1. What is the Http protocol?
HyperText Transfer Protocol (HTTP) is an application layer protocol for distributed, collaborative, and hypermedia information systems. HTTP is the foundation of data communication on the World Wide Web.
When the HTTP protocol is applied, one side must assume the client role and the other end assume the server-side role.
Sometimes, depending on the situation, the roles of two computers as client and server-side may be interchangeable. But in terms of only one communication route, the roles of the server side and the client are determined, and the HTTP protocol can clearly distinguish which end is the client and which side is the server side.
The HTTP protocol states that the request is made from the client, and finally the server responds to the request and returns it. In other words, communication must have been established from the client side first, and the server side will not send a response until the request is received.
2. Message structure of HTTP
For TCP, there are two parts when transmitting: the TCP header and the data part.
HTTP is similar and is also the structure of header + body, specifically: starting line + header + blank line + entity.
Let's introduce them separately:
The starting line
There is still some difference between the request line of the request message and the starting line of the response message.
For request messages, the starting line is as follows:
GET /home HTTP/1.1
方法类型(区分大小写) + 路径 + http路径 For response messages, the starting line (status line) is as follows:
HTTP/1.1 200 OK
http版本 + 状态码 + 原因 To be clear, in the starting line, each of the two sections is separated by a space, and the last section should be followed by a newline, strictly following the ABNF syntax specification.
head
Header fields are generally divided into the following categories: request header, response header, generic header, and entity header
The position of the request header and response header in the message is as follows:
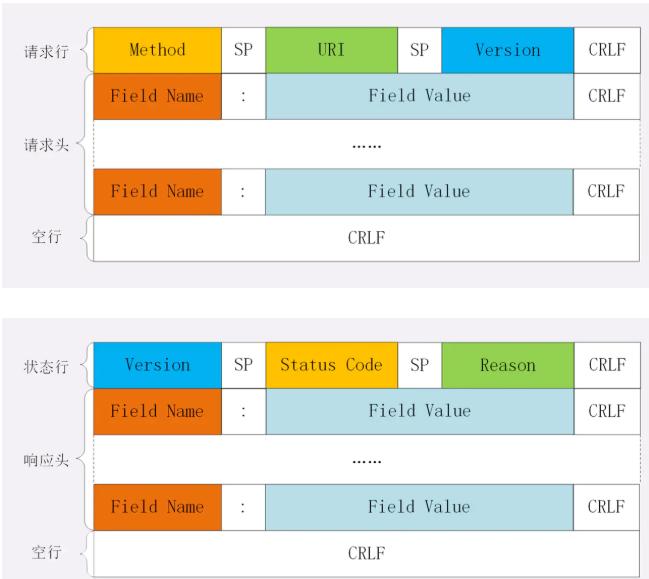
The format of the header field is generally as follows:
1. Field names are not case-sensitive
2. Fields are not allowed to appear spaces, and underscores cannot appear_
3. The field name must be immediately followed by:
Blank line
Blank rows are used to distinguish between heads and entities.
entity
Refers to the specific data, that is, the body part. The request message corresponds to the request body, and the response message corresponds to the response body.
3. HTTP request mode
http/1.1 specifies the following request methods:
- GET: Typically used to get resources
- HEAD: Gets the meta information for the resource
- POST: Submit data, that is, upload data
- PUT: Modify the data
- DELETE: Delete resources (barely needed)
- CONNECT: Establishes a connection tunnel for the proxy server
- OPTIONS: Lists the request methods that can be applied to a resource for cross-domain requests
- TRACE: Traces the transmit path of the request-response
Of the above eight request methods, GET and POST are the two most used and the most important ones.
4. The difference between GET and POST
From a caching perspective, GET requests are proactively cached by the browser, leaving history behind, while POST does not default.
From an encoding perspective, GET can only be URL encoded and can only receive ASCII characters, while POST has no restrictions.
From the perspective of parameters, GET is generally placed in the URL, so it is not secure, and POST is placed in the request body, which is more suitable for transmitting sensitive information.
