本节书摘来异步社区《hadoop海量数据处理:技术详解与项目实战》一书中的第3章,第3.3节,作者: 范东来 责编: 杨海玲,更多章节内容可以访问云栖社区“异步社区”公众号查看。
hadoop海量数据处理:技术详解与项目实战
hdfs提供给hdfs客户端访问的方式多种多样,用户可以根据不同的情况选择不同的方式。
hadoop自带一组命令行工具,而其中有关hdfs的命令是其工具集的一个子集。命令行工具虽然是最基础的文件操作方式,但却是最常用的。作为一名合格的hadoop开发人员和运维人员,熟练掌握是非常有必要的。
执行hadoop dfs命令可以显示基本的使用信息。
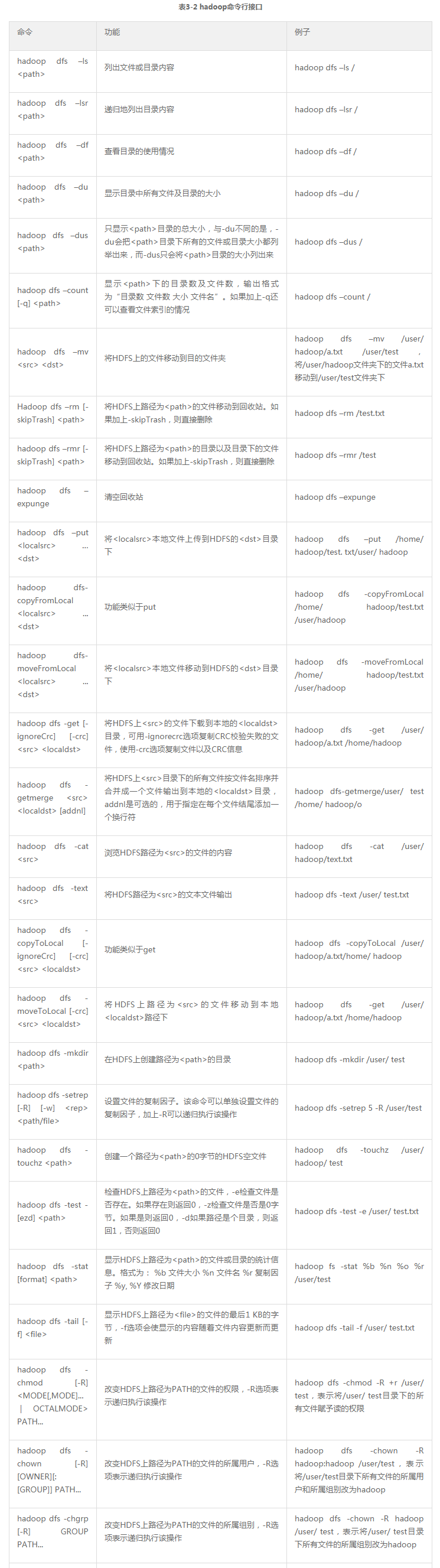
表3-2列出了hadoop命令行接口,并用例子说明各自的功能。
本地访问hdfs最主要的方式是hdfs提供的java应用程序接口,其他的访问方式都建立在这些应用程序接口之上。为了访问hdfs,hdfs客户端必须拥有一份hdfs的配置文件,也就是hdfs-site.xml文件,以获取namenode的相关信息,每个应用程序也必须能访问hadoop程序库jar文件,也就是在$hadoop_home、$hadoop_home/lib下面的jar文件。
hadoop是由java编写的,所以通过java api可以调用所有的hdfs的交互操作接口,最常用的是filesystem类,它也是命令行hadoop fs的实现,其他接口在这一节也会有 介绍。
1.java.net.url
先来看一个例子,如代码清单3-1所示。
代码清单3-1 java.net.url示例
编译代码清单3-1所示的代码,导出为xx.jar文件,执行命令:
执行完成后,屏幕上输出hdfs的文件/user/hadoop/test的文件内容。
该程序是从hdfs读取文件的最简单的方式,即用java.net.url对象打开数据流。代码中,静态代码块的作用是让java程序识别hadoop的hdfs url。
2.org.apache.hadoop.fs.filesystem
虽然上面的方式是最简单的方式,但是在实际开发中,访问hdfs最常用的类还是filesystem类。
(1)读取文件
读取文件的示例如代码清单3-2所示。
代码清单3-2 读取文件示例
编译代码3-2,导出为xx.jar文件,上传至集群任意一节点,执行命令:
执行完成后控制台会输出文件内容。
filesystem类的实例获取是通过工厂方法:
其中configuration对象封装了hdfs客户端或者hdfs集群的配置,该方法通过给定的uri方案和权限来确定要使用的文件系统。得到filesystem实例之后,调用open()函数获得文件的输入流:
方法返回hadoop独有的fsdatainputstream对象。
(2)写入文件
写入文件的示例如代码清单3-3所示。
代码清单3-3 写入文件示例
编译代码清单3-3所示的代码,导出为xx.jar文件,上传至集群任意一节点,执行命令:
hadoop jar xx.jar com.hdfsclient.filecopyfromlocal
filesystem实例的create()方法返回fsdataoutputstream对象,与fsdatainputstream类不同的是,fsdataoutputstream不允许在文件中定位,这是因为hdfs只允许一个已打开的文件顺序写入,或在现有文件的末尾追加数据。
(3)创建hdfs的目录
创建hdfs目录的示例如代码清单3-4所示。
代码清单3-4 创建hdfs目录示例
编译代码清单3-4所示的代码,导出为xx.jar文件,上传至集群任意一节点,执行命令:
运行完成后可以用命令hadoop dfs -ls验证目录是否创建成功。
(4)删除hdfs上的文件或目录
删除hdfs上的文件或目录的示例如代码清单3-5所示。
代码清单3-5 删除hdfs上的文件或目录示例
编译代码清单3-5所示的代码,导出为xx.jar文件,上传至集群任意一节点,执行命令:
如果需要递归删除文件夹,则需将fs.delete(arg0, arg1)方法的第二个参数设为true。
