Machine Heart report
Editors: Egg Sauce, Panda W
After the advent of large models, the term emergence became popular, often expressed as capabilities that did not exist in small-scale models, but existed in large-scale models. But researchers at Stanford University have questioned the idea that LLM has the ability to emerge, arguing that it is the result of human selection of measurements.
"Don't be too superstitious about the emergence of big models, where in the world are there so many miracles?" Researchers at Stanford University found that the emergence of large models is strongly correlated with the evaluation indicators of the task, not the basic changes in model behavior under specific tasks and scales, and after changing to some more continuous and smooth indicators, the emergence phenomenon is less obvious and closer to linear.
Recently, researchers have observed that large language models (LLMs), such as GPT, PaLM, and LaMDA, can exhibit so-called "emergence" in different tasks, and the term has gained a lot of attention in the field of machine learning:
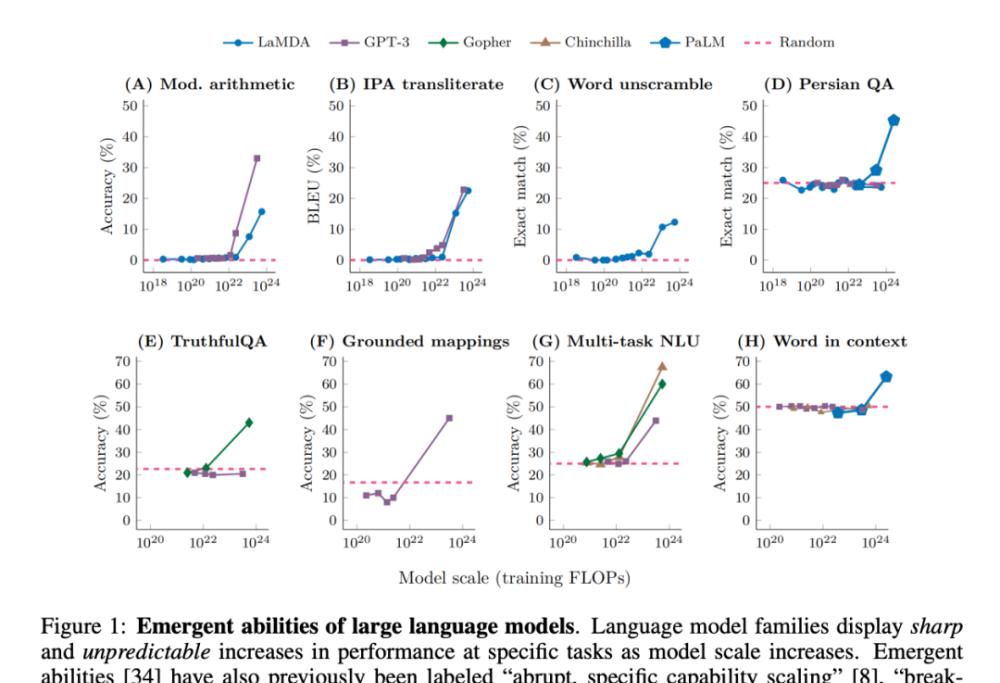
In fact, the emerging properties of complex systems have always been the focus of research in physics, biology, mathematics and other disciplines.
One notable idea is that Nobel Prize winner P.W. Anderson proposed "More Is Different." The idea is that as the complexity of the system increases, new properties may materialize, even if they cannot be predicted (easily or at all) from a precise quantitative understanding of the microscopic details of the system.
How is "emergence" defined in the field of large models? A popular saying is "capabilities that do not exist in small-scale models, but exist in large-scale models", so they cannot be predicted by simply extrapolating performance improvements in small-scale models.
This emergent capability may have been first discovered in the GPT-3 family. Subsequent work underscores this finding: "While model performance is predictable at an average level, performance on specific tasks can sometimes emerge at a rather unpredictable scale." In fact, these emergent capabilities are so surprising that "sudden, specific capability expansion" has been considered one of the two highest defining characteristics of LLM. In addition, terms such as "breakthrough capabilities" and "sharp left turns" are also used.
In summary, we can identify two decisive attributes of LLM emergence:
1. Acuity, the transition from "non-existence" to "existence" seems to be only instantaneous;
2. Unpredictability, transitioning within seemingly unforeseen model scales.
At the same time, questions remain open: What controls which abilities emerge? What controls the emergence of abilities? How can we make ideal capabilities emerge faster and ensure that less desirable capabilities never emerge?
These issues are tied to the safety and alignment of AI, as emerging capabilities foreshadow that larger models may one day gain mastery of dangerous capabilities without warning, something humans don't want.
In a recent paper, researchers at Stanford University question the claim that LLM has the ability to emerge.

