主从复制的局限性
手动故障转移
- master宕机,redis服务不可用
- slave数据同步中断
- 手动故障转移
- 选出一个slave节点执行
slaveof no one
- 其他slave节点执行
slaveof new master
- 对于调用redis服务的客户端,如何让客户端感知master发生变化,做出相应的处理是比较困难的。
写能力和存储能力受限
- 只有master节点可以做写入操作,存储能力十分有限。
Redis Sentinel
全文除非有特殊声明,否则全部默认为redis5.0版本
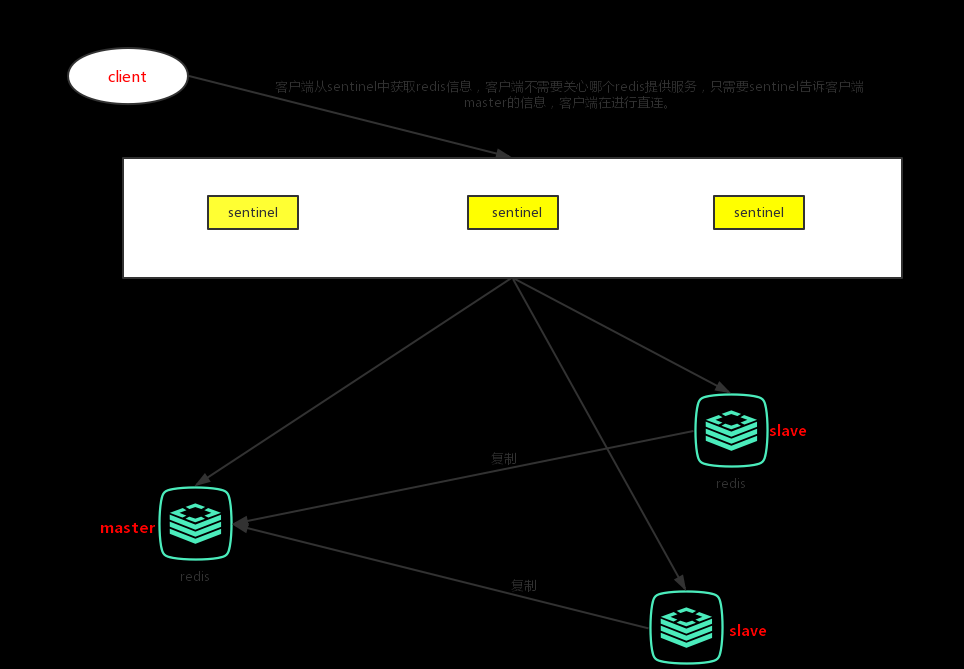
一套sentinel可以监控多套master-slave服务,使用master name配置作为标识。
安装与配置
安装配置redis-server
- 新建一个redis配置文件redis-7000.conf,按照最简配置
port 7000
daemonize yes
pidfile /usr/local/software/redis/data/redis-7000.pid
logfile "/usr/local/software/redis/data/7000.log"
dir "/usr/local/software/redis/data"
借助sed命令快速生成slave节点配置为文件
sed "s/7000/7001/g" redis-7000.conf > redis-7001.conf
sed "s/7000/7002/g" redis-7000.conf > redis-7002.conf
#配置主从关系
echo "slaveof 127.0.0.1 7000">> redis-7001.conf
echo "slaveof 127.0.0.1 7000" >> redis-7002.conf
#分别启动redis的7000,7001,7002节点
./redis-server redis-7000.conf
./redis-server redis-7001.conf
./redis-server redis-7002.conf
- 使用客户端连接redis-7000服务
我们不难看出当前7000端口的redis是master节点,它有两个slave节点端口分别是7001和7002,并且全部处于在线状态。
redis-cli -p 7000
127.0.0.1:7000> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=ip,port=7001,state=online,offset=789019,lag=0
slave1:ip=ip,port=7002,state=online,offset=789019,lag=0
master_replid:e27b673924f62d27605f5d095924ec5c287ced02
master_replid2:bc30e94bea8b34c0b5ba9f815f316edd8a05aa33
master_repl_offset:789019
second_repl_offset:265200
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:789019
- 使用客户端连接redis-7001服务
在这里我们很清楚的看到,7001节点为slave,他的master的host和端口号就是我们的7000端口的 redis节点。
[[email protected] redis]# ./redis-cli -p 7001
127.0.0.1:7001> info replication
# Replication
role:slave
master_host:ip
master_port:7000
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:919032
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:e27b673924f62d27605f5d095924ec5c287ced02
master_replid2:bc30e94bea8b34c0b5ba9f815f316edd8a05aa33
master_repl_offset:919032
second_repl_offset:265200
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:919032
127.0.0.1:7001>
安装配置redis-server
- 配置开启sentinel监控主节点(sentinel是特殊的redis)
过滤注释和空行,筛出sentinel最简配置
cat sentinel.conf | grep -v "#" | grep -v "^$" > redis-sentinel.conf
设置为后台启动,设置日志文件和工作目录
port 26379
daemonize yes
pidfile /var/run/redis-sentinel-26379.pid
logfile "26379.log"
dir /usr/local/software/redis/data/
sentinel monitor mymaster 127.0.0.1 7000 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
