Written by | Rachel King
Translated by | Sambodhi
Planning | Yanyuan Garden
In 2018, Etsy migrated its service infrastructure from a self-managed data center to a cloud configuration (we blogged about it at the time). This change provides an opportunity to improve technology processes across the company. For the Search team, the flexible scaling of the cloud environment allowed us to completely re-evaluate a somewhat cumbersome deployment process. Inspired by existing canary release architecture patterns, we wrote a new custom tool to complement the existing deployment infrastructure.
After three months of hard work, we ended up with a more scalable, developer-friendly, and ultimately more robust way to roll out changes to Search.
Blue-green deployment
In the past, we deployed stacks on two separate sets of hosts, the so-called "blue-green strategy." At any one time, only one set of hosts is active; the other group, or "side", is in a "dark" state. Both sides are fully scalable and ready to serve traffic, but only the active one has access to the public internet.
The blue-green deployment strategy, while simple, has some useful features:
For search applications, we can make important changes on one side because it is stateful, while continuously using the other side to provide traffic.
Before sending production traffic to it, we have a place to test the changes manually.
We always have a previous version of Search that we can easily recover in an emergency.
There is also a built-in mechanism to test and produce other breakthrough changes, such as software version upgrades.
We refer to these two sets of hosts as "flip" and "flop", which are named after the circuits, the basic building blocks of modern computers. In the configuration file, we point a single PHP web app to which group with a few lines of code, and which group should be active.
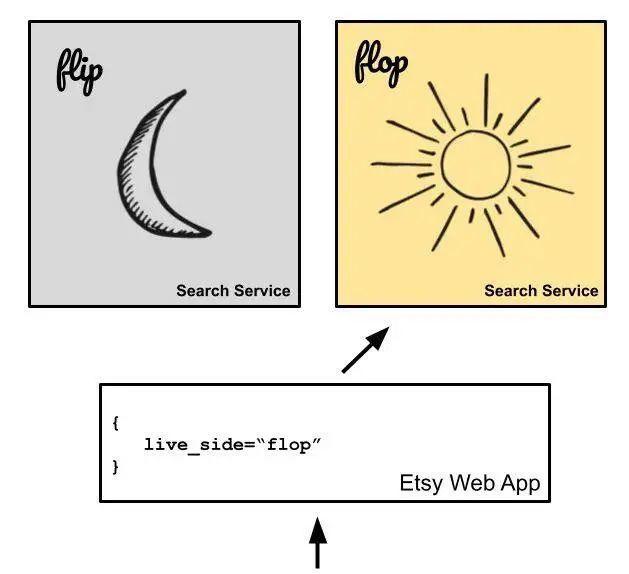
The picture shows our previous infrastructure. One set (flops in this example) is always active, and during deployment, we move all the traffic to another group at once (flip in this example).
When Etsy moved to the cloud three years ago, this approach to blue-green deployment was "elevated and shifted." The Search team moved the search app to the Google Kubernetes Engine (GKE), and flip and flop became two separate production Kubernetes namespaces.
This change aside, things work the same way they always did: deploying Search immediately triggers all traffic to redirect from one namespace—the active side—to the same service running in another namespace. To ensure that the dark side is always ready, we will continue to maintain 200% capacity (100% per production namespace) at all times, as we did when we were on-premises.
This initial deployment strategy was very useful for the team, especially as it provided us with a secure space to test and prepare for major software updates and infrastructure changes. However, it is not without pain. Suddenly, all the flow is diverted to both sides, which leaves us no room to test a small amount of variation in production flow before putting it all in. Even when things go well, deployment can be stressful. If something goes wrong, engineers have to do a shunt to decide whether to fully restore the status quo ante. On top of that, maintaining double capacity for a long time is expensive and inefficient.
Because cloud computing provides flexibility, once we safely enter GKE, we have the opportunity to rethink our blue-green strategy and address these long-standing problems.
Canary (Lite)
Our first idea was to adopt a canary deployment strategy. During a Canary Release, a small portion of the traffic is sent to the new version of the service before all traffic is switched to the new service to determine if it is "secure."
Why is it called that? Coal miners used to use canaries to detect the concentration of carbon monoxide, which could hurt a bird but still not hurt people. Software engineers have adopted a similar model (albeit more humanely) to build confidence that new software can safely serve traffic.
While Kubernetes' architecture and flexible scaling mean that Canary Publish is a very popular deployment solution, the design of Etsy's search system means we can't use any off-the-shelf Canary Release solution. We have to build something new for ourselves, a canary lite.
There are two key limitations when considering rebuilding the deployment process that integrates canary components.
The first limitation is that we cannot control the amount of incoming traffic using a single load balancer live API power outage. This way, we can't use Kubernetes tags to do basic canary publishing for any search service on a single Kubernetes deployment, because Search is made up of many different Kubernetes deployments. We don't have the place to set up routing logic to check the labels, and the corresponding routes to canary pods.