From an idempotency perspective, GET is idempotent, while POST is not. (Idempotent means performing the same operation and the result being the same)
From tcp's point of view, the GET request will send out the request packet at once, while the POST will be divided into two TCP packets, first sending the header part, if the server responds with 100 (continue), and then sending the body part. (Except for Firefox, which sends only one TCP packet for its POST request))
5. Status code of Http
The responsibility of the status code is to describe the result of the request returned when the client sends a request to the server side. With the status code, the user can know whether the server side processed the request normally or if an error occurred.
Generally divided into the following categories:
- 1XX: Is an informational status code that indicates that the received request is being processed.
- 2XX: Is the success status code, indicating that the request has been processed normally.
- 3XX: Is a redirect status code that indicates that additional actions are required to complete the request.
- 4XX: Is a client error status code that indicates that the server was unable to process the request.
- 5XX: For the server-side error status code, the server processed the request with an error.
Common status codes such as:
- The 200 OK request was successfully processed and the data was returned.
- 204 The No Content request was successfully processed, but no data resources were returned.
- 301 Moved Permanently permanent redirect. The status code indicates that the requested resource has been assigned a new URI, and the URI that the resource now refers to should be used later.
- 302 Found Temporary Redirect. The status code indicates that the requested resource has been assigned a new URI and expects the user (this time) to be able to access it using the new URI.
- 304 Not Modified will talk about http comparing caches below, indicating that resources have not been modified and can use caches.
- A 400 Bad Request indicates a syntax error in the request message. When an error occurs, you need to modify the content of the request and send the request again.
- 401 Unauthorized Not Certified requires authentication after re-requesting.
- 403 Forbidden indicates that access to the requested resource was denied by the server.
- 404 Not Found indicates that the requested resource could not be found on the server.
- A 500 Internal Server Error indicates that an error occurred while executing the request on the server side.
- 503 Service Unavailable indicates that the server is temporarily overloaded or undergoing downtime for maintenance and is now unable to process requests.
Related video recommendations
C++ background development, how to make your http web server do different
From 50 Tencent interview questions, analyze the skill tree of Tencent C++ back-end engineering
Learning Address: C/C++ Linux Server Development/Background Architect [Zero Sound Education] - Learn Video Tutorial - Tencent Classroom
Requires C/C++ Linux server architects to learn materials plus group 812855908 access (materials include C/C++, Linux, golang technology, Nginx, ZeroMQ, MySQL, Redis, fastdfs, MongoDB, ZK, streaming, CDN, P2P, K8S, Docker, TCP/IP, coroutine, DPDK, ffmpeg, etc.) to share for free

6. Important header fields in the Http protocol
Above we said that the Http header field (header field) is generally divided into four types:
1. Common header field:
2. Request header field:
3. Response header field:
4. Entity header field
Let's pick a few of the first fields that are frequently asked to illustrate.
(1) Cache-Control
By specifying the instructions for the header field Cache-Control, you can manipulate the working mechanism of the cache.
The parameters of the instruction are optional, and multiple instructions are separated by a ",". The header field Cache-Control directives are available for request and response times.
Cache-Control: private, max-age=0, no-cache In the request, Cache-Control has the following optional directives:
In the response, Cache-Control has the following optional directives:
1.no-cache directive:
The purpose of using the no-cache directive is to prevent expired resources from being returned from the cache. If the request sent by the client contains a no-cache directive, it means that the client will not receive the cached response.
If the server returns a response that contains a no-cache directive, the cache server cannot cache the resource. The origin server will no longer confirm the validity of the resources proposed in the cache server request and prohibit it from caching the response resource.
2.no-store instructions:
Literally, it is easy to misinterpret no-cache as not caching, but in fact no-cache means not caching expired resources, and the cache processes resources after confirming the validity period to the origin server. No-store is really not caching.
