機器之心報道
編輯:陳萍
強化學習應用廣泛,但為何泛化這麼難?如果要在現實世界的場景中部署強化學習算法,避免過度拟合至關重要。來自倫敦大學學院、UC 伯克利機構的研究者撰文對深度強化學習中的泛化進行了研究。
強化學習 (RL) 可用于自動駕駛汽車、機器人等一系列應用,其在現實世界中表現如何呢?現實世界是動态、開放并且總是在變化的,強化學習算法需要對環境的變化保持穩健性,并在部署期間能夠進行遷移和适應沒見過的(但相似的)環境。
然而,目前許多強化學習研究都是在 Atari 和 MuJoCo 等基準上進行的,其具有以下缺點:它們的評估政策環境和訓練環境完全相同;這種環境相同的評估政策不适合真實環境。
我們以下圖為例:下圖為三類環境(列)的可視化,涉及圖模型、訓練和測試分布以及示例基準(行)。經典 RL 專注于訓練和測試相同的環境(單例環境,第一列),但在現實世界中,訓練和測試環境不同,它們要麼來自相同的分布(IID 泛化環境,第二列),要麼來自不同的分布( OOD 泛化環境,第三列)。
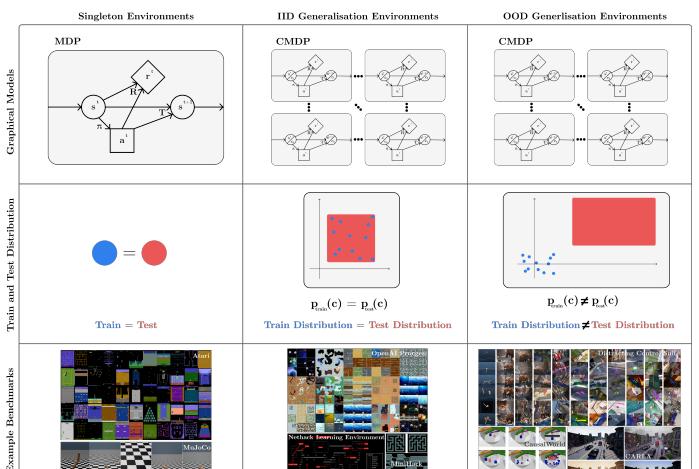
圖 1:強化學習泛化。
經典 RL(訓練和測試環境相同)與監督學習标準假設形成鮮明對比,在監督學習中,訓練集和測試集是不相交的,而對于 RL 來說,RL 政策要求訓練和測試環境相同,是以在評估時可能導緻模型過拟合。即使在稍微調整的環境執行個體上 RL 表現也不佳,并且在用于初始化沒見過的随機種子上失敗 [7, 8, 9, 10]。
目前,許多研究者已經意識到這個問題,開始專注于改進 RL 中的泛化。來自倫敦大學學院、UC 伯克利機構的研究者撰文《 A SURVEY OF GENERALISATION IN DEEP REINFORCEMENT LEARNING 》,對深度強化學習中的泛化進行了研究。

論文位址:https://arxiv.org/pdf/2111.09794v1.pdf
本文由 7 個章節組成:第 2 節中簡要描述了 RL 相關工作;第 3 節介紹了 RL 泛化中的形式(formalism)和術語;第 4 節研究者使用這種形式來描述目前 RL 中泛化基準,包括環境(第 4.1 節)和評估協定(第 4.2 節);第 5 節中研究者對泛化研究進行了分類和描述;第 6 節研究者對 RL 目前領域進行了批判性讨論,包括對未來工作關于方法和基準的建議,并總結了關鍵要點;第 7 節是全文總結。
本文主要貢獻包括:
該研究提出了一種形式和術語,以用于讨論泛化問題,這一工作是建立在之前研究 [12, 13, 14, 15, 16] 的基礎上進行的。本文将先前的工作統一成一個清晰的形式描述,這類問題在 RL 中被稱為泛化。
該研究提出了對現有基準的分類方法,可用于測試泛化。該研究的形式使我們能夠清楚地描述泛化基準測試和環境設計的純 PCG(Procedural Content Generation) 方法的弱點:完整的 PCG 環境會限制研究精度。該研究建議未來的環境應該使用 PCG 和可控變異因素的組合。
該研究建議對現有方法進行分類以解決各種泛化問題,其動機是希望讓從業者能夠輕松地選擇給定具體問題的方法,并使研究人員能夠輕松了解使用該方法的前景以及可以做出新穎和有用貢獻的地方。該研究對許多尚未探索的方法進行進一步研究,包括快速線上适應、解決特定的 RL 泛化問題、新穎的架構、基于模型的 RL 和環境生成。
