本節書摘來異步社群《hadoop海量資料處理:技術詳解與項目實戰》一書中的第3章,第3.3節,作者: 範東來 責編: 楊海玲,更多章節内容可以通路雲栖社群“異步社群”公衆号檢視。
hadoop海量資料處理:技術詳解與項目實戰
hdfs提供給hdfs用戶端通路的方式多種多樣,使用者可以根據不同的情況選擇不同的方式。
hadoop自帶一組指令行工具,而其中有關hdfs的指令是其工具集的一個子集。指令行工具雖然是最基礎的檔案操作方式,但卻是最常用的。作為一名合格的hadoop開發人員和運維人員,熟練掌握是非常有必要的。
執行hadoop dfs指令可以顯示基本的使用資訊。
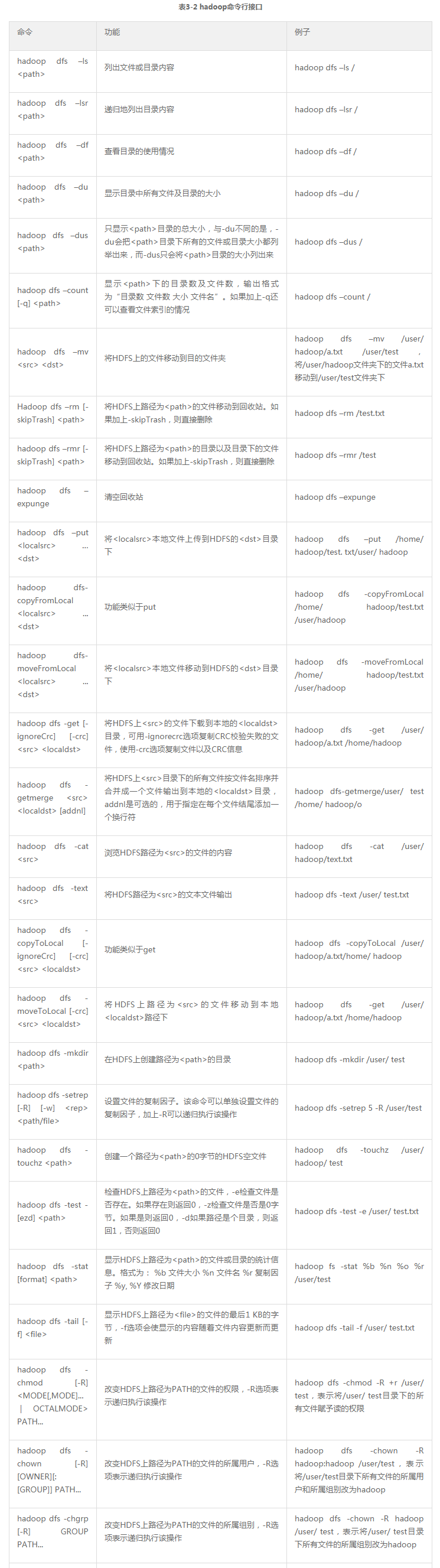
表3-2列出了hadoop指令行接口,并用例子說明各自的功能。
本地通路hdfs最主要的方式是hdfs提供的java應用程式接口,其他的通路方式都建立在這些應用程式接口之上。為了通路hdfs,hdfs用戶端必須擁有一份hdfs的配置檔案,也就是hdfs-site.xml檔案,以擷取namenode的相關資訊,每個應用程式也必須能通路hadoop程式庫jar檔案,也就是在$hadoop_home、$hadoop_home/lib下面的jar檔案。
hadoop是由java編寫的,是以通過java api可以調用所有的hdfs的互動操作接口,最常用的是filesystem類,它也是指令行hadoop fs的實作,其他接口在這一節也會有 介紹。
1.java.net.url
先來看一個例子,如代碼清單3-1所示。
代碼清單3-1 java.net.url示例
編譯代碼清單3-1所示的代碼,導出為xx.jar檔案,執行指令:
執行完成後,螢幕上輸出hdfs的檔案/user/hadoop/test的檔案内容。
該程式是從hdfs讀取檔案的最簡單的方式,即用java.net.url對象打開資料流。代碼中,靜态代碼塊的作用是讓java程式識别hadoop的hdfs url。
2.org.apache.hadoop.fs.filesystem
雖然上面的方式是最簡單的方式,但是在實際開發中,通路hdfs最常用的類還是filesystem類。
(1)讀取檔案
讀取檔案的示例如代碼清單3-2所示。
代碼清單3-2 讀取檔案示例
編譯代碼3-2,導出為xx.jar檔案,上傳至叢集任意一節點,執行指令:
執行完成後控制台會輸出檔案内容。
filesystem類的執行個體擷取是通過工廠方法:
其中configuration對象封裝了hdfs用戶端或者hdfs叢集的配置,該方法通過給定的uri方案和權限來确定要使用的檔案系統。得到filesystem執行個體之後,調用open()函數獲得檔案的輸入流:
方法傳回hadoop獨有的fsdatainputstream對象。
(2)寫入檔案
寫入檔案的示例如代碼清單3-3所示。
代碼清單3-3 寫入檔案示例
編譯代碼清單3-3所示的代碼,導出為xx.jar檔案,上傳至叢集任意一節點,執行指令:
hadoop jar xx.jar com.hdfsclient.filecopyfromlocal
filesystem執行個體的create()方法傳回fsdataoutputstream對象,與fsdatainputstream類不同的是,fsdataoutputstream不允許在檔案中定位,這是因為hdfs隻允許一個已打開的檔案順序寫入,或在現有檔案的末尾追加資料。
(3)建立hdfs的目錄
建立hdfs目錄的示例如代碼清單3-4所示。
代碼清單3-4 建立hdfs目錄示例
編譯代碼清單3-4所示的代碼,導出為xx.jar檔案,上傳至叢集任意一節點,執行指令:
運作完成後可以用指令hadoop dfs -ls驗證目錄是否建立成功。
(4)删除hdfs上的檔案或目錄
删除hdfs上的檔案或目錄的示例如代碼清單3-5所示。
代碼清單3-5 删除hdfs上的檔案或目錄示例
編譯代碼清單3-5所示的代碼,導出為xx.jar檔案,上傳至叢集任意一節點,執行指令:
如果需要遞歸删除檔案夾,則需将fs.delete(arg0, arg1)方法的第二個參數設為true。