#同理,配置26380,26381端口的配置文件,使用redis-sentinel命令启动。
./redis-sentinel redis-sentinel-26379.conf
./redis-sentinel redis-sentinel-26380.conf
./redis-sentinel redis-sentinel-26381.conf
连接26379端口的sentinel
127.0.0.1:26379> info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=ip:7002,slaves=2,sentinels=3
127.0.0.1:26379>
-
多机器部署,保证高可用
主从不部署在同一台机器上,redis-sentinel不与redis服务部署在同一台机器上,保证高可用
故障转移
故障转移(自动转移)
- 多个sentinel发现并确认master出问题
- 选举一个sentinel成为领导
- 选出一个slave成为新的master
- 通知其余的slave成为新的master的slave
- 通知客户端主从变化
- 等待老的master复活,让它成为新的master的slave
故障转移小实验
在启动redis 7000(master),7001(slave),7002(slave)三个服务和26379,26380,26381三个sentinel服务后,创建一个java项目JedisTest。
(1) 测试代码:
public static void main(String[] args) {
String masterName = "mymaster";
Set<String> sentinelSet = new HashSet<String>();
sentinelSet.add("ip:26379");
sentinelSet.add("ip:26380");
sentinelSet.add("ip:26381");
JedisSentinelPool jedisSentinelPool = new JedisSentinelPool(masterName, sentinelSet);
int counter = 0;
while (true) {
Jedis jedis = null;
try {
counter ++;
jedis = jedisSentinelPool.getResource();
int index = new Random().nextInt(100000);
String key = "k-" + index;
String value = "v-" + index;
jedis.set(key, value);
if(counter % 100 == 0){
log.info("info,key={},value={}", key, value);
}
TimeUnit.MILLISECONDS.sleep(10);
} catch (Exception e) {
e.printStackTrace();
}finally {
if (jedis != null) {
jedis.close();
}
}
}
}
(2) 测试结果如下:
18:56:43.431 [main] INFO com.gy.redisTest.RedisSentinelFailOverTest - info,key=k-22950,value=v-22950
18:56:44.919 [main] INFO com.gy.redisTest.RedisSentinelFailOverTest - info,key=k-98952,value=v-98952
18:56:46.423 [main] INFO com.gy.redisTest.RedisSentinelFailOverTest - info,key=k-43036,value=v-43036
18:56:47.928 [main] INFO com.gy.redisTest.RedisSentinelFailOverTest - info,key=k-92698,value=v-92698
18:56:49.401 [main] INFO com.gy.redisTest.RedisSentinelFailOverTest - info,key=k-32185,value=v-32185
18:56:50.887 [main] INFO com.gy.redisTest.RedisSentinelFailOverTest - info,key=k-66828,value=v-66828
18:56:52.370 [main] INFO com.gy.redisTest.RedisSentinelFailOverTest - info,key=k-55874,value=v-55874
18:56:53.848 [main] INFO com.gy.redisTest.RedisSentinelFailOverTest - info,key=k-5782,value=v-5782
(3)模拟master宕机,kill -9 port
控制台如下:
redis.clients.jedis.exceptions.JedisConnectionException: Unexpected end of stream.
