空間變換器網絡
paper題目:Spatial Transformer Networks
paper是Google DeepMind發表在NIPS 2015的工作
paper位址:連結
Abstract
卷積神經網絡定義了一類異常強大的模型,但仍受限于缺乏以計算和參數有效的方式對輸入資料保持空間不變的能力。在這項工作中,我們引入了一個新的可學習子產品,即 Spatial Transformer,它明确允許對網絡内的資料進行空間操作。這個可微分子產品可以插入到現有的卷積架構中,使神經網絡能夠根據特征圖本身對特征圖進行主動空間變換,而無需任何額外的訓練監督或對優化過程的修改。我們展示了空間變換器的使用導緻模型學習平移、縮放、旋轉和更通用的變形的不變性,進而在多個基準測試和許多類别的變換中産生最先進的性能。
1 Introduction
近年來,通過采用快速、可擴充、端到端的學習架構卷積神經網絡(CNN)[18],計算機視覺的格局發生了巨大的變化和推動。盡管不是最近的發明,但我們現在看到大量基于 CNN 的模型在分類、定位、語義分割和動作識别任務等方面取得了最先進的結果。
能夠對圖像進行推理的系統的一個理想屬性是從紋理和形狀中解開目标姿勢和部分變形。在 CNN 中引入局部最大池化層有助于滿足這一特性,因為它允許網絡在一定程度上對特征位置具有空間不變性。然而,由于對最大池化(例如 2 × 2 像素)的空間支援通常很小,這種空間不變性僅在最大池化和卷積的深層層次結構以及 CNN 中的中間特征圖(卷積層激活)上實作對輸入資料的大轉換實際上不是不變的 [5, 19]。 CNN 的這種限制是由于隻有一個有限的、預定義的池化機制來處理資料空間排列的變化。
在這項工作中,我們引入了 Spatial Transformer 子產品,該子產品可以包含在标準神經網絡架構中以提供空間轉換功能。空間變換器的動作取決于單個資料樣本,并在針對相關任務的訓練期間學習适當的行為(無需額外監督)。與池化層不同,池化層的感受野是固定的和局部的,空間變換器子產品是一種動态機制,可以通過為每個輸入樣本生成适當的變換來主動地空間變換圖像(或特征圖)。然後在整個特征圖(非局部)上執行轉換,可以包括縮放、裁剪、旋轉以及非剛性變形。這使得包含空間變換器的網絡不僅可以選擇圖像中最相關(注意)的區域,還可以将這些區域轉換為規範的、預期的姿勢,以簡化後續層中的推理。值得注意的是,空間轉換器可以通過标準的反向傳播進行訓練,進而允許對它們注入的模型進行端到端的訓練。
空間變換器可以整合到 CNN 中以有利于多種任務,例如:(i) 圖像分類:假設 CNN 被訓練為根據圖像是否包含特定數字(其中圖像的位置和大小)執行圖像的多路分類。 數字可能随每個樣本顯著變化(并且與類别不相關);一個空間變換器可以裁剪出适當的區域并進行尺度歸一化,可以簡化後續的分類任務,并帶來出色的分類性能,見圖 1; (ii) 共定位:給定一組包含相同(但未知)類的不同執行個體的圖像,可以使用空間變換器在每個圖像中定位它們; (iii) 空間注意:空間變換器可用于需要注意力機制的任務,例如在 [11, 29] 中,但更靈活,可以純粹通過反向傳播進行訓練,無需強化學習。使用注意力的一個關鍵好處是,可以使用轉換後的(并是以參與)較低分辨率的輸入來支援更高分辨率的原始輸入,進而提高計算效率。
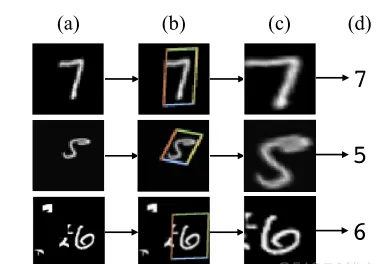
圖 1:使用空間變換器作為全連接配接網絡的第一層的結果,該網絡針對扭曲的 MNIST 數字分類進行了訓練。 (a) 空間變換器網絡的輸入是 MNIST 數字的圖像,該圖像因随機平移、縮放、旋轉和雜波而失真。 (b) 空間變換器的定位網絡預測要應用于輸入圖像的變換。 © 應用變換後的空間變換器的輸出。(d) 後續全連接配接網絡對空間變換器輸出的分類預測。空間變換器網絡(一個包含空間變換器子產品的 CNN)僅使用類标簽進行端到端訓練——系統沒有提供ground truth變換的知識。
2 Related Work
