情況況下,要想盡可能的讓網絡獲得不變性和魯棒性,資料增加是必不可少的。因為本論文需要處理顯微鏡圖檔,我們需要平移與旋轉不變性,并且對形變和灰階變化魯棒。将訓練樣本進行 随機彈性形變是訓練分割網絡的關鍵。我們使用随機位移矢量在粗糙的3*3網格上(random displacement vectors on a coarse 3 by 3 grid)産生平滑形變(smooth deformations)。 位移是從10像素标準偏差的高斯分布中采樣的。然後使用雙三次插值計算每個像素的位移。在contracting path的末尾采用drop-out 層更進一步增加資料。
資料增強
U-net典型應用:
(1)Kaggle-Airbus Ship Detection Challenge:
在衛星圖像中找到船,在公開的kernal中最受歡迎的是Unet,達到了84.7的精度。
(2)Kaggle-衛星圖像分割與識别:
需要在衛星圖像中分割出:房屋、道路、鐵路、樹木、農作物、河流、積水區、大型車輛、小轎車。在Unet基礎上微調,針對不同的分割對象,微調的地方不同,會産生不同的分割模型,最後融合。推薦一篇不錯的博文:
Kaggle優勝者詳解:如何用深度學習實作衛星圖像分割與識别
(3)Supervise.ly公司:
在用Faster-RCNN(基于resnet)定位+Unet-like架構的分割,來做他們資料衆包圖像分割方向的主動學習,當時沒有使用mask-rcnn,因為靠近物體邊緣的分割品質很低(終于!Supervise.ly釋出人像分割資料集啦(免費開源))
(4)廣東政務資料創新大賽—智能算法賽 :
國土監察業務中須監管地上建築物的建、拆、改、擴,高分辨率圖像和智能算法以自動化完成工作。并且:八通道U-Net:直接輸出房屋變化,可應對高層建築傾斜問題;資料增強:增加模型泛化性,簡單有效;權重損失函數:增強對新增建築的檢測能力;模型融合:取長補短,結果更全。其中季軍公布了源碼
(5)Kaggle車輛邊界識别——TernausNet 由VGG初始化權重 + U-Net網絡,Kaggle Carvana Image
Masking Challenge
第一名,使用的預訓練權重改進U-Net,提升圖像分割的效果。開源的代碼在TernausNet
(6)Kaggle新上比賽:地震圖像的鹽體分割
U-Net 在 EM 資料集上取得了最優異的結果,該資料集隻有30個密集标注的醫學圖像和其他醫學圖像資料集,U-Net 後來擴充到3D版的 3D-U-Net。雖然 U-Net 最初的發表在于其在生物醫學領域的分割、網絡的實用性以及從非常少的資料中學習的能力,但現在已經成功應用其他幾個領域,例如 衛星圖像分割,同時也成為許多 kaggle競賽 中關于醫學圖像分割的獲勝的解決方案的一部分。
4、Dilated Convolutions
通過膨脹卷積操作聚合多尺度的資訊
轉置卷積 轉置卷積 空洞卷積(微步卷積,膨脹卷積)
第一個推導公式: o′=s(i−1)+k−2p。比如10*10變成19*19,可知k=3,p=1,s=2。
Deep CNN 對于其他任務還有一些緻命性的缺陷。如 up-sampling 和 pooling layer 的設計。
- Up-sampling / pooling layer (e.g. bilinear interpolation) is deterministic. (a.k.a. not learnable)。
- 内部資料結構丢失;空間層級化資訊丢失。
- 小物體資訊無法重建 (假設有四個pooling layer 則 任何小于 2^4 = 16 pixel 的物體資訊将理論上無法重建。)
- 池化降低了分辨率。
在這樣問題的存在下,語義分割問題一直處在瓶頸期無法再明顯提高精度, 而 dilated convolution 的設計就很好的避免了這些問題。
但空洞卷積本身也存在問題
1、The gridding effect:網格效應,丢失資訊的連續性
layer i-2中與layer i中紅色、藍色、綠色、黃色對應的units,完全沒有交集(準确的說是除了kernel中間的unit之外)。這就是産生gridding artifacts的原因。
針對1,引出兩種方法。
法一:相同顔色抽出來變成像卷積那樣處理
最後面改成如下,每個灰階兼顧四種顔色。
法2:
Separable and Shared Convolutions
具體連接配接
2、Long-ranged information might be not relevant. : 遠端資訊(小物體)效果差
針對2,引入 通向标準化設計:Hybrid Dilated Convolution (HDC),這個HDC的特點是符合多尺度檢測:
第一個特性是,疊加卷積的 dilation rate 不能有大于1的公約數。比如 [2, 4, 6] 則不是一個好的三層卷積,依然會出現 gridding effect。
第二個特性是,我們将 dilation rate 設計成 鋸齒狀結構,例如 [1, 2, 5, 1, 2, 5] 循環結構。