at redis.clients.util.RedisInputStream.ensureFill(RedisInputStream.java:199)
at redis.clients.util.RedisInputStream.readByte(RedisInputStream.java:40)
at redis.clients.jedis.Protocol.process(Protocol.java:151)
at redis.clients.jedis.Protocol.read(Protocol.java:215)
at redis.clients.jedis.Connection.readProtocolWithCheckingBroken(Connection.java:340)
at redis.clients.jedis.Connection.getStatusCodeReply(Connection.java:239)
at redis.clients.jedis.Jedis.set(Jedis.java:121)
at com.gy.redisTest.RedisSentinelFailOverTest.main(RedisSentinelFailOverTest.java:36)
redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool
at redis.clients.util.Pool.getResource(Pool.java:53)
at redis.clients.jedis.JedisSentinelPool.getResource(JedisSentinelPool.java:209)
at com.gy.redisTest.RedisSentinelFailOverTest.main(RedisSentinelFailOverTest.java:32)
Caused by: redis.clients.jedis.exceptions.JedisConnectionException: java.net.ConnectException: Connection refused: connect
at redis.clients.jedis.Connection.connect(Connection.java:207)
at redis.clients.jedis.BinaryClient.connect(BinaryClient.java:93)
at redis.clients.jedis.BinaryJedis.connect(BinaryJedis.java:1767)
at redis.clients.jedis.JedisFactory.makeObject(JedisFactory.java:106)
at org.apache.commons.pool2.impl.GenericObjectPool.create(GenericObjectPool.java:868)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:435)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:363)
at redis.clients.util.Pool.getResource(Pool.java:49)
... 2 more
Caused by: java.net.ConnectException: Connection refused: connect
at java.net.DualStackPlainSocketImpl.waitForConnect(Native Method)
at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:85)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:172)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at redis.clients.jedis.Connection.connect(Connection.java:184)
... 9 more
(4) 等待一段时间后,控制台恢复正常,故障自动转移完成
Caused by: java.net.ConnectException: Connection refused: connect
at java.net.DualStackPlainSocketImpl.waitForConnect(Native Method)
at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:85)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:172)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at redis.clients.jedis.Connection.connect(Connection.java:184)
... 9 more
18:57:27.035 [main] INFO com.gy.redisTest.RedisSentinelFailOverTest - info,key=k-99501,value=v-99501
18:57:28.604 [main] INFO com.gy.redisTest.RedisSentinelFailOverTest - info,key=k-14578,value=v-14578
查看日志
什么是主观下线?什么是客观下线?
