本節書摘來自華章社群《spark核心技術與進階應用》一書中的第2章,第2.3節運作spark應用程式,作者于俊 向海 代其鋒 馬海平,更多章節内容可以通路雲栖社群“華章社群”公衆号檢視
2.3 運作spark應用程式
運作spark應用程式主要包括local模式運作、standalone模式運作、yarn模式運作、mesos模式運作(參考官方文檔)。
2.3.1 local模式運作spark應用程式
local模式運作spark應用程式是最簡單的方式,以計算圓周率的程式為例,進入安裝主目錄,如spark-1.5.0,執行指令:
2.3.2 standalone模式運作spark應用程式
spark獨立模式下應用程式的運作以及資源排程、監控和日志等内容會在接下來做簡單的介紹。
1.?spark-shell運作應用程式
在spark叢集上運作應用程式,需要将master的spark://ip:port傳遞給sparkcontext構造函數。
在叢集上運作互動式的spark指令spark-shell,該指令将會用spark-env.sh中的spark_master_ip和spark_master_port自動設定master。
另外,還可以通過傳遞一個--cores來控制spark-shell在叢集上使用的核心的數目。
2.?spark-submit啟動應用程式
spark-submit腳本提供了一種向叢集送出spark應用程式的最直接的方法,對于一個獨立部署模式的叢集,spark目前支援client部署模式,即在送出應用的用戶端程序中部署driver。
如果應用程式通過spark-submit啟動,那麼應用程式的jar包将會自動地配置設定給所有的worker節點;對于任何其他運作應用程式時需要依賴的jar包,可以通過-jar聲明,jar包名之間用逗号隔開。
以sparkpi為例,送出應用程式指令如下:
其中,spark-submit為送出spark任務的腳本,--class org.apache.spark.examples.sparkpi為spark項目包中指定運作的類的全路徑。--master spark://$your_master_ip:7077為主節點的路徑和端口号。$your_spark_home/lib/spark-examples-1.5.0-hadoop2.3.0.jar是spark項目程式包的路徑。
直接運作即可驗證spark在standalone模式下的計算圓周率的程式。如果啟動上述應用程式成功,則執行結果如下:
除此之外,還可以通過配置叢集上的spark.deploy.defaultcores來改變應用程式使用的預設值,而不必設定spark.cores.max,需要在spark-env.sh中加入以下内容:
export spark_master_opts="-dspark.deploy.defaultcores="
當使用者不會在共享叢集上獨立配置cpu核數最大值的時候,這顯得特别重要。
4.監控和日志
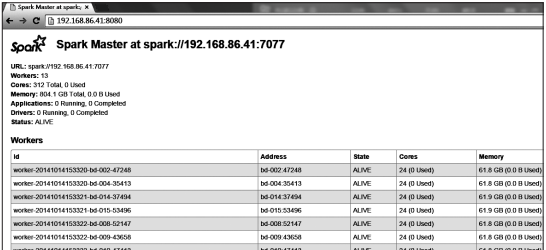
spark獨立部署模式提供了一個基于web的使用者接口,監控叢集運作狀況。master和每一個worker都會有一個webui來顯示叢集的統計資訊。預設情況下,可以通過8080端口通路master的webui。
另外,每個slave節點上作業運作的日志也會詳細地記錄到預設的$spark_home/work目錄下每個作業會對應兩個檔案:stdout和stderr,包含了控制台上所有的曆史輸出。
如圖2-2所示,本書所用資料平台是通過$your_spark_master_ip:8080通路叢集統計資訊情況。
2.3.3 yarn模式運作spark
spark 0.6版本以後,加入了對在hadoop yarn上運作的支援,并在之後釋出版本中不斷演進,逐漸發展成spark應用程式運作的主要模式。
hadoop與spark部署完畢後,即可在yarn上運作spark程式。其任務送出的方式與獨立模式類似,隻是工作原理有一些不同。
(1)在yarn上啟動spark應用
在yarn上啟動spark應用有兩種模式:yarn-cluster模式和yarn-client模式。
在yarn-cluster模式下,架構會在叢集中啟動的driver程式;
在yarn-client模式中,架構會在client端啟動driver程式。在yarn中,resourcemanager的位址是從hadoop配置中選取的。是以,master參數可以簡單配置為yarn-client或yarn-cluster。
