本节书摘来自华章社区《spark核心技术与高级应用》一书中的第2章,第2.3节运行spark应用程序,作者于俊 向海 代其锋 马海平,更多章节内容可以访问云栖社区“华章社区”公众号查看
2.3 运行spark应用程序
运行spark应用程序主要包括local模式运行、standalone模式运行、yarn模式运行、mesos模式运行(参考官方文档)。
2.3.1 local模式运行spark应用程序
local模式运行spark应用程序是最简单的方式,以计算圆周率的程序为例,进入安装主目录,如spark-1.5.0,执行命令:
2.3.2 standalone模式运行spark应用程序
spark独立模式下应用程序的运行以及资源调度、监控和日志等内容会在接下来做简单的介绍。
1.?spark-shell运行应用程序
在spark集群上运行应用程序,需要将master的spark://ip:port传递给sparkcontext构造函数。
在集群上运行交互式的spark命令spark-shell,该命令将会用spark-env.sh中的spark_master_ip和spark_master_port自动设置master。
另外,还可以通过传递一个--cores来控制spark-shell在集群上使用的核心的数目。
2.?spark-submit启动应用程序
spark-submit脚本提供了一种向集群提交spark应用程序的最直接的方法,对于一个独立部署模式的集群,spark目前支持client部署模式,即在提交应用的客户端进程中部署driver。
如果应用程序通过spark-submit启动,那么应用程序的jar包将会自动地分配给所有的worker节点;对于任何其他运行应用程序时需要依赖的jar包,可以通过-jar声明,jar包名之间用逗号隔开。
以sparkpi为例,提交应用程序命令如下:
其中,spark-submit为提交spark任务的脚本,--class org.apache.spark.examples.sparkpi为spark项目包中指定运行的类的全路径。--master spark://$your_master_ip:7077为主节点的路径和端口号。$your_spark_home/lib/spark-examples-1.5.0-hadoop2.3.0.jar是spark项目程序包的路径。
直接运行即可验证spark在standalone模式下的计算圆周率的程序。如果启动上述应用程序成功,则执行结果如下:
除此之外,还可以通过配置集群上的spark.deploy.defaultcores来改变应用程序使用的默认值,而不必设置spark.cores.max,需要在spark-env.sh中加入以下内容:
export spark_master_opts="-dspark.deploy.defaultcores="
当用户不会在共享集群上独立配置cpu核数最大值的时候,这显得特别重要。
4.监控和日志
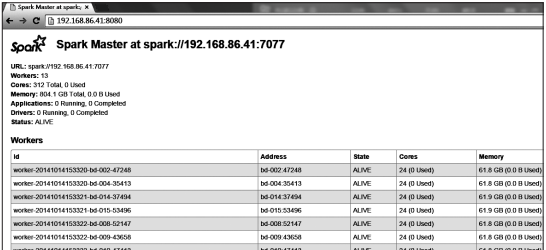
spark独立部署模式提供了一个基于web的用户接口,监控集群运行状况。master和每一个worker都会有一个webui来显示集群的统计信息。默认情况下,可以通过8080端口访问master的webui。
另外,每个slave节点上作业运行的日志也会详细地记录到默认的$spark_home/work目录下每个作业会对应两个文件:stdout和stderr,包含了控制台上所有的历史输出。
如图2-2所示,本书所用数据平台是通过$your_spark_master_ip:8080访问集群统计信息情况。
2.3.3 yarn模式运行spark
spark 0.6版本以后,加入了对在hadoop yarn上运行的支持,并在之后发布版本中不断演进,逐渐发展成spark应用程序运行的主要模式。
hadoop与spark部署完毕后,即可在yarn上运行spark程序。其任务提交的方式与独立模式类似,只是工作原理有一些不同。
(1)在yarn上启动spark应用
在yarn上启动spark应用有两种模式:yarn-cluster模式和yarn-client模式。
在yarn-cluster模式下,框架会在集群中启动的driver程序;
在yarn-client模式中,框架会在client端启动driver程序。在yarn中,resourcemanager的地址是从hadoop配置中选取的。因此,master参数可以简单配置为yarn-client或yarn-cluster。