該研究批判性地讨論了 RL 研究中泛化的現狀,推薦了未來的研究方向。特别指出,通過建構基準會促進離線 RL 泛化和獎勵函數進步,這兩者都是 RL 中重要的設定。此外,該研究指出了幾個值得探索的設定和評估名額:調查上下文效率和在持續的 RL 設定中的研究都是未來工作必不可少的領域。
以下為論文中摘取的部分内容。
論文概覽
在第 3 節中,研究者提出了一種用于了解和讨論 RL 泛化問題的形式。
監督學習中的泛化是一個被廣泛研究的領域,是以比 RL 中的泛化研究更深。在監督學習中,通常假設訓練和測試資料集中的資料點都是從相同的底層分布中抽取的。泛化性能與測試性能是同義詞,因為模型需要泛化到它在訓練期間從未見過的輸入。在監督學習中的泛化可定義為:
而在 RL 中,泛化的标準形式是馬爾可夫決策過程 (MDP)。MDP 中的标準問題是學習一個政策π(|s),該政策産生給定狀态下的行動分布,進而使 MDP 中政策的累積獎勵最大化:
其中π^ 是最優政策,Π是所有政策的集合,R: SR 是一個狀态的傳回,計算為:
強化學習中泛化基準
表 1 列出了在 RL 中可以進行測試泛化的可用環境,共 47 個,表中總結了每個環境的關鍵特性。
其中,Style 列:提供了對環境類型的粗略高層次描述;Contexts 列:在文獻中有兩種設計上下文集的方法,這些方法之間的關鍵差別是 context-MDP 建立是否對研究人員可通路和可見。第一種稱為 PCG,在 context-MDP 生成中依賴于單個随機種子來确定多個選擇;第二種方法對 context-MDP 之間的變化因素提供了更直接的控制,稱之為可控環境。Variation 列:描述了在一組 context MDP 中發生的變化。
泛化評估協定:事實上,在純 PCG 環境中,評估協定之間變化唯一有意義的因素是上下文效率限制。PCG 環境提供了三類評估協定,由訓練上下文集決定:單個上下文、一小組上下文或完整上下文集。這些分别在圖 2A、B 和 C 中進行了可視化。
可控環境評估協定:許多環境不僅使用 PCG,并且具有變化因子,可以由環境使用者控制。在這些可控環境中,評估協定範圍更廣。對于每個因素,我們可以為訓練上下文集選擇一個選項,然後在此範圍内或之外對測試上下文集進行采樣。選項範圍如圖 3 所示。
強化學習中的歸納方法
文中對處理 RL 中泛化的方法進行分類。當訓練和測試上下文集不相同時,RL 泛化問題就會出現。圖 4 是分類圖表。
在其他條件相同的情況下,訓練和測試環境越相似,RL 泛化差距越小,測試時間性能越高。通過将訓練環境設計為盡可能接近測試環境,可以增加這種相似性。是以,本文在增加相似性方法中,包括資料增強和域随機;環境生成;優化目标。
處理訓練和測試之間的差異:經過訓練的模型會依賴訓練中學習到的特征,但在測試環境中的一點改變就會影響泛化性能。在 5.2 節中,該研究回顧了處理訓練和測試環境特征之間存在差異的方法。
關于 RL 特定問題和改進:前兩節中的動機大多同樣适用于監督學習。然而,除了來自監督學習的泛化問題之外,RL 還存在抑制泛化性能的其他問題。在 5.3 節中,該研究針對這一問題進行了讨論,并且還讨論了純粹通過更有效地優化訓練集(至少在經驗上)來提高泛化的方法,這些方法不會導緻網絡過拟合。
更多細節,請參考原論文。