第三個特性是,我們需要滿足一下這個式子:
語義分割相關網絡簡述 語義分割相關網絡簡述
形象了解深度學習中八大類型卷積
https://baijiahao.baidu.com/s?id=1625326459426256979&wfr=spider&for=pc
4、DeepLab v1(Semantic Image Segmentation with deep convolutional nets and fully connected CRFs)
DCNN + CRFs
相關連接配接:Arxiv
近來,深度卷積網絡在進階視覺任務(圖像分類和目标檢測)中展示了優異的性能。本文結合 DCNN 和機率圖模型來解決像素級分類任務(即語義分割)。我們展示了 DCNN 最後一層的響應不足以精确定位目标邊界,這是 DCNN 的不變性導緻的。我們通過在最後一層網絡後結合全連接配接條件随機場來解決糟糕的定位問題。我們的方法在 PASCAL VOC 2012 上達到了 71.6% 的 mIoU。
關鍵點:
1、提出 空洞卷積(atrous convolution)(又稱擴張卷積(dilated convolution))。
2、在最後兩個最大池化操作中不降低特征圖的分辨率,并在倒數第二個最大池化之後的卷積中使用空洞卷積。
3、使用 CRF(條件随機場) 作為後處理,恢複邊界細節,達到準确定位效果。
4、附加輸入圖像和前四個最大池化層的每個輸出到一個兩層卷積,然後拼接到主網絡的最後一層,達到 多尺度預測 效果。
空洞卷積,藍色輸入,綠色輸出
5、DeepLab v2(DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs)
DCNN(ASPP)+CRFs
相應連接配接:Arxiv
首先,我們強調上采樣過濾器的卷積,或“空洞卷積”,在密集預測任務中是一個強大的工具。空洞卷積允許我們顯式地控制在深度卷積神經網絡中計算的特征響應的分辨率。它還允許我們有效地擴大過濾器的視野,在不增加參數數量或計算量的情況下引入更大的上下文。其次,提出了一種空洞空間金字塔池化(ASPP)的多尺度魯棒分割方法。ASPP 使用多個采樣率的過濾器和有效的視野探測傳入的卷積特征層,進而在多個尺度上捕獲目标和圖像上下文。第三,結合 DCNNs 方法和機率圖形模型,改進了目标邊界的定位。DCNNs 中常用的最大池化和下采樣的組合實作了不變性,但對定位精度有一定的影響。我們通過将 DCNN 最後一層的響應與一個全連接配接條件随機場(CRF)相結合來克服這個問題。DeepLab v2 在 PASCAL VOC 2012 上得到了 79.7% 的 mIoU。
關鍵點:
1、提出了空洞空間金字塔池化(Atrous Spatial Pyramid Pooling),在不同的分支采用不同的空洞率以獲得多尺度圖像表征。
ASPP結構
6、DeepLab v3(Rethinking Atrous Convolution for Semantic Image Segmentation)
DCNN(ASPP+BN)
相應連接配接:Arxiv
在本工作中,我們再次讨論空洞卷積,一個顯式調整過濾器視野,同時控制特征相應分辨率的強大工具。為了解決多尺度目标的分割問題,我們串行/并行設計了能夠捕捉多尺度上下文的子產品,子產品中采用不同的空洞率。此外,我們增強了先前提出的空洞空間金字塔池化子產品,增加了圖像級特征來編碼全局上下文,使得子產品可以在多尺度下探測卷積特征。提出的 “DeepLab v3” 系統在沒有 CRF 作為後處理的情況下顯著提升了性能。
改進的ASPP
關鍵點:
1、在殘差塊中使用多網格方法(MultiGrid),進而引入不同的空洞率。
2、在空洞空間金字塔池化子產品中加入圖像級(Image-level)特征,并且使用 BatchNormalization 技巧。
7、Mask R-CNN
相關連接配接:Arxiv
該方法被稱為 Mask R-CNN,以Faster R-CNN 為基礎,在現有的邊界框識别分支基礎上添加一個并行的預測目标掩碼的分支。Mask R-CNN 很容易訓練,僅僅在 Faster R-CNN 上增加了一點小開銷,運作速度為 5fps。此外,Mask R-CNN 很容易泛化至其他任務,例如,可以使用相同的架構進行姿态估計。我們在 COCO 所有的挑戰賽中都獲得了最優結果,包括執行個體分割,邊界框目标檢測,和人關鍵點檢測。在沒有使用任何技巧的情況下,Mask R-CNN 在每項任務上都優于所有現有的單模型網絡,包括 COCO 2016 挑戰賽的獲勝者。
(左)Mask R-CNN 分割流程 (右)原始 Faster-RCNN 架構和輔助分割分支
關鍵點:
1、在Faster R-CNN 上添加輔助分支以執行語義分割
2、對每個執行個體進行的 RoIPool 操作已經被修改為 RoIAlign ,它避免了特征提取的空間量化,因為在最高分辨率中保持空間特征不變對于語義分割很重要。
因為RoI Pooling并不是按照像素一一對齊的(pixel-to-pixel alignment),也許這對bbox的影響不是很大,但對于mask的精度卻有很大影響。