- 主观下线是每个sentinel对redis节点失败的“偏见”。
# 节点不可达的默认时间(ping不通)
sentinel down-after-milliseconds <master-name> <milliseconds>
- 客观下线是所有sentinel节点对redis节点(master)失败达成一致意见(达到法定人数)。
#quorum 法定人数
sentinel monitor <master-name> <ip> <redis-port> <quorum>
三个定时任务
- 每10秒每个sentinel对master和slave执行info
- 发现slave节点
- 确认主从关系
- 每两秒每个sentinel通过master节点的channel交换信息(pub/sub)
- 通过_sentinel_:hello频道交互
- 交互对节点的“看法”和自身信息
- 每一秒每个sentinel对其他sentinel和redis执行ping
领导者选举
- 选举的目的: 只有一个sentinel节点去完成故障转移
-
选举的过程:
(1)每个做主观下线的sentinel都要向其他sentinel节点发送命令,请求成为领导者。
(2)收到命令的sentinel节点如果没有投票给其他sentinel节点,那么同意该请求。否则拒绝。
(3)当某个sentinel发现自己的票数超过半数并达到“法定人数”,那么它将成为领导者,执行故障转移。
(4)如果此过程中有多个节点成为领导者,等待一段时间重新选举。
故障转移(sentinel领导者完成)
- 从slave节点中选取一个“合适的”节点成为新的master。
- 对该slave节点执行slaveof no one,成为新的master。
- 通知剩余的slave节点,成为新master的slave,进行主从复制
- 仍旧对下线的redis节点保持关注,当其恢复后,让它成为master的新的slave节点
选择“合适”的master
- 选择slave_priority(优先级高)最大的slave节点,如果存在则返回,不存在继续。
- 选择复制偏移量最大的节点(数据同步最完整),如果存在则返回,不存在继续。
- 选择runId最小的节点
日志分析
(1)查看7000主节点的日志
30712:C 15 Jul 2019 18:44:03.552 * RDB: 4 MB of memory used by copy-on-write
30703:M 15 Jul 2019 18:44:03.566 * Background saving terminated with success
30703:M 15 Jul 2019 18:44:03.566 * Synchronization with replica ip:7001 succeeded
30703:M 15 Jul 2019 18:44:05.656 * Replica ip:7002 asks for synchronization
30703:M 15 Jul 2019 18:44:05.656 * Full resync requested by replica 39.107.69.86:7002
30703:M 15 Jul 2019 18:44:05.656 * Starting BGSAVE for SYNC with target: disk
30703:M 15 Jul 2019 18:44:05.657 * Background saving started by pid 30719
30719:C 15 Jul 2019 18:44:05.661 * DB saved on disk
30719:C 15 Jul 2019 18:44:05.661 * RDB: 4 MB of memory used by copy-on-write
30703:M 15 Jul 2019 18:44:05.672 * Background saving terminated with success
30703:M 15 Jul 2019 18:44:05.672 * Synchronization with replica ip:7002 succeeded
由于我们模拟宕机使用kill命令,主节点日志并没有太多的信息反馈,直到宕机前仍是在做数据同步。
(2) 查看7001和7002从节点日志
30713:C 15 Jul 2019 18:44:03.596 * SYNC append only file rewrite performed
30713:C 15 Jul 2019 18:44:03.596 * AOF rewrite: 4 MB of memory used by copy-on-write
30708:S 15 Jul 2019 18:44:03.633 * Background AOF rewrite terminated with success
30708:S 15 Jul 2019 18:44:03.633 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
30708:S 15 Jul 2019 18:44:03.634 * Background AOF rewrite finished successfully
30708:S 15 Jul 2019 18:58:28.241 # Connection with master lost.
30708:S 15 Jul 2019 18:58:28.241 * Caching the disconnected master state.
30708:S 15 Jul 2019 18:58:28.846 * Connecting to MASTER ip:7000
30708:S 15 Jul 2019 18:58:28.847 * MASTER <-> REPLICA sync started
30708:S 15 Jul 2019 18:58:28.849 # Error condition on socket for SYNC: Connection refused
30708:S 15 Jul 2019 18:58:29.850 * Connecting to MASTER ip:7000
30708:S 15 Jul 2019 18:58:29.850 * MASTER <-> REPLICA sync started
30708:S 15 Jul 2019 18:58:29.853 # Error condition on socket for SYNC: Connection refused
30708:S 15 Jul 2019 18:58:30.851 * Connecting to MASTER ip:7000
30708:S 15 Jul 2019 18:58:30.852 * MASTER <-> REPLICA sync started
30708:S 15 Jul 2019 18:58:30.854 # Error condition on socket for SYNC: Connection refused
30708:S 15 Jul 2019 18:58:31.855 * Connecting to MASTER ip:7000
30708:S 15 Jul 2019 18:58:31.855 * MASTER <-> REPLICA sync started
...
