選擇性的核心網絡
paper題目:Selective Kernel Networks
paper是南京理工大學發表在CVPR 2019的工作
paper連結
Code:連結
Abstract
在标準的卷積神經網絡(CNN)中,每層的人工神經元的感受野被設計成具有相同的大小。在神經科學界衆所周知,視覺皮層神經元的感受野大小受刺激的調節,這在建構CNN時很少被考慮。我們提出了一種CNN中的動态選擇機制,允許每個神經元根據輸入資訊的多個尺度來适應性地調整其感受野的大小。我們設計了一個叫做選擇性核(SK)單元的構件,其中具有不同核大小的多個分支在這些分支的資訊指導下,使用softmax注意力進行融合。對這些分支的不同關注産生了融合層中神經元的有效感受野的不同大小。多個SK單元被堆疊成一個深度網絡,稱為選擇性核網絡(SKNets)。在ImageNet和CIFAR基準上,我們的經驗表明,SKNet以較低的模型複雜度超越了現有的最先進的架構。詳細的分析表明,SKNet中的神經元可以捕獲不同尺度的目标物體,這驗證了神經元根據輸入自适應調整其感受野大小的能力。
1. Introduction
上個世紀,貓的初級視覺皮層(V1)中神經元的局部感受野(RF)[14]啟發了卷積神經網絡(CNN)[26]的建構,并且它繼續啟發了現代CNN的結構建構。例如,衆所周知,在視覺皮層中,同一區域(如V1區域)的神經元的RF大小是不同的,這使得神經元能夠在同一處理階段收集多尺度空間資訊。這種機制在最近的卷積神經網絡(CNNs)中被廣泛采用。一個典型的例子是InceptionNets[42, 15, 43, 41],其中一個簡單的串聯被設計為從 "inception "構件内的卷積核中聚集多尺度資訊。
然而,在設計CNN時,皮層神經元的其他一些RF特性還沒有被強調,其中一個特性就是RF大小的适應性變化。大量的實驗證據表明,視覺皮層中神經元的RF大小不是固定的,而是受刺激的調節。V1區神經元的經典RF(CRF)是由Hubel和Wiesel[14]發現的,是由單個定向條确定的。後來,許多研究(如[30])發現,CRF之外的刺激也會影響神經元的反應。這些神經元被稱為具有非經典RFs(nCRFs)。此外,nCRF的大小與刺激的對比度有關:對比度越小,有效的nCRF大小就越大[37]。令人驚訝的是,通過刺激nCRF一段時間,去除這些刺激後,神經元的CRF也會擴大[33]。所有這些實驗表明,神經元的RF大小不是固定的,而是受刺激調制的[38]。遺憾的是,在建構深度學習模型時,這一特性并沒有得到太多的關注。那些在同一層有多尺度資訊的模型,如InceptionNets,有一個固有的機制,可以根據輸入的内容調整下一個卷積層中神經元的RF大小,因為下一個卷積層會線性地聚合來自不同分支的多尺度資訊。但這種線性聚合的方法可能不足以為神經元提供強大的适應能力。
在本文中,我們提出了一種非線性方法,從多個核心中聚合資訊,實作神經元的自适應RF大小。我們引入了 “選擇性核心”(SK)卷積,它由三組運算符組成。分裂、融合和選擇。分裂運算符産生具有不同核心大小的多個路徑,對應于神經元的不同RF大小。融合運算符結合并彙總來自多條路徑的資訊,以獲得選擇權重的全局和綜合表示。選擇運算符根據選擇權重聚合不同大小的核心的特征圖。