要在yarn-cluster模式下調用spark應用,示例如下:
首先啟動一個application master的客戶程式,之後sparkpi将作為application master的一個子程序運作。
client會周期性地檢查application master以獲得狀态更新,當應用程式運作結束時,client會立刻退出。
要以yarn-client模式啟動一個spark應用,操作相同,用“yarn-client”替換“yarn-cluster”即可。
在yarn模式下,通過spark-submit送出任務應用程式,示例如下:
直接運作上述程式即可測試spark在yarn模式下計算圓周率的程式。
(2)添加其他的jar包
在yarn-cluster模式下,driver和client運作于不同的機器,sparkcontext.addjar不會作用于client本地檔案。要使sparkcontext.addjar可使用client的本地檔案,在啟動指令中的--jars選項中加入檔案。
(3)監控和日志
如圖2-3所示,本書所用資料平台是通過$your_master_ip:8088通路叢集統計資訊情況。
2.3.4 應用程式送出和參數傳遞
送出任務是spark運作的起步,了解任務送出時不同參數的含義十分重要。

執行過程中,需要注意以下情況:
1)每個應用程式都會獲得自己擁有的executor程序,這些程序的生命周期持續在整個應用運作期間,并以多線程的方式執行任務。無論是在driver驅動程式,還是executor執行程序,都能很好地隔離應用程式,如果沒有将資料寫到外部存儲,該資料就不能被其他spark應用共享。
2)spark對叢集管理器是不可知的,隻要spark能夠擷取executor程序,并且這些executor之間可以互相通信,spark不關注叢集管理器是否支援其他的業務,如yarn同時支援mapreduce程式的運作。
3)因為driver負責與叢集上的任務互動,是以driver應該運作于距離worker節點近的地方,最好在同一個本地區域網路之中。如果想要給叢集發送遠端請求,那麼請為driver安裝rpc協定并從附近送出,而不是在遠離worker節點的地方運作driver。
2.配置參數傳遞
在sparkconf中顯式配置的參數具有最高優先級,然後是傳遞給spark-submit的标志位,最後是預設屬性配置檔案中的值。
如果沒有在sparkconf中顯示配置,又不想在spark-submit中送出,可以通過預設屬性配置檔案擷取值。spark-submit腳本可以從屬性檔案中加載spark配置值,并将它們傳遞給應用程式。
預設情況下,spark-submit腳本将會從spark目錄下的conf/spark-defaults.conf中讀取配置選項。例如,如果spark的master屬性已經設定,spark-submit送出時可以省略--master标志。
如果應用程式代碼依賴于其他的項目,需要将它們與應用程式一起打包,以便應用程式的代碼可以分發到spark叢集之上。為此,需要建立一個包含應用程式代碼和其依賴的jar包(當建立jar包時,需要将spark和hadoop作為提供依賴項;這兩者不需要被打入包中,在運作時由叢集管理器提供加載)。
一旦擁有jar包,就可以在調用bin/spark-submit腳本時傳遞jar包。應用程式的jar包和所有在--jars選項中的jar包都會被自動地傳遞到叢集。spark使用下面的url支援按不同的政策散播的jar包。
f?ile:driver的http檔案伺服器提供了絕對路徑和f?ile:// uri,所有的executor節點從driver的http伺服器處獲得檔案。
hdfs:從hdfs的uri擷取檔案和jar包。
local以每個worker節點相同的local:/開頭的uri檔案。
在executor節點上的每個sparkcontext對象的jar包和檔案會被複制到工作目錄下。這可能會占用大量的空間,并且需要被及時清除。在yarn叢集上,清除是自動執行的。在standalone模式部署叢集上,自動清除可以通過spark.worker.cleamup.appdatattl屬性配置。
當在yarn-cluster模式下對本地檔案使用--jars選項時,該選項允許你使用sparkcontext.addjar函數。若對于hdfs、http、https或ftp檔案,則不必使用。