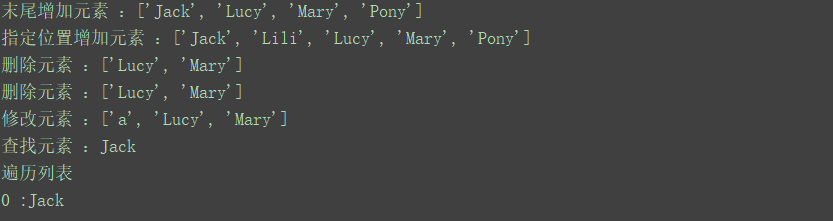
list=['Jack','Lucy','Mary']
list.append('Pony')
print("末尾增加元素 :{}".format(list))
list.insert(1,"Lili")
print("指定位置增加元素 :{}".format(list))
list=['Jack','Lucy','Mary']
list.remove('Jack')
print("删除元素 :{}".format(list))
list=['Jack','Lucy','Mary']
list.pop(0)
print("删除元素 :{}".format(list))
list=['Jack','Lucy','Mary']
list[0]='a'
print("修改元素 :{}".format(list))
list=['Jack','Lucy','Mary']
print("查找元素 :{}".format(list[0]))
print("周遊清單")
for l in list:
print("{} :{}".format(list.index(l),l))
複合資料類型,英文詞頻統計
2、元組
tup=('Jack','Lucy',0)
tup2=('Lili',)
tup3=tup+tup2
print("連接配接/增加元素 :{}".format(tup3))
tup=('Jack','Lucy',0)
print("通路元素 :tup[2]={},tup[0:1]={}".format(tup3[2],tup[0:2]))
tup=('Jack','Lucy',0)
print("删除元祖")
del tup
tup=('Jack','Lucy',0)
print("周遊元組:")
for t in tup:
print(t)
複合資料類型,英文詞頻統計
3、字典
dict={'Jack':90,'Mary':80,'Tony':70}
dict["abc"]=100
print("增加abc:{}".format(dict))
dict={'Jack':90,'Mary':80,'Tony':70}
del dict['Jack']
print("删除Jack:{}".format(dict))
dict={'Jack':90,'Mary':80,'Tony':70}
dict.pop('Tony')
print("删除Tony:{}".format(dict))
dict={'Jack':90,'Mary':80,'Tony':70}
dict['Tony']=99
print("修改Tony的值:{}".format(dict))
dict['a']=dict.pop('Jack')
print("修改Tony的鍵:{}".format(dict))
dict={'Jack':90,'Mary':80,'Tony':70}
print("查找Mary的值:{}".format(dict.get('Mary')))
print("周遊字典:")
for d in dict:
print("{} : {}".format(d,dict[d]))