However, Etsy's PHP web app is the only client for the search app. For Etsy, this is a common pattern, so configuring load balancing is typically managed directly in the web app itself. Any new deployment solution would either have to manage traffic for the web app to search inside the web app, or implement some kind of entirely new mesh network (such as Istio) to capture and direct all traffic to the web app for Search. Neither scenario is feasible within the time frame assigned to the project.
The second limitation is that the search app assumes that the same version of all search services in the request path will serve any single web request. Therefore, the deployment of any new solution needs to ensure that all older versions of the search service can satisfy ongoing search requests. Even a complex canary release solution like Istio requires your app to handle version mismatches between different services, which we can't guarantee.
So, how do we create a step-by-step rollout process for all new versions of the search service, while managing load balancing for all parts from web apps to rolling releases, and guaranteeing that the search service can only talk to the same version as other search services? There is no ready-made solution to this Etsy-specific problem. So we developed a whole new tool called Switchboard.
Go to Switchboard
Switchboard's primary function is to manage traffic: it rolls out a deployment to production by gradually increasing the percentage available to the new active side and proportionally reducing the number of incoming old active ends.
Deployment phases with a pre-defined proportion of traffic are hard-coded into the system, and Switchboard transitions to the next phase when all Pods added in the current rolling release phase are fully created and operational. This is achieved by editing and submitting a new traffic percentage to the profile in the web app. The web application rechecks the file for every mood and uses this information to load balance search traffic between two different production Kubernetes namespaces, still known as flip and flop.

An example of using a one-sided switch on Switchboard. Smoke testing takes place at 16:57 and 17:07.
Switchboard largely automates the migration of traffic from one search terminal to another during deployment. Smoke tests run at different stages of deployment, sending human-created and real-world historical search query requests to the new end. Developers only need to monitor the charts to ensure that the rolling releases are running smoothly.
The engineer driving the deployment manages switchboard through a user interface that shows the current rolling release status, and it can also choose to pause or roll back the deployment.
In Switchboard, we rely primarily on Kubernetes' built-in auto scaling capabilities to scale new clusters during deployment. Before we started sending production traffic to the cluster, we found that we only needed to scale up the cluster to 25% of our current capacity.
Kubernetes' built-in auto scaling is passive, so it's certainly slower than we force Search to scale before it needs additional capacity. In this way, it can help scale the new active side in advance, allowing for a faster response to the initial transition when that end goes live and starts receiving traffic. With Switchboard, Kubernetes can manage its own autoscaling capabilities, simply monitoring the rolling releases of Kubernetes to ensure that all services are healthy at this stage before deciding to upgrade.
Results
We designed Switchboard to improve the resource consumption of our Search system, and it's done just that. However, the step-by-step deployment approach also brings many nice workflow improvements to developers.
Switchboard allows us to keep the total capacity of search VMs at or near 100%, rather than the 200% capacity we previously supported, and as Search traffic increases, we no longer have to double the capacity. Nowadays, it's easier to adapt to the restlessness of traffic, as any additional passive (automatic) or active (manual) scaling only needs to reserve compute services for our true capacity, not double it. As a result, during the release of Switchboard, the utilization of cloud virtual machines improved significantly.
Over the past few months, the cloud cost per search request (total cloud billing/number of requests) has shown that we have improved our utilization efficiency after Switchboard.
The second success of Switchboard is that it has enabled us to deploy more and more speeds in Staging environments. Our first attempt to abandon the traditional dual-configuration approach was to completely scale down the unused search cluster between deployments and then reconfigure it in advance as the first step in the next deployment. One problem with this approach is that developers have to wait for all the services within our Search system to scale up enough to accept traffic before they can test in our Staging environment.
The time it took to deploy each Staging environment. Each individual row is a separate deployment.
Overall, after implementing Switchboard, we saw an increase in utilization similar to an intermediate solution, but without having to compromise on slower deployment times. Switchboard has even improved the efficiency of intermediate solutions.
It's also easier to spot and respond to issues during deployment. Technically, Search is deployed longer than we would have maintained two fully scaled clusters, but this extra time is due to the gradual nature of the automatic traffic rolling release process. Human search deployers typically passively monitor the rolling release phase with no interaction at all. However, if they need to, they can pause the rolling release to check the current results. Search deployers use Switchboard at least once a month to pause rolling releases. We didn't have this option at all before. Individual deployments of Switchboard have become more secure and reliable.
Finally, re-architecting our blue-green deployment process, including canary-style incremental traffic ramp-up via Switchboard, makes our system more scalable and efficient, while also providing developers with a better experience design. To take advantage of the flexibility of Kubernetes and the cloud environment, we successfully adapted the architecture of the search application.
https://codeascraft.com/2021/06/15/improving-the-deployment-experience-of-a-ten-year-old-application/