TFIDF
先複習一下 tfidf,tf是詞頻,即某個詞 i 在 文章 j 中出現的頻率。分母是文章中所有詞的個數,分母是詞 i 出現的次數。tf越高說明該詞越重要,對于短文本比對,每個詞一般隻出現一次,tf 的大小就取決于分母,即文章的長度。
idf是逆文檔頻率,計算該詞出現在所有文章中的頻率,此時,分母是包含該關鍵字 i 的文章數,分子是所有文章數 N。用log相當于趨勢不變,數值變小了。該詞出現越多,分子越大,idf值越小,比如:“的” 經常出現,是以不是關鍵詞。當詞 i 在 文章 j 中完全不出現,分母為0,是以給分母加 1。
tf和idf的乘積就是詞 i 在文章 j 中的重要性。
在搜尋中,計算搜尋串中的多個關鍵詞 與 文章 j 的相似度:将各詞的 tfidf 相加:
搜尋之前,需要知道各個詞在已知文章集中的分布。
BM25
BM25是基于TF-IDF的改進算法,BM 是Best Match最佳比對的縮寫,25指的是第25次算法疊代。
idf 部分隻做了微調:
其中分母部分從所有文章中減去了包含 i 的文章,0.5用于平滑。
接下來,又對 tf 做了如下調整:
這裡引入了超參數 k 和 b。
先看分母中的括号,Ld是文章長度,Lavg是所有文章的平均長度,當文章長度與平均長度一緻時,括号裡值為 1,相當于未乘系數;當文章比平均長度短時,括号裡的值小于1,分母越小,上式結果越大,也就是說文章越短,每一個詞越重要,這也與直覺一緻。另外,長度的影響與b有關,b越大,影響越大,b的取值在0-1之間,當b為0時,完全不考慮長度的影響,b 一般取值為 0.75。
k 用于标準化詞頻的範圍,将 tf 值壓縮到 0~k+1 之間,其函數曲線如下:
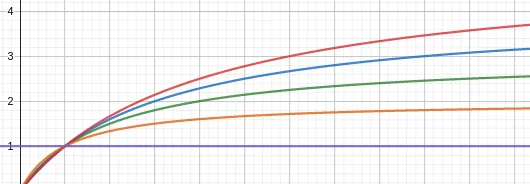
其橫軸為 tf,縱軸為 tfscore,分别針對 k=0,1,2,3,4 畫圖。當k=0時,tfscore為 1,不考慮詞頻的影響,而 k 越大詞頻越趨近于原始詞頻。是以,如果文章隻包含短文本,或者無需關注詞出現幾次,則可将其設成 k=0。
有時還考慮到詞 i 在搜尋文本中的頻率,上式擴充成:
其中td指被搜尋文本,tq指搜尋文本。
![K-近鄰算法以及圖像分類應用[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)