30708:S 15 Jul 2019 18:58:56.919 * MASTER <-> REPLICA sync started
30708:S 15 Jul 2019 18:58:56.922 # Error condition on socket for SYNC: Connection refused
30708:S 15 Jul 2019 18:58:57.919 * Connecting to MASTER ip:7000
30708:S 15 Jul 2019 18:58:57.920 * MASTER <-> REPLICA sync started
30708:S 15 Jul 2019 18:58:57.922 # Error condition on socket for SYNC: Connection refused
30708:M 15 Jul 2019 18:58:58.628 # Setting secondary replication ID to d1c40b043f9fbc70ef8435d26897219c71ab97d7, valid up to offset: 379160. New replication ID is fdf1866660032a8cfd27167bf52a899d4e0dd7a5
30708:M 15 Jul 2019 18:58:58.628 * Discarding previously cached master state.
30708:M 15 Jul 2019 18:58:58.628 * MASTER MODE enabled (user request from 'id=7 addr=ip:50284 fd=11 name=sentinel-dbea5725-cmd age=285 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=154 qbuf-free=32614 obl=36 oll=0 omem=0 events=r cmd=exec')
30708:M 15 Jul 2019 18:58:58.629 # CONFIG REWRITE executed with success.
30708:M 15 Jul 2019 18:58:59.040 * Replica ip:7002 asks for synchronization
30708:M 15 Jul 2019 18:58:59.040 * Partial resynchronization request from ip:7002 accepted. Sending 663 bytes of backlog starting from offset 379160.
30715:S 15 Jul 2019 18:58:57.026 # Error condition on socket for SYNC: Connection refused
30715:S 15 Jul 2019 18:58:58.024 * Connecting to MASTER ip:7000
30715:S 15 Jul 2019 18:58:58.024 * MASTER <-> REPLICA sync started
30715:S 15 Jul 2019 18:58:58.026 # Error condition on socket for SYNC: Connection refused
30715:S 15 Jul 2019 18:58:58.719 * REPLICAOF ip:7001 enabled (user request from 'id=7 addr=ip:57200 fd=12 name=sentinel-dbea5725-cmd age=285 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=291 qbuf-free=32477 obl=36 oll=0 omem=0 events=r cmd=exec')
30715:S 15 Jul 2019 18:58:58.721 # CONFIG REWRITE executed with success.
30715:S 15 Jul 2019 18:58:59.027 * Connecting to MASTER ip:7001
30715:S 15 Jul 2019 18:58:59.027 * MASTER <-> REPLICA sync started
30715:S 15 Jul 2019 18:58:59.029 * Non blocking connect for SYNC fired the event.
30715:S 15 Jul 2019 18:58:59.032 * Master replied to PING, replication can continue...
30715:S 15 Jul 2019 18:58:59.039 * Trying a partial resynchronization (request d1c40b043f9fbc70ef8435d26897219c71ab97d7:379160).
30715:S 15 Jul 2019 18:58:59.042 * Successful partial resynchronization with master.
30715:S 15 Jul 2019 18:58:59.042 # Master replication ID changed to fdf1866660032a8cfd27167bf52a899d4e0dd7a5
30715:S 15 Jul 2019 18:58:59.042 * MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization.
