Author | Nitish Kumar
Translated by | Marco Wei
Planning | Ling Min
MI attacks
In recent years, Model inversion (MI) attacks have attracted much attention. MI attacks are the misuse of a trained machine learning (ML) model and thereby infer sensitive information from the model's raw training data. Attacked models are often frozen during inversion, which is used by attackers to guide training to generate generators such as adversarial networks, and ultimately reconstruct the distribution of the model's original training data.
Therefore, reviewing MI technology is critical to properly establishing model protection mechanisms.
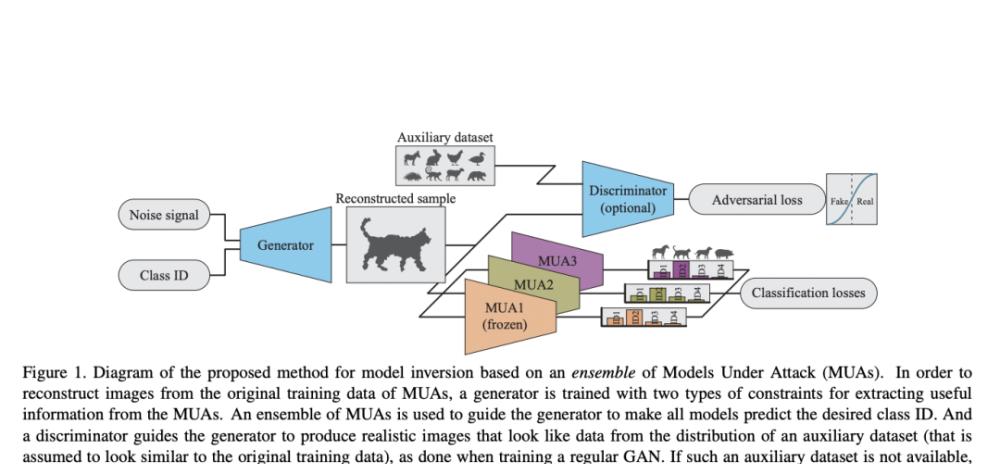
The process of reconstructing training data with high quality with a single model is complex, however, the existing MI literature does not take into account the possibility of multiple models being attacked at the same time, in which the attacker can find additional information and entry points.
If the attack is successful, the original training sample is leaked, and if the training data contains personal identity information, the privacy of the data body in the dataset will be threatened.
Integrated inversion technology
Apple's researchers have come up with a technique for integrating inversion to estimate the distribution of the model's original training data with the help of a generator that is limited to a range of training models that share objects or entities.
Compared with MI using a single machine learning model, the quality of the samples generated using this technique has been significantly improved, and the ability to distinguish between attributes of dataset entities has been improved. This proves that with the help of auxiliary datasets similar to the expected training results, high-quality results can be obtained without using any datasets, improving the results of inversion. The reconstruction accuracy of the training image was improved by delving into the effect of model diversity on the outcome in the integration and adding multiple restrictions to incentivize the reconstruction samples to obtain high accuracy and high activation.
Compared with MI attacks against a single model, the model proposed by the institute shows a significant improvement in reconstruction performance. The study not only uses the Farthest Model Sampling Method (FMS) to optimize the diversity of models in the integration, but also creates an inversion integration with a clear hierarchical correspondence between models, and the enhancement information in the output vector of the model is also used to generate better constraints to better determine the level of the target quality.
Mainstream dynamic convolutional neural networks (DCNNs) such as small-batch stochastic gradient descent (SGD) can be trained using arbitrary large data sets in the form of random training. DCNN models are very sensitive to the initial random weights and statistical noise in the training dataset, and due to the randomness of the learning algorithm, the same training set may produce models with different features. Therefore, to reduce variability, researchers generally use integrated learning, a simple technique, to improve the performance of DCNN discrimination training.

Although the paper is based on ensemble learning, the paper has a different definition of the term "integration."
To successfully invert a model, attackers cannot assume that the target model must have been trained through integration learning, but they can build an integration of an attack model by collecting associated models. In other words, in the context of "integrated inversion attack", "integration" does not require that the model must be integrated training, but refers to the collection of related models collected by the attacker from various sources.
For example, researchers can train and update the results of current models by continuously collecting new training data, while attackers can collect these models into a collection and exploit them.
With this strategy, the accuracy of mnIST handwritten digits without data was improved by 70.9%, compared with 17.9% of the test based on auxiliary data, and the accuracy of face inversion was improved by 21.1% compared to the benchmark experiment. The goal of the paper is to evaluate existing model inversion strategies in a more systematic manner. In future research, the focus will be on developing appropriate protection mechanisms for such integrated model inversion attacks.
Conclusion
The set inversion technique proposed in the paper can use the diversity characteristics in the machine learning model set to improve the performance performance of model inversion, and the sample quality is further improved by combining one-hot loss and maximizing output activation loss function. In addition, filtering out the generated samples in the attack model that contain smaller maximization activations can also make the inversion more prominent. At the same time, in order to determine the influence of the diversity of the target model on the performance of the set inversion, the researchers deeply explored and studied the performance of the target model under various differences.
https://www.marktechpost.com/2021/11/27/apple-researchers-propose-a-method-for-reconstructing-training-data-from-diverse-machine-learning-models-by-ensemble-inversion