在本節中,我們将讨論與本文相關的先前工作,涵蓋使用神經網絡模組化轉換的中心思想 [12、13、27]、學習和分析轉換不變表示 [3、5、8、17、19、25 ],以及特征選擇的注意力和檢測機制[1、6、9、11、23]。
Hinton [12] 的早期工作着眼于為目标部分配置設定規範的參考架構,這一主題在 [13] 中反複出現,其中對 2D 仿射變換進行模組化以建立由變換部分組成的生成模型。生成訓練方案的目标是轉換後的輸入圖像,輸入圖像和目标之間的轉換作為網絡的附加輸入。結果是一個生成模型,它可以學習通過組合部分來生成目标的變換圖像。 Tieleman [27] 進一步提出了變換部分組合的概念,其中學習的部分被明确地仿射變換,變換由網絡預測。這種生成膠囊模型能夠從轉換監督中學習用于分類的判别特征。
在 [19] 中,通過估計原始圖像和變換圖像的表示之間的線性關系,研究了 CNN 表示對輸入圖像轉換的不變性和等變性。 Cohen & Welling [5] 分析了這種與對稱群相關的行為,這也在 Gens & Domingos [8] 提出的架構中得到了利用,進而産生了對對稱群更加不變的特征圖。設計變換不變表示的其他嘗試是散射網絡 [3],以及建構變換濾波器的濾波器組的 CNN [17、25]。斯托倫加等人。 [26] 使用基于網絡激活的政策來控制網絡過濾器對同一圖像的後續前向傳遞的響應,是以可以關注特定特征。在這項工作中,我們的目标是通過操縱資料而不是特征提取器來實作不變表示,這是在 [7] 中為聚類所做的。
具有選擇性注意的神經網絡通過裁剪來操縱資料,是以能夠學習翻譯不變性。諸如 [1, 23] 的工作通過強化學習進行訓練,以避免需要可微分注意力機制,而 [11] 通過在生成模型中利用高斯核來使用可微分注意機制。 Girshick 等人的工作。 [9] 使用區域提議算法作為注意力的一種形式,[6] 表明可以使用 CNN 回歸顯著區域。我們在本文中提出的架構可以看作是對任何空間變換的可微注意力的概括。
3 Spatial Transformers
在本節中,我們将描述空間變換器的公式。這是一個可微分子產品,它在單次前向傳遞期間将空間變換應用于特征圖,其中變換以特定輸入為條件,産生單個輸出特征圖。對于多通道輸入,對每個通道應用相同的變形。為簡單起見,在本節中,我們考慮單個變換和每個變換器的單個輸出,但是我們可以推廣到多個變換,如實驗所示。
空間變換機制分為三個部分,如圖 2 所示。為了計算,首先一個定位網絡(第 3.1 節)擷取輸入特征圖,并通過多個隐藏層輸出空間變換的參數這應該應用于特征圖——這給出了一個以輸入為條件的轉換。然後,預測的變換參數用于建立一個采樣網格,它是一組點,應該對輸入圖進行采樣以産生變換後的輸出。這是由網格生成器完成的,在第 3.2 節中描述。最後,将特征圖和采樣網格作為采樣器的輸入,生成從網格點處的輸入采樣的輸出圖(第 3.3 節)。

圖 2:空間變換器子產品的架構。輸入特征圖被傳遞到一個定位網絡,該網絡對變換參數進行回歸。上的規則空間網格被轉換為采樣網格,如 Sect 3.3中所述,将其應用于。産生扭曲的輸出特征圖。定位網絡和采樣機制的結合定義了空間變換器。
這三個元件的組合形成了一個空間變換器,現在将在以下部分中更詳細地描述。
3.1 Localisation Network
定位網絡采用寬度為、高度為和個通道的輸入特征圖并輸出,要應用于特征圖的變換的參數:。的大小可以根據參數化的變換類型而變化,例如對于仿射變換,是 6 維的,如 (1) 中所示。
定位網絡函數可以采用任何形式,例如全連接配接網絡或卷積網絡,但應包括最終回歸層以産生轉換參數。
3.2 Parameterised Sampling Grid
為了執行輸入特征圖的變形,每個輸出像素是通過應用以輸入特征圖中特定位置為中心的采樣核心來計算的(這将在下一節中完整描述)。通過像素,我們指的是通用特征圖的元素,不一定是圖像。通常,輸出像素被定義為位于像素的規則網格上,形成輸出特征圖,其中和是網格的高度和寬度,是通道數,在輸入和輸出中是一樣的。