3.max-age directive:
Cache-Control: max-age=604800(单位:秒) When the client sends a request that contains a max-age directive, the client receives the cached resource if it determines that the cache time value of the cached resource is smaller than the specified time value.
When the server returns a response that contains a max-age directive, the cache server does not confirm the validity of the resource, and the max-age value represents the maximum time that the resource is saved as cached
(2) Connection
The Connection header field has the following two functions.
1. Controls the header fields that are no longer forwarded to the agent.
Connection: 不再转发的首部字段名 Within the client sends a request and the server returns a response, use the Connection Header field to control which header fields are no longer forwarded to the agent.
2. Manage persistent connections.
Connection: close/Keep-Alive In the initial version of the HTTP protocol, a TCP connection was disconnected for every HTTP communication. If you have multiple Http requests at once, it's clear that each TCP/IP handshake and wave will incur some overhead.
The default connections for http/1.1 are persistent. To do this, the client sends requests continuously on the persistent connection. When the server side wants to explicitly disconnect, specify a value of Close for the Connection Header field.
The default connections for HTTP versions prior to HTTP/1.1 are non-persistent. For this reason, if you want to maintain persistent connections on older versions of the HTTP protocol, you need to specify a value of Keep-Alive for the Connection Header field.
(3) Transfer-Encoding
Transfer-Encoding specifies the encoding used when transmitting the body of a message.
For example:
Transfer-Encoding: chunked When the returned data is relatively large, if you wait for the data to be generated and then transmit, it is less efficient. In contrast, servers prefer to generate data while transferring. Chunked transfers can be identified in response headers with chunked fields.
Setting this field will automatically produce two effects:
The Content-Length field is ignored.
Continuously push dynamic content based on long connections.
How do I identify the completion of the transfer?
After several data blocks have been transferred, an empty data block needs to be transferred. When the client receives an empty block of data, the client knows that the data has been received.
(4) Accept
The Accept Header field notifies the server of the type of media that the client can process and the relative priority of the media type. You can use type/subtype to specify multiple media types at once.
Accept: text/html,application/xhtml+xml,application/xml;q=0. (5) Accept-Encoding
The Accept-Encoding header field is used to tell the server client what content encoding is supported and the order in which content encoding is prioritized. You can specify multiple content encodings at once.
Accept-Encoding: gzip, deflate Here are a few examples of content encoding.
gzip:
The encoding format (RFC1952) generated by the file compressor gzip (GNU zip) uses the Lempel-Ziv algorithm (LZ77) and the 32-bit cyclic redundancy check (commonly known as the CRC).
compress:
The encoding format generated by the UNIX file compressor compress uses the Lempel-Ziv-Welch algorithm (LZW).
deflate:
Use a combination of zlib format (RFC1950) and encoding formats generated by the deflate compression algorithm (RFC1951).
identity:
No compression is performed or the default encoding format does not change
(6) Accept-Language
The header field Accept-Language is used to tell the server that the languages supported by the client are Chinese or English, etc.), and the relative priority of support. You can specify multiple languages at once.
(7) If-Modified-Since
If-Modified-Since is used to confirm the validity of local resources owned by the proxy or client. Gets the update datetime for the resource, which can be determined by confirming the header field Last-Modified.
After specifying the datetime of the If-Modified-Since field value, a response with status code 304 Not Modified is returned if none of the requested resources have been updated. Otherwise, the server responds to the request.
(8) Range
Range: bytes=5001-10000 For scope requests that only need to get a subset of resources, include the header field Range to tell the server resource of the specified scope. The example above represents a request to get a resource from byte 5001 to 10000.
Servers that receive a request with a Range header field return a response with a status of 206 Partial Content after processing the request. When the range request cannot be processed, the response with status code 200 OK and all resources are returned.
(9) User-Agent
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:13.0) Gecko/201 User-Agent passes information such as the browser and user agent name of the request to the server.
(10) ETag
ETag: "82e22293907ce725faf67773957acd12" The ETag tells the client entity identity. It is a way to uniquely identify a resource as a string. The server assigns a corresponding ETag value to each resource.
