Reports from the Heart of the Machine
Editor: Chen Ping
Reinforcement learning is widely used, but why is generalization so difficult? If you want to deploy reinforcement learning algorithms in real-world scenarios, it is important to avoid overfitting. Researchers from University College London and UC Berkeley have written about generalization in deep reinforcement learning.
How does reinforcement learning (RL) perform in the real world for a range of applications, including self-driving cars and robotics? The real world is dynamic, open, and always changing, and reinforcement learning algorithms need to be robust to changes in the environment and be able to migrate and adapt to unseen (but similar) environments during deployment.
However, many of the current reinforcement learning studies are conducted on benchmarks such as Atari and MuJoCo, which have the following disadvantages: their evaluation strategy environment and training environment are exactly the same; this environment of the same evaluation strategy is not suitable for real environments.
Let's take the following diagram as an example: the following diagram is a visualization of three types of environments (columns) involving graph models, training and test distributions, and example benchmarks (rows). Classical RL focuses on training and testing the same environment (singleton environment, first column), but in the real world, training and testing environments are different, and they either come from the same distribution (IID generalization environment, second column) or from different distributions (OOD generalization environment, third column).
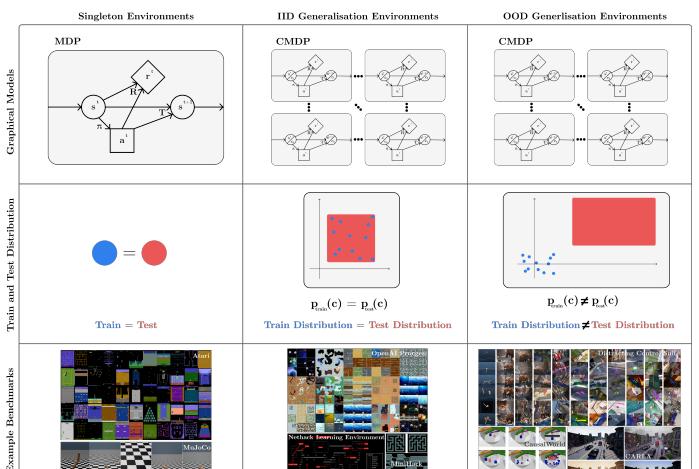
Figure 1: Reinforcement learning generalization.
Classical RL (training and testing environments are the same) contrasts with the supervised learning standard assumption that the training set and the test set are disjointed in supervised learning, whereas for RL the RL strategy requires the same training and testing environment, and therefore can lead to model overfitting when evaluated. RL performs poorly even on slightly tuned environmental instances and fails on random seeds used to initialize unseen [7, 8, 9, 10].
At present, many researchers have realized this problem and have begun to focus on improving generalization in RL. Researchers from University College London and UC Berkeley wrote "A SURVEY OF GENERALISATION IN DEEP REINFORCEMENT LEARNING" which studied generalization in deep reinforcement learning.

Address of the paper: https://arxiv.org/pdf/2111.09794v1.pdf
This article consists of seven chapters: Section 2 briefly describes the work related to RL; Section 3 describes the formalism and terminology in RL generalization; Section 4 researchers use this form to describe the current generalization benchmarks in RL, including the environment (Section 4.1) and evaluation protocols (Section 4.2); in Section 5 the researchers classify and describe the generalization study; and in Section 6 the researchers have a critical discussion of the current field of RL, including recommendations for methods and benchmarks for future work. And summarizes the key points; Section 7 is a full summary.
The main contributions to this article include:
The study proposes a form and terminology for discussion of generalization, a work that builds on previous studies [12, 13, 14, 15, 16]. This article summarizes the previous work into a clear form, and this type of problem is referred to in RL as generalization.
The study proposes a classification of existing benchmarks that can be used to test generalization. The form of the study allows us to clearly describe the weaknesses of the pure PCG (Procedural Content Generation) approach to generalization benchmarking and environmental design: a complete PCG environment limits the accuracy of the study. The study suggests that future environments should use a combination of PCG and controllable variability factors.
The study proposes to classify existing methods to solve various generalization problems, motivated by the hope that it will make it easy for practitioners to choose a method for a given specific problem, and that researchers will easily understand the prospects for using the method and where novel and useful contributions can be made. The study takes a closer look at many approaches that have yet to be explored, including rapid online adaptation, solving specific RL generalization problems, novel architectures, model-based RL, and environmental generation.
The study critically discusses the current state of generalization in RL research and recommends future research directions. In particular, building benchmarks promotes offline RL generalization and reward function advancement, both of which are important settings in RL. In addition, the study identifies several settings and evaluation metrics worth exploring: survey context efficiency and research in ongoing RL settings are both areas essential for future work.
The following are some excerpts from the paper.
Overview of papers
In Section 3, the researchers proposed a form for understanding and discussing RL generalization issues.
Generalization in supervised learning is a widely studied field and therefore deeper than generalization in RL. In supervised learning, it is often assumed that the data points in the training and test datasets are extracted from the same underlying distribution. Generalization performance is synonymous with test performance because the model needs to generalize to inputs that it has never seen during training. Generalization in supervised learning can be defined as:
In RL, the standard form of generalization is the Markov Decision Process (MDP). The standard problem in MDP is learning a strategy π (|s) that produces a distribution of actions in a given state, thereby maximizing the cumulative reward of the strategy in the MDP:
where π^ is the optimal policy, Π is the set of all policies, and R:SR is the return of a state that is calculated as:
Generalization benchmarks in reinforcement learning
Table 1 lists 47 of the 47 environments available for test generalization in RL, and summarizes the key characteristics of each environment.
Among them, the Style column: provides a rough, high-level description of the type of environment; the Contexts column: There are two ways to design context sets in the literature, and the key difference between these methods is whether the context-MDP creation is accessible and visible to researchers. The first, called PCG, relies on a single random seed to determine multiple choices in context-MDP generation; the second method provides more direct control over the factors that vary between context-MDP, called a controlled environment. Variation column: Describes the changes that occur in a set of context MDPs.
Generalized evaluation protocols: In fact, in a pure PCG environment, the only meaningful factor in the variation between evaluation protocols is contextual efficiency limitations. The PCG environment provides three types of evaluation protocols, determined by the training context set: a single context, a small set of contexts, or a full set of contexts. These are visualized in Figures 2A, B, and C, respectively.
Controlled Environmental Assessment Protocols: Many environments not only use PCGs, but also have a factor of variation that can be controlled by the user of the environment. In these controlled environments, the scope of the evaluation protocol is broader. For each factor, we can select an option for the training context set and then sample the test context set within or outside this range. The range of options is shown in Figure 3.
Inductive methods in reinforcement learning
The article classifies the methods used to handle generalization in RL. When the training and test context sets are not the same, the RL generalization problem occurs. Figure 4 is a classification chart.
Otherwise equal, the more similar the training and test environments, the smaller the RL generalization gap and the higher the test time performance. This similarity can be increased by designing the training environment to be as close to the test environment as possible. Therefore, this paper includes data enhancement and domain randomization, environment generation, and optimization goals.
Handle the difference between training and testing: A trained model relies on features learned in training, but a small change in the test environment can affect generalization performance. In Section 5.2, the study reviewed ways to deal with differences between training and test environment characteristics.
Regarding RL-specific issues and improvements: Most of the motivations in the first two sections apply equally to supervised learning. However, in addition to the generalization problems from supervised learning, RL has other problems with suppressing generalization performance. In Section 5.3, the study addresses this issue and also discusses methods to improve generalization purely by optimizing the training set more efficiently (at least empirically) without resulting in network overfitting.
For more details, please refer to the original paper.