Thesis: https://arxiv.org/pdf/2304.15004.pdf
Specifically, the challenge here refers to the emergent and unpredictable changes that occur in the model output as a function of model scale in a particular task.
Their suspicions are based on the observation that it seems that the emergence capability of a model occurs only if it is measured by the per-token error rate of non-linearly or discontinuous scaling of any model. For example, in BIG-Bench tasks, > 92% of the emergence capacity occurs under these two measures:
This raises another explanation for the origin of the emergence capability of LLMs: although the per-token error rate of the model family changes smoothly, continuously, and predictably as the model size increases, seemingly sharp and unpredictable changes may be caused by the measurement method chosen by the investigator.
That said, emergence capabilities may be a mirage, largely due to the researchers' choice of a measure that non-linearly or discontinuous changes to per-token error rate, partly because there is too little test data to accurately estimate the performance of smaller models (resulting in smaller models appearing completely incapable of performing the task), and partly because too few large-scale models are evaluated.
To illustrate this explanation, the researchers took it as a simple mathematical model and demonstrated how it quantitatively reproduced the evidence to support the emergent ability of LLM. The researchers then tested this explanation in three complementary ways:
Using the InstructGPT [24]/GPT-3 [3] model series, three predictions were made, tested, and confirmed based on alternative hypotheses.
2. A meta-analysis of some of the previous results was carried out and showed that in the space of task indicators-model family triplets, the ability to appear appeared only on certain indicators, and not on the model family (column) on the task. The study further shows that changing the metric on a fixed model output leads to the disappearance of emergence.
3. The ability to deliberately induce the emergence of multiple vision tasks in deep neural networks of different architectures (which has never been demonstrated before) to show how similar metric choices can induce seemingly emergent capabilities.
Test 1: InstructGPT/GPT-3 model series analysis
The researchers chose the GPT family model for further analysis because it is publicly queryable, unlike other model families (e.g., PaLM, LaMDA, Gopher, Chinchilla). In previous studies, GPT series models were thought to exhibit emergence capabilities in integer arithmetic tasks. Here, too, the researchers chose the task of integer arithmetic.
Figure 2: The ability of large language models to emerge is a creation of the researchers' analysis, rather than a fundamental change in model output with scale.
As explained mathematically and graphically in Section 2, the alternative explanations proposed by the researchers predict three outcomes:
1. As the model scales, if you replace the metric from a nonlinear/discontinuous metric (Figure 2CD) to a linear/continuous measure (Figure 2EF), you should have a smooth, continuous, predictable performance gain.
2. For nonlinear measures, if you increase the resolution of the measured model performance by increasing the size of the test data set, you should get a smooth, continuous, and predictable improvement of the model in a proportion that corresponds to the predictable nonlinear effect of the selected metric.
3. Regardless of the metric used, increasing the target string length should have an impact on model performance as a function of the target performance of length 1: a function that is near-geometric for accuracy and a near-quasilinear function for token editing distance.
To test these three predictions, the researchers collected string outputs from the InstructGPT/GPT-3 series of models on two arithmetic tasks: two-sample multiplication between 2 two-digit integers and two-sample addition between 2 four-digit integers using the OpenAI API.
Figure 3: As the model scales, changing metrics can result in smooth, continuous, predictable changes in performance.
From left to right: mathematical model, 2 two-digit integer multiplication tasks, 2 four-digit integer addition tasks. The figure above shows the performance of the model measured using a nonlinear measure such as accuracy, and you can see that the performance of the InstructGPT/GPT-3 series models appears sharp and unpredictable at longer target lengths. The graph below shows the performance of the model measured using a linear metric such as token editing distance, which shows smooth, predictable performance gains, which the researchers claim to be the ability to emerge.
Prediction: Emergence will disappear under a linear measure
On these two integer multiplication and addition tasks, if the length of the target string is 4 or 5 digits and performance is measured by accuracy (Figure 3, previous line), then the GPT family model exhibits emerging arithmetic capabilities. However, if you change a metric from nonlinear to linear while keeping the output of the model fixed, the performance of the model series is smooth, continuous, and predictable. This confirms the researchers' predictions, suggesting that the source of sharpness and uncertainty is the measure chosen by the investigator, not the change in the output of the model. It can also be seen that when using token editing distance, if the length of the target string is increased from 1 to 5, the performance of the series of models is expected to degrade, and the downward trend is almost quasi-linear, which is in line with the first half of the third prediction.
Prediction: Emergence capabilities disappear with the advent of higher resolution assessments
This is followed by the second prediction: even with a nonlinear measure such as accuracy, the accuracy of the smaller model will not be zero, but a non-zero value higher than contingency, in proportion corresponding to the choice to use accuracy as the metric. To improve the resolution to further accurately estimate model accuracy, the researchers generated additional test data, and they found that all models in the InstructGPT/GPT-3 family achieved positive accuracy that exceeded chance on both integer multiplication and integer addition tasks (Figure 4). This validates the second prediction. You can see that as the length of the target string increases, the accuracy decreases almost geometrically with the length of the target string, which is consistent with the second half of the third prediction. These results also suggest that the accuracy chosen by the researchers has some (approximate) effects that we should expect, namely near-geometric decay with target length.