SK卷積在計算上可以是輕量級的,并且隻在參數和計算成本上有輕微增加。我們表明,在ImageNet 2012資料集[35]上,SKNets優于之前最先進的模型,其模型複雜度相似。基于SKNet50,我們找到了SK卷積的最佳設定,并展示了每個元件的貢獻。為了證明其普遍适用性,我們還在較小的資料集CIFAR-10和100[22]上提供了令人信服的結果,并成功地将SK嵌入小型模型(如ShuffleNetV2[27])中。
為了驗證所提出的模型确實具有調整神經元RF大小的能力,我們通過放大自然圖像中的目标物體和縮小背景以保持圖像大小不變來模拟刺激。結果發現,當目标物體越來越大時,大多數神經元從較大的核心路徑收集的資訊越來越多。這些結果表明,所提出的SKNet中的神經元具有自适應的RF大小,這可能是該模型在物體識别方面的優異表現的基礎。
2. Related Work
多分支卷積網絡。Highway網絡[39]引入了跳過路徑和門控單元。雙分支結構減輕了訓練數百層網絡的難度。這個想法也被用于ResNet[9, 10],但跳過路徑是純恒等映射。除了恒等映射,搖擺網絡[7]和多殘差網絡[1]用更多的相同路徑擴充了主要的轉換。深度神經決策森林[21]形成了具有學習分裂函數的樹狀結構多分支原理。FractalNets[25]和Multilevel ResNets[52]的設計方式是可以将多條路徑進行分形和遞歸式擴充。InceptionNets[42, 15, 43, 41]用定制的核心過濾器仔細配置每個分支,以便聚合更多的資訊和多種特征。請注意,所提出的SKNets遵循InceptionNets的思想,對多個分支配置各種過濾器,但至少在兩個重要方面有所不同。1)SKNets的方案要簡單得多,不需要大量的定制設計;2)利用這些多分支的自适應選擇機制來實作神經元的自适應RF大小。
分組/深度/擴張卷積。分組卷積由于計算成本低而變得流行。用 G 表示組大小,那麼與普通卷積相比,參數個數和計算成本都将除以 G。它們首先在 AlexNet [23] 中采用,目的是将模型分布在更多的 GPU 資源上。令人驚訝的是,使用分組卷積,ResNeXts [47] 還可以提高準确性。這個 G 稱為“基數”,它與深度和寬度一起表征模型。
基于交錯分組卷積開發了許多緊湊模型,例如 IGCV1 [53]、IGCV2 [46] 和 IGCV3 [40]。分組卷積的一個特例是深度卷積,其中組數等于通道數。 Xception [3] 和 MobileNetV1 [11] 引入了depthwise separable convolution,将普通卷積分解為depthwise convolution 和pointwise convolution。在 MobileNetV2 [36] 和 ShuffleNet [54, 27] 等後續工作中驗證了深度卷積的有效性。除了分組/深度卷積之外,空洞卷積 [50, 51] 支援 RF 的指數擴充而不會丢失覆寫範圍。例如,具有擴張 2 的 3×3 卷積可以大約覆寫 5×5 濾波器的 RF,同時消耗不到一半的計算和記憶體。在 SK 卷積中,較大尺寸(例如,>1)的核心被設計為與分組/深度/擴張卷積內建,以避免大量開銷。