(5)檢視檔案是否存在
檢視檔案的示例如代碼清單3-6所示。
代碼清單3-6 檢視檔案示例
編譯代碼清單3-6所示的代碼,導出為xx.jar檔案,上傳至叢集任意一台節點,執行指令:
(6)列出目錄下的檔案或目錄名稱
列出目錄下的檔案或目錄名稱的示例如代碼清單3-7所示。
代碼清單3-7 列出目錄下的檔案或目錄名稱示例
編譯代碼清單3-7所示的代碼,導出為xx.jar檔案,上傳至叢集任意一節點,執行指令:
運作後,控制台會列印出/user目錄下的目錄名稱或檔案名。
(7)檔案存儲的位置資訊
檔案存儲的位置資訊的示例如代碼清單3-8所示。
代碼清單3-8 檔案存儲的位置資訊示例
編譯代碼清單3-8所示的代碼,導出為xx.jar檔案,上傳至叢集任意一節點,執行指令:
前面提到過,hdfs的存儲由datanode的塊完成,執行成功後,控制台會輸出:
表示該檔案被分為3個資料塊存儲,存儲的位置分别為slave1、slave2、slave3。
3.sequencefile
sequecefile是hdfs api提供的一種二進制檔案支援,這種二進制檔案直接将對序列化到檔案中,是以sequencefile是不能直接檢視的,可以通過hadoop dfs -text指令檢視,後面跟要檢視的sequencefile的hdfs路徑。
(1)寫入sequencefile
寫入sequencefile示例如代碼清單3-9所示。
代碼清單3-9 寫入sequencefile示例
可以看到sequencefile.writer的構造方法需要制定鍵值對的類型。如果是日志檔案,那麼時間戳作為key,日志内容是value是非常合适的。
編譯代碼清單3-9所示的代碼,導出為xx.jar檔案,上傳至叢集任意一節點,執行指令:
運作完成後,執行指令:
可以看到如下内容:
(2)讀取sequencefile
讀取sequencefile示例如代碼清單3-10所示。
代碼清單3-10 讀取sequencefile示例
編譯代碼清單3-10所示的代碼,導出為xx.jar檔案,上傳至叢集任意一節點,執行指令:
運作完成後,控制台會輸出:
1.thrift
hdfs的底層的接口是通過java api提供的,是以非java程式通路hdfs比較麻煩。彌補方法是通過thriftfs功能子產品中的thrift api将hdfs封裝成一個apache thrift服務。這樣任何與thrift綁定的語言都能與hdfs進行互動。為了使用thrift api,需要運作提供thrift服務的伺服器,并以代理的方式通路hadoop。目前支援遠端調用thrift api的語言有c++、perl、php、python和ruby。
2.fuse
使用者空間檔案系統(filesystem in universe,fuse)允許把按照使用者空間實作的檔案系統整合成一個unix檔案系統。通過使用hadoop的fuse-dfs功能子產品,任意一個hadoop檔案系統(如hdfs)均可作為一個标準檔案系統進行挂載。随後便可以使用普通unix指令,如ls、cat等與該檔案系統互動,還可以通過任意一種程式設計語言調用posix庫來通路檔案系統。
其餘可以通路hdfs的還有webdav、http、ftp接口,不過并不常用。
我們還可以通過namenode的50070端口号通路hdfs的web ui,hdfs的web ui包含了非常豐富并且實用的資訊,如圖3-10所示。通過hdfs的web ui了解叢集的狀況是一名合格hadoop開發和運維人員必備的條件。
我們可以直接在浏覽器中輸入master:9000(即namenode的主機名:端口号)便可進入web ui。如圖3-10,點選“browse the filesystem”可以檢視整個hdfs的目錄樹,點選“namenode logs”可以檢視所有的namenode的日志,這對于排查錯誤十分有幫助。下面的表格展示了整個hdfs大緻的資訊,如總容量、使用量、剩餘量等,其中點選“live nodes”選項,可以看到所有datanode節點的狀況,如圖3-11所示。
