1 KafkaConsumer 構造器
- 初始化參數配置。
- 初始化消費者網絡用戶端
ConsumerNetworkClient
- 初始化消費者協調器
ConsumerCoordinator
- 初始化拉取器
Fetcher
2 訂閱主題
- 調用訂閱方法
subscribe()、assign()
SubscriptionState
- 如果中繼資料緩存
Metadata
needUpdate=true
3 拉取消息
-
poll()
timeoutMs
- 更新配置設定給消費者的資料,包括消費者協調器、偏移量、心跳等。
- 根據逾時時間拉取消息。
- 如果拉取的消息不為空,立即出發下一輪的拉取,可以避免因處理消息響應,而阻塞等待。
- 拉取的消息會先反序列化,再調用消費者攔截器,最後傳回給消費者。
- 拉取逾時後,傳回空記錄。
private ConsumerRecords<K, V> poll(final long timeoutMs, final boolean includeMetadataInTimeout) {
long elapsedTime = 0L;
do {
final long metadataEnd;
// 更新配置設定中繼資料,協調器、心跳、消費位置
if (!updateAssignmentMetadataIfNeeded(remainingTimeAtLeastZero(timeoutMs, elapsedTime))) {
return ConsumerRecords.empty();
}
// 拉取消息
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(remainingTimeAtLeastZero(timeoutMs, elapsedTime));
if (!records.isEmpty()) {
// 消息不為空時,立即發起下一輪的拉取消息,避免阻塞等待響應處理。
// 注意,在消息傳回之前,不能觸發喚醒或其他錯誤。
if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) {
client.pollNoWakeup();
}
// 回調執行消費者攔截器後傳回給消費者
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
final long fetchEnd = time.milliseconds();
elapsedTime += fetchEnd - metadataEnd;
} while (elapsedTime < timeoutMs); // 輪詢拉取,知道超過輸入的逾時時間
return ConsumerRecords.empty();
}
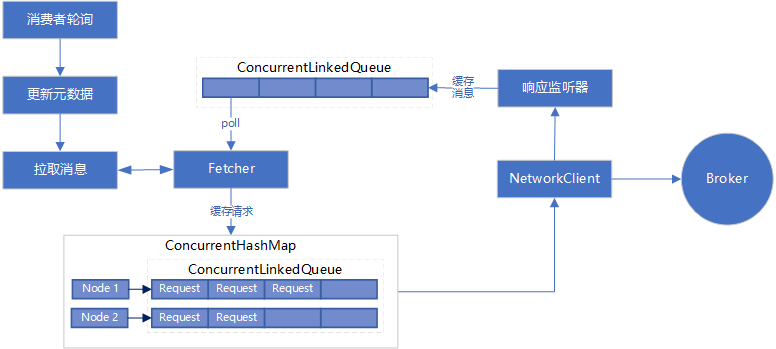
3.1 拉取消息的詳細流程
- 如果分區記錄緩存
PartitionRecords
completedFetches
- 否則,向服務端發送拉取請求,消費者并不會立即發送請求,而是先構造 Node 和請求的緩存
LinkedHashMap
- 周遊上述緩存,構造成可以直接發送的請求,并緩存到
ConcurrentHashMap<Node, ConcurrentLinkedQueue<ClientRequest>> unsent
- 周遊
unsent
NetworkClient
unsent
- 當拉取到消息,會回調第3步中的監聽器,将消息緩存到隊列
ConcurrentLinkedQueue<CompletedFetch> completedFetches
- 類似第1步,從分區記錄緩存隊列
completedFetches
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollForFetches(final long timeoutMs) {
final long startMs = time.milliseconds();
long pollTimeout = Math.min(coordinator.timeToNextPoll(startMs), timeoutMs);
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords(); // 從緩存隊列拉取
if (!records.isEmpty()) { // 緩存中有資料則直接傳回
return records;
}
// 1.将拉取請求構造成節點和請求的映射關系,并緩存在 unsent
// 2.添加響應處理監聽器,處理發送拉取請求後,從服務端傳回的消息,并緩存在隊列中
fetcher.sendFetches();
// 用 NetworkClient 向服務端發送拉取請求
client.poll(pollTimeout, startMs, () -> return !fetcher.hasCompletedFetches());
return fetcher.fetchedRecords(); // 再次從緩存隊列拉取
}
// 從緩存拉取隊列拉取消息
public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() {
Map<TopicPartition, List<ConsumerRecord<K, V>>> fetched = new HashMap<>();
int recordsRemaining = maxPollRecords;
while (recordsRemaining > 0) { // 在逾時時間内不斷輪詢
if (nextInLineRecords == null || nextInLineRecords.isFetched) { // 分區記錄為空,或者已拉取
CompletedFetch completedFetch = completedFetches.peek(); // 從緩存隊列拉取消息
nextInLineRecords = parseCompletedFetch(completedFetch); // 将消息解析成分區消息記錄 PartitionRecords
completedFetches.poll(); // 對緩存隊列移除
} else {
List<ConsumerRecord<K, V>> records = fetchRecords(nextInLineRecords, recordsRemaining); // 從分區記錄拉取消息
TopicPartition partition = nextInLineRecords.partition;
if (!records.isEmpty()) { // 拉取到消息,方法 Map,以傳回給消費者
fetched.put(partition, records);
}
}
return fetched;
}
4 整體流程
![Java小案例——随機數猜測随機數猜測[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)