作者:Grey
原文地址:Java中的HashMap
先生成新数组。
遍历老数组中的每个位置上的链表上的个元素。
取个元素的key,并基于新数组长度,计算出每个元素在新数组中的下标。
将元素添加到新数组中去。
所有元转移完了之后,将新数组赋给HashMap对象的table属性。
同样先生成新数组。
遍历老数组中的每个位置上的链表或红黑树。
如果是链表,则直接将表中的每个元索重新计算下标,并添加到新数组中去。
如果是红黑树,则先遍历红黑树,先计算出红黑树中每个元索对应在新数组中的下标位置。
统计每个下标位置的元索个数。
如果该位下的元素个数超过了8,则生成一个新的红黑树,开将根节点添加到新数组的对应位置。
如果该位置下的元素个数没有超过8,那么则生成一个链表,开将链表头节点添加数组的对应位置。
所有元素转移完了之后,将新数组赋给HashMap对象的table属性。
因为在hash冲突比较频繁的情况下,生成的链表长度会非常长,这样就会导致查询的效率会大大降低,为了解决链表过长,查询效率过低的问题,所以使用红黑树来优化,有一个阈值8,超过了这个阈值,就会使用红黑树。
复现代码如下,注:以下代码需要指定jdk1.7为运行环境
运行main方法,发现程序出现死循环,无法停止。这个问题出现在HashMap扩容操作调用的<code>transfer</code>方法中,
假设HashMap当前状态如下
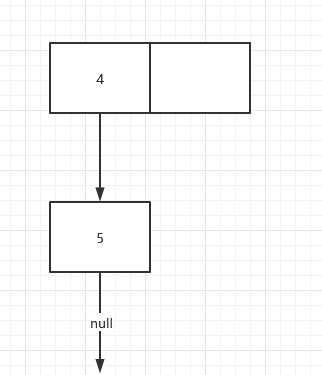
现在有两个线程A和线程B都要执行put操作,线程A和线程B都会看到上面图的状态快照
线程A执行到transfer函数中
这行代码时,此时在线程A的栈中
假设此时线程B正在执行<code>transfer</code>函数中的<code>while</code>循环,即会把原来的table变成新一table(线程B自己的栈中),再写入到内存中。如下图(假设两个元素在新的hash函数下也会映射到同一个位置)

线程A继续执行(看到的仍是旧表),即从<code>transfer</code>代码
处接着执行,当前的
处理元素4 , 将 4 放入 线程A自己栈的新table中(新table是处于线程A自己栈中,是线程私有的,不受线程2的影响),处理4后的图如下
线程A再复制元素5,当前 e = 5 ,而next值由于线程 B 修改了它的引用,所以next 为 4 ,处理后的新表如下图
取5的next值时,由于线程B已经修改了5的next,5的next已经不是<code>null</code>而是4节点,由于取到<code>next=4</code>,线程A继续循环,所以线程A执行完毕后,形成如下结构:
当操作完成,执行查找时,会陷入死循环!
达到当前容量的比例为多少时进行扩容。
问题:为什么HashMap的初始容量为2的n次幂?
以下内容参考jdk1.8 HashMap底层数据结构:深入解析为什么jdk1.8 HashMap的容量一定要是2的n次幂
第一个原因,简单来讲,一个元素放到哪个桶中,是通过<code>hash % capacity</code>取模运算得到的余数来确定的。即调用以下<code>indexFor</code>方法:
hashMap用位运算来替代取模运算<code>(capacity - 1) & hash</code>这种运算方式为什么可以得到跟取模一样的结果呢? 答案是capacity是2的N次幂,计算机做位运算的效率远高于做取模运算的效率,测试见:位运算和取模运算的运算效率对比
证明取模和位运算结果的一致性
第二个原因,将容量设置为2的n次幂关系到扩容后元素在newCap中的放置问题:
扩容后,如何实现将oldCap中的元素重新放到newCap中?我们不难想到的实现方式是:遍历所有Node,然后重新put到新的table中, 中间会涉及计算新桶位置、处理hash碰撞等处理。这里有个不容忽视的问题——哈希碰撞。如下为<code>resize()</code>方法源码:
如果桶上只有一个节点(后面即没链表也没树):元素直接做<code>hash & (newCap - 1)</code>运算,根据结果将元素节点放到newCap的相应位置;
如果桶上是链表:
将链表上的所有节点做<code>hash & oldCap</code>运算(注意,这里oldCap没有-1),会得到一个定位值(“定位值”这个名字是我自己取的,为了更好理解该值的意义)。定位值要么是“0”,要么是“小于capacity的正整数”!这是个规律,之所以能得此规律和capacity取值一定是2的n次幂有直接关系,如果容量不是2的n次幂,那么定位值就不再要么是“0”,要么是“小于capacity的正整数”,它还有可能是其他的数;
根据定位值的不同,会将链表一分为二得到两个子链表,这两个子链表根据各自的定位值直接放到newCap中:
子链表的定位值 == 0: 则链表在oldCap中是什么位置,就将子链表的头节点直接放到newCap的什么位置;
子链表的定位值 == 小于capacity的正整数:则将子链表的头节点放到newCap的“oldCap + 定位值”的位置;
这么做的好处:链表在被拆分成两个子链表前就已经处理过了元素的哈希碰撞问题,子链表不用重新处理哈希碰撞问题,可以直接将头节点直接放到newCap的合适的位置上,完成 “扩容后将元素放到newCap”这一工作。正因为如此,大大提高了jdk1.8的HashMap的扩容效率。
更详细的图例参考:jdk1.8 HashMap底层数据结构:深入解析为什么jdk1.8 HashMap的容量一定要是2的n次幂
一言蔽之:HashMap的容量一定要是2的n次幂,是为了提高“计算元素放哪个桶”的效率,也是为了提高扩容效率(避免了扩容后再重复处理哈希碰撞问题)。
并发的HashMap为什么会引起死循环?
jdk1.8 HashMap底层数据结构:深入解析为什么jdk1.8 HashMap的容量一定要是2的n次幂
实战Java高并发程序设计