Figure 4: Better accuracy estimates using more test data sets reveal that performance changes are smooth, continuous, and predictable.
From left to right: mathematical model, 2 two-digit integer multiplication tasks, 2 four-digit integer addition tasks. Increasing resolution by generating more test data reveals that even in terms of accuracy measures, the performance of the InstructGPT/GPT-3 series model exceeds the incidental results, and the improvement in two emergence capabilities is smooth, continuous, and predictable, and the results of these two emergence capabilities are qualitatively consistent with the mathematical model.
Test 2: Meta-analysis of model emergence
Because GPT family models are publicly queryable, they can be analyzed. However, other models that have been claimed to have emergence capabilities (such as PaLM, Chinchilla, Gopher) are not publicly available, and the output they produce is not publicly available, which means that researchers are limited in their analysis of published results. The researchers gave two predictions based on their own alternative hypotheses:
First, at the "population level" of the task-metric-model family triplet, the model should exhibit emergence on the task when choosing to use nonlinear and/or discontinuous measures to evaluate model performance.
Second, for a specific task-metric-model family triplet that exhibits emergence, if the metric is changed to a linear and/or continuous metric, the emergence capability should be eliminated.
To test these two hypotheses, the researchers investigated the capabilities that claim to emerge on the BIG-Bench evaluation suite, where benchmarks are publicly available and well documented.
Forecasting: Emergence capacity should occur primarily on nonlinear/discontinuous measures
To test the first prediction, the researchers analyzed the indicators on which different "task-model series" pairs would emerge. To determine whether a triplet of the task-metric-model family might exhibit emergence, they borrowed the definition introduced in the paper Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Let y_i ∈ R represent the model performance at a model size of x_i ∈ R and make x_i
The researchers found that most of the measures used by BIG-Bench did not exhibit "task-model series" pairings that exhibited emergence: at most 5 of the 39 BIG-Bench measures that people preferred showed emergence (Figure 5A). Most of these 5 are nonlinear/noncontinuous, such as exact string matching, multi-choice grading, ROUGE-L-Sum. It is worth noting that since BIG-Bench usually uses multiple measures to evaluate the task performance of the model, the lack of emergence capability under other measures indicates that emergence does not occur when other metrics are used to evaluate model output.
Since emergent scores only indicate emergence, the researchers further analyzed the artificially labeled triples of "task-metric-model series" in the paper "137 emergent abilities of large language models." Manually labeled data indicate that only 4 out of 39 measures exhibit emergence capability (Figure 5B), and that 2 of them account for more than 92% of the declared emergence capability (Figure 5C). Multi-choice grading and exact string matching. The multiple-choice grading is non-continuous, and the exact string match is nonlinear (the variation in the target length measure is nearly geometric). Overall, these results illustrate that emergence occurs only on a very small number of nonlinear and/or discontinuous measures.
Figure 5: Only a few metrics exhibit emergence. (A) Of the 39 BIG-Bench measures that people prefer, at most 5 measures may have emergence. (B) The manually labeled data in the cited papers indicate that only 4 measures of people's preference exhibit emergence capacity. (C) 92% of emergence > occur on one of two measures: multi-choice rating and exact string matching.
Prediction: If you replace the nonlinear/discontinuous measure, the emergence capability should be eliminated
For the second prediction, the researchers analyzed the emergence ability of artificial labeling in the previously cited paper. They focused on the LaMDA series because its output is available through BIG-Bench, whereas output from other model families is not. Of the published LaMDA models, the smallest has 2 billion parameters, but many of the LaMDA models in BIG-Bench are much smaller, and the researchers say they were not considered in the analysis because they could not determine the source of these smaller models. In their analysis, the researchers identified which tasks LaMDA demonstrated emergence on a multiple-choice grading measure, and then asked whether LaMDA could demonstrate emergence on the same task when another BIG-Bench measure Brier score. Brier scores are a set of strictly proper scoring rules that measure the prediction of mutually exclusive outcomes; For predictions of a binary outcome, the Brier score is reduced to the mean squared error between the outcome and its predicted probability quality.
The researchers found that the emergent power of LaMDA disappeared when the discontinuous measure multi-choice grading became a continuous measure Brier score (Figure 6). This further suggests that emergence is not due to the essential change in model behavior as it grows, but rather to the use of discontinuous measures.