- 从日志中我们不难发现在6点58分的时候,slave节点与master节点失联,并且slave一直尝试连接master节点。
- 在58分58秒7001节点接收到一条请求,希望让它成为新的master,并进行了配置重写,7002节点尝试从7001节点请求同步数据。
- 在58分58秒7002节点接收到一条请求,成为7001的从节点,并重写配置信息。7002节点尝试部分重新同步,它记录的master ID进行变更,主节点接受了部分重新同步。(同时,从这里我们也能看出,新版的redis相较旧版本4.0之前做了优化,主从切换可以尝试进行部分复制,不再绝对的进行全量复制)
(3)验证日志分析结果
- 7001节点角色是master,slave节点端口为7002
127.0.0.1:7001> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=ip,port=7002,state=online,offset=1339423,lag=1
master_replid:fdf1866660032a8cfd27167bf52a899d4e0dd7a5
master_replid2:d1c40b043f9fbc70ef8435d26897219c71ab97d7
master_repl_offset:1339423
second_repl_offset:379160
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:290848
repl_backlog_histlen:1048576
- sentinel节点信息显示,主节点端口为7001,同时7002成为它的从节点,但是为什么slave显示为2,是因为sentinel会等待7000节点启动,一旦7000节点启动,会通知7000节点成为7001的从节点。
127.0.0.1:26379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=ip:7001,slaves=2,sentinels=3
- 在三个sentinel节点的日志中可以看出,26379、26380、26381先后将7000节点主观下线(+sdown),计数器+1(“新纪元”+1),26380节点发现主观下线数达到配置的“法定人数”,准备对7000master节点进行客观下线(+odown)。开始投票选举,26380希望成为领导者,26379和26381也投票给了26380节点,选举它成为领导者。领导者通知7001节点slaveof no one 成为master,通知7000节点slave of 7001通知7002节点slave of 7001.
# 26379节点日志
# 主观下线7000节点
30790:X 15 Jul 2019 18:58:58.291 # +sdown master mymaster ip 7000
30790:X 15 Jul 2019 18:58:58.420 # +new-epoch 1
# 投票为26380成为领导者
30790:X 15 Jul 2019 18:58:58.422 # +vote-for-leader dbea572500678a7e3523f5c2d30aee38c771982c 1
30790:X 15 Jul 2019 18:58:58.718 # +config-update-from sentinel dbea572500678a7e3523f5c2d30aee38c771982c ip 26380 @ mymaster ip 7000
# 切换7000主节点为7001主节点
30790:X 15 Jul 2019 18:58:58.718 # +switch-master mymaster ip 7000 ip 7001
30790:X 15 Jul 2019 18:58:58.718 * +slave slave ip:7002 ip 7002 @ mymaster ip 7001
30790:X 15 Jul 2019 18:58:58.718 * +slave slave ip:7000 ip 7000 @ mymaster ip 7001
30790:X 15 Jul 2019 18:59:28.728 # +sdown slave ip:7000 ip 7000 @ mymaster ip 7001
# 26380节点日志
30795:X 15 Jul 2019 18:54:13.809 # Sentinel ID is dbea572500678a7e3523f5c2d30aee38c771982c
# 主观下线7000节点
30795:X 15 Jul 2019 18:58:58.335 # +sdown master mymaster ip 7000
30795:X 15 Jul 2019 18:58:58.411 # +odown master mymaster ip 7000 #quorum 2/2
30795:X 15 Jul 2019 18:58:58.411 # +new-epoch 1
30795:X 15 Jul 2019 18:58:58.411 # +try-failover master mymaster ip 7000
# 希望自己成为领导者
30795:X 15 Jul 2019 18:58:58.416 # +vote-for-leader dbea572500678a7e3523f5c2d30aee38c771982c 1
# 26379投票给我成为领导者
30795:X 15 Jul 2019 18:58:58.422 # f67443294644bcaca75a83bd9aeb0baade1d6ecc voted for dbea572500678a7e3523f5c2d30aee38c771982c 1
# 26381投票给我成为领导者
30795:X 15 Jul 2019 18:58:58.422 # ad712f71928204dc55033dd391968a99388fcd98 voted for dbea572500678a7e3523f5c2d30aee38c771982c 1