When resources are updated, the ETag values also need to be updated. ETag values are assigned by the server.
(11) Allow
Allow: GET, HEAD Allow is used to notify the client of all HTTP methods that can support the specified resource. When the server receives an unsupported HTTP method, it returns in response with status code 405 Method Not Allowed. At the same time, all supported HTTP methods are written to the header field Allow and returned.
(12) Content-Encoding
Content-Encoding: gzip Content-Encoding tells the client server how to encode the content for the body portion of the entity. Content encoding refers to compression without losing entity information.
(13) Content-Length
Content-Length: 15000 Content-Length indicates the size of the body of the entity (units are bytes).
(14) Content-Range
Content-Range: bytes 5001-10000/10000 For scope requests, content-Range is used when returning a response to tell the client which part of the entity returned as a response matches the scope request. The field value, in bytes, represents the current send portion and the entire entity size.
(15) Content-Type
Content-Type: text/html; charset=UTF-8 Content-Type describes the media type of an object within an entity body. As with Accept, field values are assigned as type/subtype.
(16) Expires
Expires: Wed, 04 Jul 2012 08:26:05 GMT Expires informs the client of the date the resource expires.
If Cache-Control has a max-age directive specified, the max-age directive is handled in preference to Expires.
(17) Last-Modified
Last-Modified: Wed, 23 May 2012 09:59:55 GMT The header field Last-Modified indicates when the resource was finally modified.
7. Talk about cookies
HTTP is a stateless protocol where each http request is independent and agnostic, and state information does not need to be preserved by default. But sometimes you need to save some state, what to do?
Http introduces Cooike technology to solve the problems described above. Cookie technology controls the state of the client by writing cookie information in request and response messages.
A cookie is essentially a small text file stored inside the browser and stored internally in key-value pairs.
The cookie informs the client to save the cookie based on the header field information in the response message sent from the server called a Set-Cookie.
When the next time the client sends another request to the server, the client automatically adds a cookie value to the request packet and sends it out. After the server finds the cookie sent by the client, it will check which client the connection request is from, then compare the records on the server and finally get the previous status information.
The flow of cookie interaction is roughly as follows:
Cookie lifetime
The validity period of a cookie can be set by the Epiles and Max-Age properties.
Expires indicates the expiration time
Max-Age is calculated at intervals of time, in seconds, starting when the browser receives a message.
If the cookie expires, the cookie is deleted and is not sent to the server.
Cookie scope
There are also two properties about the scope: Domain and path, the cookie is bound to the domain name and path, before sending the request, if the domain name or path does not match these two properties, then the cookie will not be taken. It is worth noting that for paths, / means that any path under the domain name allows the use of cookies.
HttpOnly property
The HttpOnly property of a cookie is an extension of cookies that can only be transmitted over the HTTP protocol, which makes it impossible for JS scripts to obtain cookies. Its main purpose is to prevent cross-site scripting (XSS) information theft from cookies.
Correspondingly, for the prevention of CSRF attacks, there is also a SameSite attribute.
Disadvantages of cookies
Capacity defects: Cookies are limited to a maximum of 4 KB and can only be used to store a small amount of information.
Performance defects: Cookies follow the domain name, regardless of whether a certain address below the domain name needs to need this cookie, the request will carry a complete cookie, so that as the number of requests increases, it will actually cause a huge performance waste, because the request carries a lot of unnecessary content. However, this can be solved by specifying scopes for Domain and Path.
Security flaws: Since cookies are passed in plain text in the browser and server, they can easily be intercepted by illegal users, and then a series of tampering is carried out to resend to the server during the validity period of the cookie, which is quite dangerous. In addition, if HttpOnly is false, the cookie information can be read directly through the JS script.
8. Talk about http proxies
HTTP is a protocol based on the request-response model, which is generally requested by the client and responded by the server. Sometimes, however, the client's request does not go directly to the origin server. In order to solve some problems, there may be a proxy server for transit during the request process.