3、Mask R-CNN 與 Feature Pyramid Networks(類似于PSPNet,它對特征使用了金字塔池化)相結合,在 MS COCO 資料集上取得了最優結果。
4、相比于FCIS,FCIS使用全卷機網絡,同時預測物體classes、boxes、masks,速度更快,但是對于重疊物體的分割效果不好。
5、這與通常将FCN應用于像素級Softmax和多重交叉熵損失的語義分段的做法不同。在這種情況下,掩碼将在不同類别之間競争。而mask rcnn,使用了其它方法沒有的像素級的Sigmod和二進制損失。我們通過實驗發現,這種方法是改善目标分割效果的關鍵。
6、使用ResNet-FPN進行特征提取的Mask R-CNN可以在精度和速度方面獲得極大的提升。
注意點:
1、RoIAlign:RoIPool的目的是為了從RPN網絡确定的ROI中導出較小的特征圖(a small feature map,eg 7x7),ROI的大小各不相同,但是RoIPool後都變成了7x7大小。RPN網絡會提出若幹RoI的坐标以[x,y,w,h]表示,然後輸入RoI Pooling,輸出7x7大小的特征圖供分類和定位使用。問題就出在RoI Pooling的輸出大小是7x7上,如果RON網絡輸出的RoI大小是8*8的,那麼無法保證輸入像素和輸出像素是一一對應,首先他們包含的資訊量不同(有的是1對1,有的是1對2),其次他們的坐标無法和輸入對應起來(1對2的那個RoI輸出像素該對應哪個輸入像素的坐标?)。這對分類沒什麼影響,但是對分割卻影響很大。RoIAlign的輸出坐标使用插值算法得到,不再量化;每個grid中的值也不再使用max,同樣使用內插補點算法。
RoIWarp與RoIPool效果差不多,比RoIAlign差得多。這突出表明正确的對齊是關鍵。
2、FPN圖像金字塔網絡
FPN能很好的處理小目标:1、FPN關注上下文資訊 2、增加小目标特征映射分辨率(在大feature map上有更多的小目标的特征)
(a)每層都是圖像金字塔:缺點是計算量大,需要大量的記憶體;優點是可以獲得較好的檢測精度。
(b)每層都是特征金字塔:高層關注語義資訊,底層關注細節資訊,這裡這關注高層容易造成細節丢失。
(c)它的優點是在不同的層上面輸出對應的目标,不需要經過所有的層才輸出對應的目标(即對于有些目标來說,不需要進行多餘的前向操作),這樣可以在一定程度上對網絡進行加速操作,同時可以提高算法的檢測性能。它的缺點是獲得的特征不魯棒,都是一些弱特征(因為很多的特征都是從較淺的層獲得的)。
(d)首先我們在輸入的圖像上進行深度卷積,然後對Layer2上面的特征進行降維操作(即添加一層1x1的卷積層),對Layer4上面的特征就行上采樣操作,使得它們具有相應的尺寸,然後對處理後的Layer2和處理後的Layer4執行加法操作(對應元素相加),将獲得的結果輸入到Layer5中去。其背後的思路是為了獲得一個強語義資訊,這樣可以提高檢測性能。
3、The Spatial Pyramid Pooling Layer 空間金字塔池化
8、RefineNet
RefineNet可以分為三個主要部分:
1. 不同尺度(也可能隻有一個輸入尺度)的特征輸入首先經過兩個Residual子產品的處理;
2. 之後是不同尺寸的特征進行融合。當然如果隻有一個輸入尺度,該子產品則可以省去。所有特征上采樣至最大的輸入尺寸,然後進行加和。上采樣之前的卷積子產品是為了調整不同特征的數值尺度;
3. 最後是一個鍊式的pooling子產品。其設計本意是使用側支上一系列的pooling來擷取背景資訊(通常尺寸較大)。直連通路上的ReLU可以在不顯著影響梯度流通的情況下提高後續pooling的性能,同時不讓網絡的訓練對學習率很敏感。最後再經過一個Residual子產品即得RefineNet的輸出。
9、PSPNet(PSPNet: Pyramid Scene Parsing Network)
相關連接配接:Arxiv
在本文中,我們利用基于不同區域的上下文資訊集合,通過我們的金字塔池化子產品,使用提出的金字塔場景解析網絡(PSPNet)來發揮全局上下文資訊的能力。我們的全局先驗表征在場景解析任務中産生了良好的品質結果,而 PSPNet 為像素級的預測提供了一個更好的架構,該方法在不同的資料集上達到了最優性能。它首次在2016 ImageNet 場景解析挑戰賽,PASCAL VOC 2012 基準和 Cityscapes 基準中出現。
PSPNet 架構
關鍵點:
1、PSPNet 通過引入空洞卷積來修改基礎的 ResNet 架構,特征經過最初的池化,在整個編碼器網絡中以相同的分辨率進行處理(原始圖像輸入的
1/4
),直到它到達空間池化子產品。
2、在 ResNet 的中間層中引入輔助損失,以優化整體學習。
3、在修改後的 ResNet 編碼器頂部的空間金字塔池化聚合全局上下文。
轉載于:https://www.cnblogs.com/hotsnow/p/10801703.html