30795:X 15 Jul 2019 18:58:58.471 # +elected-leader master mymaster ip 7000
# 故障转移--选择故障master
30795:X 15 Jul 2019 18:58:58.471 # +failover-state-select-slave master mymaster ip 7000
# 选择7001成为master
30795:X 15 Jul 2019 18:58:58.571 # +selected-slave slave ip:7001 ip 7001 @ mymaster ip 7000
# slaveof no one
30795:X 15 Jul 2019 18:58:58.571 * +failover-state-send-slaveof-noone slave ip:7001 ip 7001 @ mymaster ip 7000
30795:X 15 Jul 2019 18:58:58.627 * +failover-state-wait-promotion slave ip:7001 ip 7001 @ mymaster ip 7000
30795:X 15 Jul 2019 18:58:58.633 # +promoted-slave slave ip:7001 ip 7001 @ mymaster ip 7000
30795:X 15 Jul 2019 18:58:58.633 # +failover-state-reconf-slaves master mymaster ip 7000
30795:X 15 Jul 2019 18:58:58.717 * +slave-reconf-sent slave ip:7002 ip 7002 @ mymaster ip 7000
# 客观下线
30795:X 15 Jul 2019 18:58:59.555 # -odown master mymaster ip 7000
30795:X 15 Jul 2019 18:58:59.671 * +slave-reconf-inprog slave ip:7002 ip 7002 @ mymaster ip 7000
30795:X 15 Jul 2019 18:58:59.671 * +slave-reconf-done slave ip:7002 ip 7002 @ mymaster ip 7000
30795:X 15 Jul 2019 18:58:59.732 # +failover-end master mymaster ip 7000
# 切换7000主节点为7001主节点
30795:X 15 Jul 2019 18:58:59.732 # +switch-master mymaster ip 7000 ip 7001
30795:X 15 Jul 2019 18:58:59.732 * +slave slave ip:7002 ip 7002 @ mymaster ip 7001
30795:X 15 Jul 2019 18:58:59.732 * +slave slave ip:7000 ip 7000 @ mymaster ip 7001
30795:X 15 Jul 2019 18:59:29.752 # +sdown slave ip:7000 ip 7000 @ mymaster ip 7001
# 26381节点日志
# 主观下线7000节点
30800:X 15 Jul 2019 18:58:58.342 # +sdown master mymaster ip 7000
30800:X 15 Jul 2019 18:58:58.420 # +new-epoch 1
30800:X 15 Jul 2019 18:58:58.422 # +vote-for-leader dbea572500678a7e3523f5c2d30aee38c771982c 1
30800:X 15 Jul 2019 18:58:58.433 # +odown master mymaster ip 7000 #quorum 3/2
30800:X 15 Jul 2019 18:58:58.433 # Next failover delay: I will not start a failover before Mon Jul 15 19:04:59 2019
30800:X 15 Jul 2019 18:58:58.718 # +config-update-from sentinel dbea572500678a7e3523f5c2d30aee38c771982c ip 26380 @ mymaster ip 7000
# 切换7000主节点为7001主节点
30800:X 15 Jul 2019 18:58:58.718 # +switch-master mymaster ip 7000 ip 7001
30800:X 15 Jul 2019 18:58:58.718 * +slave slave ip:7002 ip 7002 @ mymaster ip 7001
30800:X 15 Jul 2019 18:58:58.718 * +slave slave ip:7000 ip 7000 @ mymaster ip 7001
30800:X 15 Jul 2019 18:59:28.769 # +sdown slave ip:7000 ip 7000 @ mymaster ip 7001
日常运维
主节点下线
做一个手动的故障转移,忽略主观下线、客观下线等,直接进行故障转移,完成主节点下线
从节点下线
要考虑是临时下线还是永久下线,例如是否清理数据。
主节点上线
使用sentinel failover 进行替换,然后调高我们希望上线的从节点的slave_priority(优先级)
从节点上线
直接使用slaveof 命令进行主从复制即可。
![Java小案例——随机数猜测随机数猜测[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)