What does a proxy server do?
1. Load balancing. The client's request will first reach the proxy server, and after the proxy server can get this request, it can be distributed to different source servers through specific algorithms, so that the load of each source server is as even as possible.
2. Ensure safety. Use the heartbeat mechanism to monitor servers in the background and kick faulty machines out of the cluster as soon as they are spotted. And filter the data on the upper and lower rows to limit the flow of illegal IPs.
3. Cache proxy. Caching content to a proxy server so that clients can get it directly from the proxy server instead of going to the origin server.
9. Talk about Http caching
HTTP's caching mechanism is implemented by relying on the value of the header field in the request and response headers, and the important fields we have described above are ultimately taken from the cache or re-pulled from the server. The overall process we still borrow a diagram to summarize it simply:
Http caching can be divided into two types:
Forced caching: The server does not need to participate in judging whether to continue to use the cache again, when the client requests data for the first time, the server returns the expiration time of the cache (Expires and Cache-Control), and can continue to use the cache without expiration, otherwise it will not be used and there is no need to ask the server.
Comparison cache: the server side needs to participate in judging whether to continue to use the cache again, when the client requests data for the first time, the server will return the cache identity (Last-Modified/If-Modified-Since and Etag/If-None-Match) to the client together with the data, the client will back up both to the cache, when the data is requested again, the client will send the cache ID of the last backup to the server, and the server will judge according to the cache ID , if 304 is returned, it informs the client that the cache can continue to be used. Otherwise, it will be returned to the client with the latest data.
Forced caching takes precedence over contrast caching. The two identities used to force caching are mentioned above:
Expires: The value of Expires is the expiration time returned by the server, that is, the next request, the request time is less than the expiration time of the server-side return, and the cache data is directly used. The expiration time is generated by the server, and the time between the client and the server may be incorrect.
Cache-Control: Expires has a time check problem, and all HTTP1.1 use Cache-Control instead of Expires.
We also mentioned above that there are several values for Cache-Control:
private: The client can cache. public: Both the client and the proxy server can be cached.
max-age=xxx: Cached content will expire after xxx seconds
no-cache: A contrast cache is required to validate the cached data.
no-store: All content will not be cached, forced caching, comparison caching will not be triggered. Let's look at the two identities of the comparison cache:
Last-Modified/If-Modified-Since Last-Modified indicates the last time a resource was modified. When the client sends the first request, the server returns the time when the resource was last modified:
Last-Modified: Tue, 12 Jan 2016 09:31:27 The GMT client sends again and carries If-Modified-Since in the header. Pass the resource time returned by the last server to the server.
If-Modified-Since: Tue, 12 Jan 2016 09:31:27 GMT server received the resource modification time sent by the client, compared with its current resource modification time, if its own resource modification time is greater than the resource modification time sent by the client, then the resource has been modified, then return 200 indicates that the resource needs to be re-requested, otherwise return 304 means that the resource has not been modified, you can continue to use the cache. The above is a timestamp to mark whether the resource is modified, there is also a way to mark the resource identification code ETag whether to modify, if the identification code changes, it means that the resource has been modified, ETag priority is higher than Last-Modified. Etag/If-None-Match ETag is an identifier for resource files, when the client sends the first request, the server will return the current resource's tag code: ETag: "5694c7ef-24dc" The client sends again, and will carry the resource identification code returned by the last server in the header: If-None-Match: "5694c7ef-24dc" The server receives the resource identification code sent by the client. It will be compared with its current resource, if it is different, it means that the resource has been modified, then 200 is returned, if the same means that the resource has not been modified, returning 304, the client can continue to use the cache.
10. Talk about the shortcomings of Http
The main disadvantages of HTTP are actually not secure enough, mainly the following three points:
1. Communications are in clear text (not encrypted) and content may be eavesdropped.
2. The identity of the communicating party is not verified, so there is a possibility of camouflage.
3. The integrity of the message cannot be proved, so it may have been tampered with.