作者 | Nitish Kumar
譯者 | 馬可薇
策劃 | 淩敏
MI 攻擊
近幾年,模型反演(Model inversion, MI)攻擊備受關注。MI 攻擊是指濫用經過訓練的機器學習(ML)模型,并借此推斷模型原始訓練資料中的敏感資訊。遭受攻擊的模型經常會在反演期間被當機,進而被攻擊者用于引導訓練生成對抗網絡之類的生成器,最終重模組化型原始訓練資料的分布。
是以,審查 MI 技術對正确建立模型保護機制至關重要。
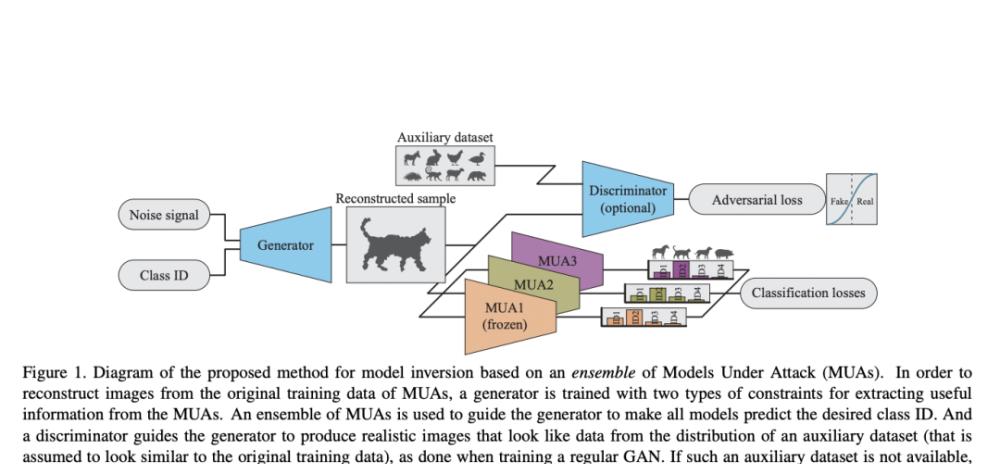
借助單一模型高品質地重建訓練資料的過程非常複雜,然而,現有的 MI 相關文獻并沒有考慮到多個模型同時被攻擊的可能性,這類情況中攻擊者可以找到額外的資訊和切入點。
如果攻擊成功,原始訓練樣本洩露,而其訓練資料中如果包含個人的身份資訊,那麼資料集中的資料本體的隐私将會受到威脅。
內建反演技術
蘋果的研究人員提出了一種內建反演的技術,借助生成器來估計模型原始訓練資料的分布,而該生成器則被限制在一系列共享對象或實體的訓練模型之中。
對比使用單一機器學習模型的 MI,使用該技術生成的樣本品質得到了顯著的提升,并具備了區分資料集實體間屬性的能力。這證明了如果借助與預期訓練結果相類似的輔助資料集,可以在不使用任何資料集的情況下依舊可以得到高品質結果,改善反演的結果。通過深入研究內建中模型多樣性對結果的影響,并添加多重限制以激勵重建樣本獲得高精确度和高激活度,訓練圖檔的重建準确程度得到了提升。
對比針對單一模型的 MI 攻擊,該研究所提出的模型在重建性能上展現了明顯的提升。該研究不僅利用最遠模型采樣法(FMS)進行內建中模型多樣性的優化,還建立了一個模型間等級對應關系明确的反演內建,模型的輸出向量中的增強資訊也被用來生成更優的限制條件,以更好地确定目标品質的高低。
通過随機訓練的形式,小批量随機梯度下降(SGD)這類的主流動态卷積神經網絡(DCNN),可以使用任意的大型資料集進行訓練。DCNN 模型對訓練資料集中最初的随機權重和統計上的噪音非常敏感,而由于學習算法的随機性,同一訓練集可能會生成側重特征不同的模型。是以,為減少差異性,研究者一般會使用內建學習,一種簡單的技巧來提升 DCNN 辨識式訓練的性能。

雖然這篇論文是以內建學習為基礎進行的研究,但論文對“內建”一詞卻有不同的定義。
若想成功對模型進行反演,攻擊者不能假定目标模型一定是通過內建學習進行訓練的,但他們卻可以通過搜集有關聯的模型搭建一個攻擊模型的內建。換句話來說,在“內建反演攻擊”這個語境下,“內建”不是要求模型一定要經過內建訓練,而是指攻擊者從各種來源所收集到相關模型的集合。
舉例來說,研究者可以通過不斷收集新的訓練資料,對目前模型進行訓練并更新結果,而攻擊者則可以将這些模型收集為一個集合并加以利用。
借助該政策,無資料的 MNIST 手寫數字的反演準确率提升了 70.9%,而基于輔助資料的試驗準确率則提高了 17.9%;對比基準實驗,人臉反演的準确率提升了 21.1%。論文的目标是,以更系統的方式對現有模型反演政策進行評估。在未來的研究中,需以針對這類內建的模型反演攻擊開發相應的保護機制為重點。
結 論
論文中提出的集合反演技術,可以利用機器學習模型集合中的多樣性特質提升模型反演的性能表現;通過結合 one-hot 損失和最大化輸出激活損失函數,讓樣本品質得到了更進一層的提升。除此之外,過濾掉攻擊模型中含有較小最大化激活的生成樣本也可以讓反演表現更加突出。同時,為确定目标模型的多樣性對集合反演性能的影響,研究者深入探索研究了各種差異下目标模型的表現情況。
https://www.marktechpost.com/2021/11/27/apple-researchers-propose-a-method-for-reconstructing-training-data-from-diverse-machine-learning-models-by-ensemble-inversion