要在yarn-cluster模式下调用spark应用,示例如下:
首先启动一个application master的客户程序,之后sparkpi将作为application master的一个子进程运行。
client会周期性地检查application master以获得状态更新,当应用程序运行结束时,client会立刻退出。
要以yarn-client模式启动一个spark应用,操作相同,用“yarn-client”替换“yarn-cluster”即可。
在yarn模式下,通过spark-submit提交任务应用程序,示例如下:
直接运行上述程序即可测试spark在yarn模式下计算圆周率的程序。
(2)添加其他的jar包
在yarn-cluster模式下,driver和client运行于不同的机器,sparkcontext.addjar不会作用于client本地文件。要使sparkcontext.addjar可使用client的本地文件,在启动指令中的--jars选项中加入文件。
(3)监控和日志
如图2-3所示,本书所用数据平台是通过$your_master_ip:8088访问集群统计信息情况。
2.3.4 应用程序提交和参数传递
提交任务是spark运行的起步,理解任务提交时不同参数的含义十分重要。

执行过程中,需要注意以下情况:
1)每个应用程序都会获得自己拥有的executor进程,这些进程的生命周期持续在整个应用运行期间,并以多线程的方式执行任务。无论是在driver驱动程序,还是executor执行进程,都能很好地隔离应用程序,如果没有将数据写到外部存储,该数据就不能被其他spark应用共享。
2)spark对集群管理器是不可知的,只要spark能够获取executor进程,并且这些executor之间可以相互通信,spark不关注集群管理器是否支持其他的业务,如yarn同时支持mapreduce程序的运行。
3)因为driver负责与集群上的任务交互,所以driver应该运行于距离worker节点近的地方,最好在同一个本地局域网之中。如果想要给集群发送远程请求,那么请为driver安装rpc协议并从附近提交,而不是在远离worker节点的地方运行driver。
2.配置参数传递
在sparkconf中显式配置的参数具有最高优先级,然后是传递给spark-submit的标志位,最后是默认属性配置文件中的值。
如果没有在sparkconf中显示配置,又不想在spark-submit中提交,可以通过默认属性配置文件获取值。spark-submit脚本可以从属性文件中加载spark配置值,并将它们传递给应用程序。
默认情况下,spark-submit脚本将会从spark目录下的conf/spark-defaults.conf中读取配置选项。例如,如果spark的master属性已经设置,spark-submit提交时可以省略--master标志。
如果应用程序代码依赖于其他的项目,需要将它们与应用程序一起打包,以便应用程序的代码可以分发到spark集群之上。为此,需要创建一个包含应用程序代码和其依赖的jar包(当创建jar包时,需要将spark和hadoop作为提供依赖项;这两者不需要被打入包中,在运行时由集群管理器提供加载)。
一旦拥有jar包,就可以在调用bin/spark-submit脚本时传递jar包。应用程序的jar包和所有在--jars选项中的jar包都会被自动地传递到集群。spark使用下面的url支持按不同的策略散播的jar包。
f?ile:driver的http文件服务器提供了绝对路径和f?ile:// uri,所有的executor节点从driver的http服务器处获得文件。
hdfs:从hdfs的uri获取文件和jar包。
local以每个worker节点相同的local:/开头的uri文件。
在executor节点上的每个sparkcontext对象的jar包和文件会被复制到工作目录下。这可能会占用大量的空间,并且需要被及时清除。在yarn集群上,清除是自动执行的。在standalone模式部署集群上,自动清除可以通过spark.worker.cleamup.appdatattl属性配置。
当在yarn-cluster模式下对本地文件使用--jars选项时,该选项允许你使用sparkcontext.addjar函数。若对于hdfs、http、https或ftp文件,则不必使用。