為了清楚說明,暫時假設是 2D 仿射變換。我們将在下面讨論其他轉換。在這種仿射情況下,逐點變換是
其中是輸出特征圖中規則網格的目标坐标,是輸入特征圖中定義樣本點的源坐标,是仿射變換矩陣。我們使用高度和寬度歸一化坐标,使得當在輸出的空間範圍内時,并且當在輸入的空間範圍内時(對于坐标)。源/目标變換和采樣等價于圖形中使用的标準紋理映射和坐标。
(1) 中定義的變換允許對輸入特征圖應用裁剪、平移、旋轉、縮放和傾斜,并且隻需要定位網絡産生 6 個參數(的 6 個元素)。它允許裁剪,因為如果變換是收縮(即左側 2 × 2 子矩陣的行列式的幅度小于機關),則映射的規則網格将位于面積小于範圍的平行四邊形中。與恒等變換相比,這種變換對網格的影響如圖 3 所示。
圖 3:将參數化采樣網格應用于生成輸出的圖像的兩個示例。(a) 采樣網格是規則網格,其中是恒等變換參數。 (b) 采樣網格是用仿射變換扭曲規則網格的結果。
轉換類可能受到更多限制,例如用于注意力的轉換
允許通過改變和進行裁剪、平移和各向同性縮放。變換也可以更一般化,例如具有 8 個參數的平面投影變換、分段仿射或薄闆樣條。實際上,轉換可以具有任何參數化形式,隻要它在參數方面是可微的——這至關重要地允許梯度從樣本點反向傳播到定位網絡輸出。如果轉換以結構化的低維方式進行參數化,則可以降低配置設定給定位網絡的任務的複雜性。例如,一類結構化和可微分變換是注意力、仿射、投影和薄闆樣條變換的超集,是,其中是目标網格表示(例如,在(1)中,是齊次坐标中的規則網格),并且是由參數化的矩陣。在這種情況下,不僅可以學習如何預測樣本的,還可以學習手頭任務的。
3.3 Differentiable Image Sampling
為了對輸入特征圖執行空間變換,采樣器必須擷取一組采樣點 ,以及輸入特征圖,并生成采樣的輸出特征圖。
中的每個坐标定義了輸入中的空間位置,其中應用采樣核心來擷取輸出中特定像素的值。這可以寫成
其中和是定義圖像插值(例如雙線性)的通用采樣核心的參數,是輸入通道中位置 處的值,是輸出值對于通道中位置處的像素。請注意,輸入的每個通道的采樣都是相同的,是以每個通道都以相同的方式進行轉換(這保持了通道之間的空間一緻性)。
理論上,可以使用任何采樣核心,隻要可以針對和定義(子)梯度。例如,使用整數采樣核心将 (3) 簡化為
其中将舍入為最接近的整數,而是 Kronecker delta 函數。該采樣核心等同于僅将距離的最近像素處的值複制到輸出位置.。或者,可以使用雙線性采樣核心,給出
為了允許通過這種采樣機制反向傳播損失,我們可以定義關于和的梯度。對于雙線性采樣 (5),偏導數是
對于,與 (7) 類似。
這為我們提供了一個(子)可微分采樣機制,允許損失梯度不僅流回輸入特征圖(6),而且流回采樣網格坐标(7),是以傳回變換參數和定位網絡因為和可以很容易地從(1)推導出來。由于采樣函數的不連續性,必須使用子梯度。這種采樣機制可以在 GPU 上非常有效地實作,方法是忽略所有輸入位置的總和,而隻檢視每個輸出像素的核心支援區域。
3.4 Spatial Transformer Networks
定位網絡、網格生成器和采樣器的組合形成了空間變換器(圖 2)。這是一個獨立的子產品,可以在任何時候以任意數量放入 CNN 架構中,進而産生空間變換器網絡。該子產品的計算速度非常快,并且不會影響訓練速度,在使用時會導緻非常少的時間開銷,甚至由于可以應用于轉換器輸出的後續下采樣,可能會在注意力模型中加速。
在 CNN 中放置空間轉換器可以讓網絡學習如何主動轉換特征圖,以幫助在訓練期間最小化網絡的整體成本函數。在訓練期間,如何轉換每個訓練樣本的知識被壓縮并緩存在定位網絡的權重(以及空間變換器之前的層的權重)中。對于某些任務,将定位網絡的輸出轉發給網絡的其餘部分也可能很有用,因為它顯式地編碼了區域或目标的變換,是以也編碼了位姿。
也可以使用空間變換器對特征圖進行下采樣或過采樣,因為可以将輸出次元和定義為與輸入次元和不同。但是,對于具有固定的小空間支援的采樣核心(例如雙線性核心),使用空間變換器進行下采樣會導緻混疊效應。