Figure 6: Changing the BIG-Bench metric while the task and model family remain the same causes the emergence capability to disappear. Previous line: When a discontinuous measure (multi-choice hierarchical) is used, the LaMDA model family exhibits emergence capability. Next line: When a continuous BIG-Bench metric (Brier score) is used, the LaMDA model family no longer has the ability to emerge on the same task.
Test 3: Ability to induce the emergence of DNNs
The researchers' view is that the model can be induced to produce emergence through the choice of metrics; To demonstrate this, they showed how deep neural networks of different architectures (fully connected, convolutional, self-attention) can generate emergence. The researchers here focused on visual tasks for two reasons. First, people are now mainly concerned with the emergence ability of large language models, because for visual models, no sudden change in model capabilities has been observed from nothing. Second, some vision tasks are solved with moderately sized networks, so researchers can build complete model series across orders of magnitude.
Convolutional networks have emerged the ability to classify MNIST handwritten digits
The researchers first induced the implementation of the LeNet convolutional neural network series to emerge classification capabilities, and the training dataset is a MNIST handwritten digit dataset. This series shows a smooth increase in test accuracy as the number of parameters increases (Figure 7B). To simulate the accuracy measures used in the emerging papers, subset accuracy is used here: if the network correctly classifies K data from K (independent) test data, then the subset accuracy of the network is 1, otherwise it is 0. Based on this definition of accuracy, the model family exhibits the ability to "emerge" at settings where K grows from 1 to 5, allowing the correct classification of MNIST number sets, especially when combined with sparse sampling of model size (Figure 7C). The emergent classification capabilities of this convolutional series are qualitatively consistent with the emergence capabilities of published papers, such as the results on BIG-Bench's topographic mapping task (Figure 7A).
Figure 7: Induced emergent MNIST classification capabilities in convolutional networks. (A) Emergent capability based on BIG-Bench terrain mapping tasks in a published paper. (B) LeNet trained on MNIST exhibits a predicted, generalized, S-shaped increase in test accuracy as the number of model parameters increases. (C) When accuracy is redefined to correctly classify K from K independent test data, this newly defined metric induces a seemingly unexpected change.
Nonlinear autoencoders emerge with reconstruction capabilities on the CIFAR100 natural image set
In order to highlight that the sharpness of the measure chosen by the researchers is the reason for the emergence capability, and to show that this sharpness is not limited to measures such as accuracy, the researchers induced the shallow (i.e., single hidden layer) nonlinear autoencoder trained on the CIFAR100 natural image set to emerge the ability to reconstruct the image input. To do this, they deliberately defined a new discontinuity measure of model capability, which is the average number of test data with squared reconstruction errors below a fixed threshold of c:
where I (・) is a random indicator variable and x^n is the autoencoder's reconstruction of x_n. The researchers examined the number of autoencoder bottleneck elements and found that the mean squared reconstruction error of the network showed a smooth downward trend as the model size grew (Figure 8B), but if the newly defined reconstruction metric was used, the ability of the autoencoder series to reconstruct the dataset was sharp and almost unpredictable for the selected c (Figure 8C), which was qualitatively consistent with the emergence capabilities of published papers, such as Periodic in BIG-Bench Elements task (Figure 8A).
Figure 8: Induced emerging reconstruction capabilities in shallow nonlinear autoencoders. (A) Emergency capability based on BIG-Bench periodic element tasks in a published paper. (B) A shallow nonlinear autoencoder trained on the CIFAR100 exhibits a smooth decline in mean squared reconstruction error. (C) Unpredictable changes were induced using the newly defined reconstruction measure (Equation 2).
Autoregressive Transformers emerge with classification capabilities on the Omniglot character set
Next is the emergence of the Transformer, which uses an autoregressive method to classify Omniglot handwritten characters. The experimental setup used by the researchers is similar: the Omniglot image is embedded by a convolutional layer, and then fed into the decoder-only transformer in the form of a [embedded image, image class label] pair, and the training goal of the transformer is to predict the Omniglot class label. The investigators measured image classification performance on sequences of length L ∈ [1, 5], again measured by subset accuracy: if all L images were classified correctly (Figure 9B), the subset accuracy was 1, otherwise it was 0. Causal Transformer appears to exhibit emergence capabilities in correctly classifying Omniglot handwritten character tasks (Figure 9C), which is qualitatively consistent with emergence capabilities found in published papers, such as large-scale multi-task language understanding (Figure 9A).
Figure 9: Inducing emerging classification capabilities in an autoregressive transformer. (A) Emergence based on MMLU benchmarks in a published paper. (B) As the model parameters increased, the test accuracy of Transformers that used autoregressive methods to classify Omniglot handwritten digits also increased. (C) This metric is more difficult to predict when accuracy is redefined as correctly classifying all images in a sequence, which seems to indicate the ability to induce emergence.