(5)查看文件是否存在
查看文件的示例如代码清单3-6所示。
代码清单3-6 查看文件示例
编译代码清单3-6所示的代码,导出为xx.jar文件,上传至集群任意一台节点,执行命令:
(6)列出目录下的文件或目录名称
列出目录下的文件或目录名称的示例如代码清单3-7所示。
代码清单3-7 列出目录下的文件或目录名称示例
编译代码清单3-7所示的代码,导出为xx.jar文件,上传至集群任意一节点,执行命令:
运行后,控制台会打印出/user目录下的目录名称或文件名。
(7)文件存储的位置信息
文件存储的位置信息的示例如代码清单3-8所示。
代码清单3-8 文件存储的位置信息示例
编译代码清单3-8所示的代码,导出为xx.jar文件,上传至集群任意一节点,执行命令:
前面提到过,hdfs的存储由datanode的块完成,执行成功后,控制台会输出:
表示该文件被分为3个数据块存储,存储的位置分别为slave1、slave2、slave3。
3.sequencefile
sequecefile是hdfs api提供的一种二进制文件支持,这种二进制文件直接将对序列化到文件中,所以sequencefile是不能直接查看的,可以通过hadoop dfs -text命令查看,后面跟要查看的sequencefile的hdfs路径。
(1)写入sequencefile
写入sequencefile示例如代码清单3-9所示。
代码清单3-9 写入sequencefile示例
可以看到sequencefile.writer的构造方法需要制定键值对的类型。如果是日志文件,那么时间戳作为key,日志内容是value是非常合适的。
编译代码清单3-9所示的代码,导出为xx.jar文件,上传至集群任意一节点,执行命令:
运行完成后,执行命令:
可以看到如下内容:
(2)读取sequencefile
读取sequencefile示例如代码清单3-10所示。
代码清单3-10 读取sequencefile示例
编译代码清单3-10所示的代码,导出为xx.jar文件,上传至集群任意一节点,执行命令:
运行完成后,控制台会输出:
1.thrift
hdfs的底层的接口是通过java api提供的,所以非java程序访问hdfs比较麻烦。弥补方法是通过thriftfs功能模块中的thrift api将hdfs封装成一个apache thrift服务。这样任何与thrift绑定的语言都能与hdfs进行交互。为了使用thrift api,需要运行提供thrift服务的服务器,并以代理的方式访问hadoop。目前支持远程调用thrift api的语言有c++、perl、php、python和ruby。
2.fuse
用户空间文件系统(filesystem in universe,fuse)允许把按照用户空间实现的文件系统整合成一个unix文件系统。通过使用hadoop的fuse-dfs功能模块,任意一个hadoop文件系统(如hdfs)均可作为一个标准文件系统进行挂载。随后便可以使用普通unix命令,如ls、cat等与该文件系统交互,还可以通过任意一种编程语言调用posix库来访问文件系统。
其余可以访问hdfs的还有webdav、http、ftp接口,不过并不常用。
我们还可以通过namenode的50070端口号访问hdfs的web ui,hdfs的web ui包含了非常丰富并且实用的信息,如图3-10所示。通过hdfs的web ui了解集群的状况是一名合格hadoop开发和运维人员必备的条件。
我们可以直接在浏览器中输入master:9000(即namenode的主机名:端口号)便可进入web ui。如图3-10,点击“browse the filesystem”可以查看整个hdfs的目录树,点击“namenode logs”可以查看所有的namenode的日志,这对于排查错误十分有帮助。下面的表格展示了整个hdfs大致的信息,如总容量、使用量、剩余量等,其中点击“live nodes”选项,可以看到所有datanode节点的状况,如图3-11所示。