注意力機制。最近,注意力機制的好處已經在一系列的任務中顯示出來,從自然語言進行中的神經機器翻譯[2]到圖像了解中的圖像說明[49]。它偏重于最有資訊量的特征表達的配置設定[16, 17, 24, 28, 31],同時抑制不太有用的表達。注意力在最近的應用中被廣泛使用,如行人重識别[4]、圖像恢複[55]、文本抽象[34]和讀唇[48]。為了提高圖像分類的性能,Wang等人[44]提出了一個CNN中間階段之間的基線和掩碼注意力。一個沙漏子產品被引入以實作跨空間和通道次元的全局強調。此外,SENet[12]帶來了一個有效的、輕量級的門控機制,通過通道導向的導入來自我校準特征圖。除了通道之外,BAM[32]和CBAM[45]也以類似的方式引入空間注意力。相比之下,我們提出的SKNets是第一個通過引入注意力機制而明确關注神經元的自适應RF大小。
動态卷積。空間變換網絡 [18] 學習參數變換來扭曲特征圖,這被認為難以訓練。動态濾波器[20]隻能自适應地修改濾波器的參數,而無需調整核心大小。主動卷積[19]用偏移量增加了卷積中的采樣位置。這些偏移量是端到端學習的,但在訓練後變成靜态的,而在 SKNet 中,神經元的 RF 大小可以在推理過程中自适應地改變。可變形卷積網絡 [6] 進一步使位置偏移動态化,但它不像 SKNet 那樣聚合多尺度資訊。
3. Methods
3.1. Selective Kernel Convolution
為了使神經元能夠自适應地調整它們的 RF 大小,我們提出了一種自動選擇操作,即“選擇性核心”(SK)卷積,在具有不同核心大小的多個核心中。具體來說,我們通過三個運算符實作 SK 卷積——Split、Fuse 和 Select,如圖 1 所示,其中顯示了兩個分支的情況。是以在這個例子中,隻有兩個核心大小不同的核心,但是很容易擴充到多個分支的情況。
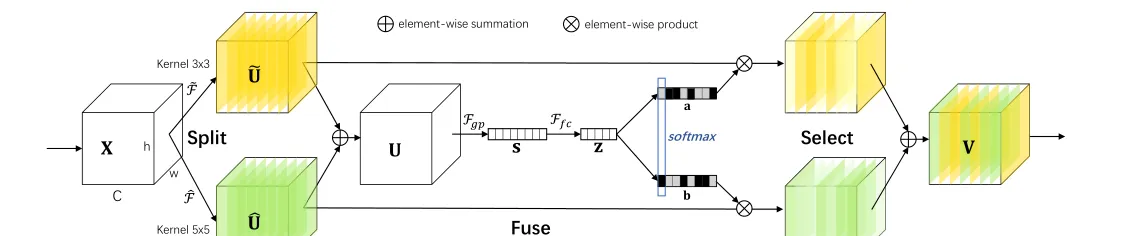
圖 1. 選擇性核心卷積。
拆分:對于任何給定的特征圖,預設情況下,我們首先進行兩個變換 和with kernel分别為3和5。請注意,和均由有效的分組/深度卷積、批量歸一化 [15] 和 ReLU [29] 函數依次組成。為了進一步提高效率,具有核心的傳統卷積被替換為具有核心和擴張大小 2 的擴張卷積。
Fuse:如引言中所述,我們的目标是使神經元能夠根據刺激内容自适應地調整其 RF 大小。其基本思想是使用門來控制來自多個分支的資訊流,這些分支攜帶不同規模的資訊進入下一層的神經元。
為了實作這個目标,門需要整合來自所有分支的資訊。我們首先通過元素求和融合來自多個(圖 1 中的兩個)分支的結果:
然後我們通過簡單地使用全局平均池化來嵌入全局資訊,以生成的通道統計。具體來說,的第個元素是通過在空間次元上縮小來計算的:
此外,還建立了一個緊湊的特征,以實作精确和自适應選擇的指導。這是通過一個簡單的全連接配接 (fc) 層實作的,通過降低次元來提高效率:
其中是 ReLU 函數 [29],表示批量歸一化 [15],。為了研究對模型效率的影響,我們使用一個縮減比來控制它的值:
其中表示的最小值(是我們實驗中的典型設定)。
選擇:跨通道的軟注意力用于自适應地選擇不同空間尺度的資訊,由緊湊的特征描述符引導。具體來說,softmax 運算符應用于通道數字:
其中和分别表示和的軟注意力向量。請注意,是的第行,是的第個元素,和也是如此。在有兩個分支的情況下,矩陣是備援的,因為。最終的特征圖是通過各種核心上的注意力權重獲得的:
其中。
![淺談使用Fiddler工具進行弱網測試[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)