1 KafkaConsumer 构造器
- 初始化参数配置。
- 初始化消费者网络客户端
ConsumerNetworkClient
- 初始化消费者协调器
ConsumerCoordinator
- 初始化拉取器
Fetcher
2 订阅主题
- 调用订阅方法
subscribe()、assign()
SubscriptionState
- 如果元数据缓存
Metadata
needUpdate=true
3 拉取消息
-
poll()
timeoutMs
- 更新分配给消费者的数据,包括消费者协调器、偏移量、心跳等。
- 根据超时时间拉取消息。
- 如果拉取的消息不为空,立即出发下一轮的拉取,可以避免因处理消息响应,而阻塞等待。
- 拉取的消息会先反序列化,再调用消费者拦截器,最后返回给消费者。
- 拉取超时后,返回空记录。
private ConsumerRecords<K, V> poll(final long timeoutMs, final boolean includeMetadataInTimeout) {
long elapsedTime = 0L;
do {
final long metadataEnd;
// 更新分配元数据,协调器、心跳、消费位置
if (!updateAssignmentMetadataIfNeeded(remainingTimeAtLeastZero(timeoutMs, elapsedTime))) {
return ConsumerRecords.empty();
}
// 拉取消息
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(remainingTimeAtLeastZero(timeoutMs, elapsedTime));
if (!records.isEmpty()) {
// 消息不为空时,立即发起下一轮的拉取消息,避免阻塞等待响应处理。
// 注意,在消息返回之前,不能触发唤醒或其他错误。
if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) {
client.pollNoWakeup();
}
// 回调执行消费者拦截器后返回给消费者
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
final long fetchEnd = time.milliseconds();
elapsedTime += fetchEnd - metadataEnd;
} while (elapsedTime < timeoutMs); // 轮询拉取,知道超过输入的超时时间
return ConsumerRecords.empty();
}
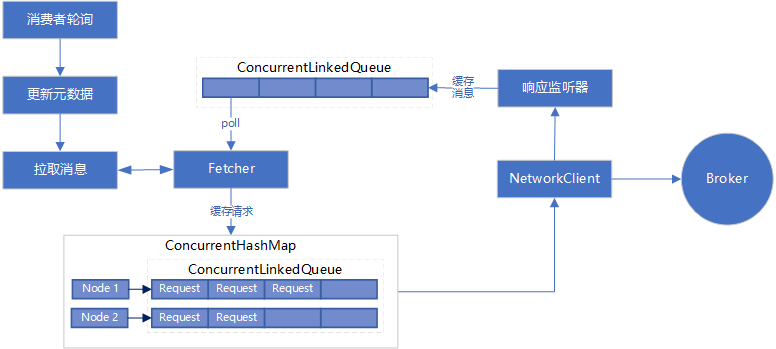
3.1 拉取消息的详细流程
- 如果分区记录缓存
PartitionRecords
completedFetches
- 否则,向服务端发送拉取请求,消费者并不会立即发送请求,而是先构造 Node 和请求的缓存
LinkedHashMap
- 遍历上述缓存,构造成可以直接发送的请求,并缓存到
ConcurrentHashMap<Node, ConcurrentLinkedQueue<ClientRequest>> unsent
- 遍历
unsent
NetworkClient
unsent
- 当拉取到消息,会回调第3步中的监听器,将消息缓存到队列
ConcurrentLinkedQueue<CompletedFetch> completedFetches
- 类似第1步,从分区记录缓存队列
completedFetches
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollForFetches(final long timeoutMs) {
final long startMs = time.milliseconds();
long pollTimeout = Math.min(coordinator.timeToNextPoll(startMs), timeoutMs);
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords(); // 从缓存队列拉取
if (!records.isEmpty()) { // 缓存中有数据则直接返回
return records;
}
// 1.将拉取请求构造成节点和请求的映射关系,并缓存在 unsent
// 2.添加响应处理监听器,处理发送拉取请求后,从服务端返回的消息,并缓存在队列中
fetcher.sendFetches();
// 用 NetworkClient 向服务端发送拉取请求
client.poll(pollTimeout, startMs, () -> return !fetcher.hasCompletedFetches());
return fetcher.fetchedRecords(); // 再次从缓存队列拉取
}
// 从缓存拉取队列拉取消息
public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() {
Map<TopicPartition, List<ConsumerRecord<K, V>>> fetched = new HashMap<>();
int recordsRemaining = maxPollRecords;
while (recordsRemaining > 0) { // 在超时时间内不断轮询
if (nextInLineRecords == null || nextInLineRecords.isFetched) { // 分区记录为空,或者已拉取
CompletedFetch completedFetch = completedFetches.peek(); // 从缓存队列拉取消息
nextInLineRecords = parseCompletedFetch(completedFetch); // 将消息解析成分区消息记录 PartitionRecords
completedFetches.poll(); // 对缓存队列移除
} else {
List<ConsumerRecord<K, V>> records = fetchRecords(nextInLineRecords, recordsRemaining); // 从分区记录拉取消息
TopicPartition partition = nextInLineRecords.partition;
if (!records.isEmpty()) { // 拉取到消息,方法 Map,以返回给消费者
fetched.put(partition, records);
}
}
return fetched;
}
4 整体流程
![Java小案例——随机数猜测随机数猜测[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)