作者:Grey
原文位址:Java中的HashMap
先生成新數組。
周遊老數組中的每個位置上的連結清單上的個元素。
取個元素的key,并基于新數組長度,計算出每個元素在新數組中的下标。
将元素添加到新數組中去。
所有元轉移完了之後,将新數組賦給HashMap對象的table屬性。
同樣先生成新數組。
周遊老數組中的每個位置上的連結清單或紅黑樹。
如果是連結清單,則直接将表中的每個元索重新計算下标,并添加到新數組中去。
如果是紅黑樹,則先周遊紅黑樹,先計算出紅黑樹中每個元索對應在新數組中的下标位置。
統計每個下标位置的元索個數。
如果該位下的元素個數超過了8,則生成一個新的紅黑樹,開将根節點添加到新數組的對應位置。
如果該位置下的元素個數沒有超過8,那麼則生成一個連結清單,開将連結清單頭節點添加數組的對應位置。
所有元素轉移完了之後,将新數組賦給HashMap對象的table屬性。
因為在hash沖突比較頻繁的情況下,生成的連結清單長度會非常長,這樣就會導緻查詢的效率會大大降低,為了解決連結清單過長,查詢效率過低的問題,是以使用紅黑樹來優化,有一個門檻值8,超過了這個門檻值,就會使用紅黑樹。
複現代碼如下,注:以下代碼需要指定jdk1.7為運作環境
運作main方法,發現程式出現死循環,無法停止。這個問題出現在HashMap擴容操作調用的<code>transfer</code>方法中,
假設HashMap目前狀态如下
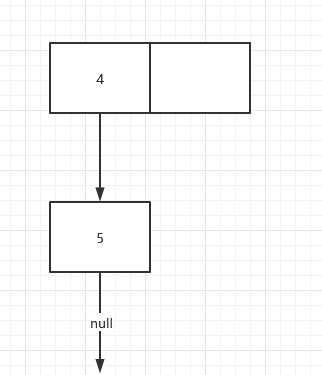
現在有兩個線程A和線程B都要執行put操作,線程A和線程B都會看到上面圖的狀态快照
線程A執行到transfer函數中
這行代碼時,此時線上程A的棧中
假設此時線程B正在執行<code>transfer</code>函數中的<code>while</code>循環,即會把原來的table變成新一table(線程B自己的棧中),再寫入到記憶體中。如下圖(假設兩個元素在新的hash函數下也會映射到同一個位置)

線程A繼續執行(看到的仍是舊表),即從<code>transfer</code>代碼
處接着執行,目前的
處理元素4 , 将 4 放入 線程A自己棧的新table中(新table是處于線程A自己棧中,是線程私有的,不受線程2的影響),處理4後的圖如下
線程A再複制元素5,目前 e = 5 ,而next值由于線程 B 修改了它的引用,是以next 為 4 ,處理後的新表如下圖
取5的next值時,由于線程B已經修改了5的next,5的next已經不是<code>null</code>而是4節點,由于取到<code>next=4</code>,線程A繼續循環,是以線程A執行完畢後,形成如下結構:
當操作完成,執行查找時,會陷入死循環!
達到目前容量的比例為多少時進行擴容。
問題:為什麼HashMap的初始容量為2的n次幂?
以下内容參考jdk1.8 HashMap底層資料結構:深入解析為什麼jdk1.8 HashMap的容量一定要是2的n次幂
第一個原因,簡單來講,一個元素放到哪個桶中,是通過<code>hash % capacity</code>取模運算得到的餘數來确定的。即調用以下<code>indexFor</code>方法:
hashMap用位運算來替代取模運算<code>(capacity - 1) & hash</code>這種運算方式為什麼可以得到跟取模一樣的結果呢? 答案是capacity是2的N次幂,計算機做位運算的效率遠高于做取模運算的效率,測試見:位運算和取模運算的運算效率對比
證明取模和位運算結果的一緻性
第二個原因,将容量設定為2的n次幂關系到擴容後元素在newCap中的放置問題:
擴容後,如何實作将oldCap中的元素重新放到newCap中?我們不難想到的實作方式是:周遊所有Node,然後重新put到新的table中, 中間會涉及計算新桶位置、處理hash碰撞等處理。這裡有個不容忽視的問題——哈希碰撞。如下為<code>resize()</code>方法源碼:
如果桶上隻有一個節點(後面即沒連結清單也沒樹):元素直接做<code>hash & (newCap - 1)</code>運算,根據結果将元素節點放到newCap的相應位置;
如果桶上是連結清單:
将連結清單上的所有節點做<code>hash & oldCap</code>運算(注意,這裡oldCap沒有-1),會得到一個定位值(“定位值”這個名字是我自己取的,為了更好了解該值的意義)。定位值要麼是“0”,要麼是“小于capacity的正整數”!這是個規律,之是以能得此規律和capacity取值一定是2的n次幂有直接關系,如果容量不是2的n次幂,那麼定位值就不再要麼是“0”,要麼是“小于capacity的正整數”,它還有可能是其他的數;
根據定位值的不同,會将連結清單一分為二得到兩個子連結清單,這兩個子連結清單根據各自的定位值直接放到newCap中:
子連結清單的定位值 == 0: 則連結清單在oldCap中是什麼位置,就将子連結清單的頭節點直接放到newCap的什麼位置;
子連結清單的定位值 == 小于capacity的正整數:則将子連結清單的頭節點放到newCap的“oldCap + 定位值”的位置;
這麼做的好處:連結清單在被拆分成兩個子連結清單前就已經處理過了元素的哈希碰撞問題,子連結清單不用重新處理哈希碰撞問題,可以直接将頭節點直接放到newCap的合适的位置上,完成 “擴容後将元素放到newCap”這一工作。正因為如此,大大提高了jdk1.8的HashMap的擴容效率。
更詳細的圖例參考:jdk1.8 HashMap底層資料結構:深入解析為什麼jdk1.8 HashMap的容量一定要是2的n次幂
一言蔽之:HashMap的容量一定要是2的n次幂,是為了提高“計算元素放哪個桶”的效率,也是為了提高擴容效率(避免了擴容後再重複處理哈希碰撞問題)。
并發的HashMap為什麼會引起死循環?
jdk1.8 HashMap底層資料結構:深入解析為什麼jdk1.8 HashMap的容量一定要是2的n次幂
實戰Java高并發程式設計