谷歌和斯坦福最新合作综述报告,发表在物理学的顶级期刊“凝聚态物理年鉴”(Annual Review of Condensed Matter Physics)。作者Yasaman Bahri, Jonathan Kadmon, Jeffrey Pennington, Sam S. Schoenholz, Jascha Sohl-Dickstein, and Surya Ganguli
本公众号将对本报告进行翻译,分6次发布。获取英文报告请在本公众号回复关键词“深度学习统计力学”。
系列预告
- 深度学习与统计力学(I) :深度学习中的基础理论问题
- 深度学习与统计力学(II) :深度学习的表达能力
- 深度学习与统计力学(III) :神经网络的误差曲面
- 深度学习与统计力学(IV) :深层网络的信号传播和初始化
- 深度学习与统计力学(V) :深度学习的泛化能力
- 深度学习与统计力学(VI) :通过概率模型进行“深度想象”
深度学习中的一个关键问题是理解何时以及为何深层网络有着好的泛化能力?仅仅用一个包含 个样本的有限数据集 ,针对 个参数 最小化公式(3)中的训练误差 ,网络能够在测试集上精确地进行预测,获得公式(2)所示的较低的测试误差 。深度学习处理的问题中, 可以大 几个数量级,甚至
1 经典泛化理论:计算机科学 VS 物理学
在计算机科学中经典泛化理论[111]将任意学习过程表示为一个函数 。 将任意有限训练集 映射到某个函数空间 中的一个特定函数 ,即 。数据本身通常是从一个真实函数 中(随机)生成的,当 和
当对所有真实函数 选取数据集 时以很高的概率成立。其中 是函数类 复杂度的某种度量。一个主要的度量是 Vapnik–Chervonenkis 维度[112]。对于很多神经网络,Vapnik–Chervonenkis 维度随着参数数量 而增长。公式(11)中的 也可以替换为 Rademacher 复杂度 ,它度量了从 中选取的一个函数与 个随机噪音模式的相关性[113,114]。直观上,如果 很大,且函数类 不是很复杂,则
另一个理解泛化能力的框架是算法稳定性的概念[115],即如果对训练数据 进行扰动时,由算法 得到的函数
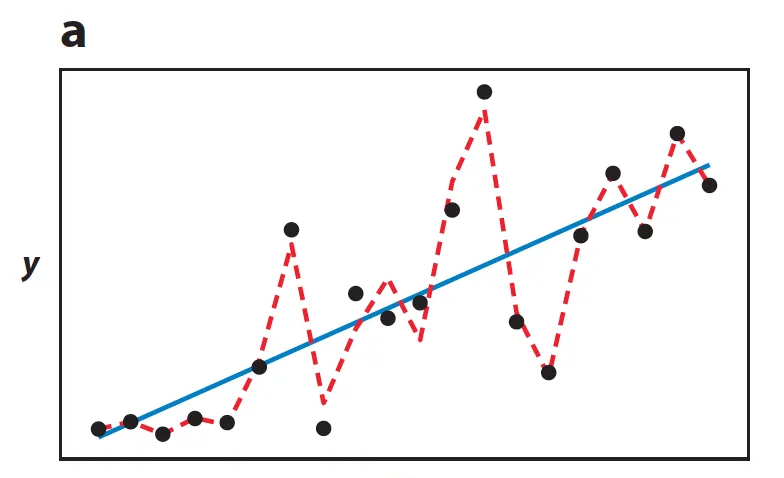
图 5a 考虑一个从真实函数 加上噪声生成的包含 个点的有限数据集 (图中黑色点)。在一个简单的线性函数空间 上最小化训练误差能够得到一个对训练数据扰动稳定的函数(蓝色线),其在训练数据上的泛化能力也较好。在一个更加复杂的分段线性函数空间上最小化则得到一个训练误差更优但是既不稳定泛化能力也差的函数(红色虚线)。
然而,许多上述想法应用到从大小为 的训练集中训练的规模为 的大型神经网络,当 远大于
在物理领域大量有关神经网络泛化方面的研究正在开展。然而物理领域侧重的不再是推导测试误差的上界,而是在热力学极限下渐进精确地计算训练误差和测试误差。热力学极限是指 和 同时很大,但是测量密度 保持为 [126-128](文献11给出了更详细的讨论)。在这种框架下包含 个点的训练集 是从随机输入和真实参数为 的教师神经网络的输出中采样得到。训练误差 可以看作是一个学生神经网络的热自由度 上的能量函数,此时数据 的角色为淬火无序。然后将学生网络参数 的统计力学系统的基态与教师网络的权 进行比较来评估泛化能力。已经存在大量采用这种方法的工作[11],然而对这种复杂的现代神经网络进行计算,以及分析证明在 很小的现实结构的数据集
![2021年银行从业考试考情介绍,果断收藏![图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)