本節書摘來自華章計算機《storm企業級應用:實戰、運維和調優》一書中的第1章,第1.2節,作者:馬延輝 陳書美 雷葆華著, 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
本節主要通過介紹storm出現的背景、簡介、設計思想、與大資料架構hadoop的比較等内容,使讀者了解storm的設計理念,從整體感觀上切入,并快速掌握storm。
1.2.1 storm出現的背景
網際網路從誕生的第一時間起,對世界的最大改變就是讓資訊能夠實時互動,進而大大加速了各個環節的效率。正因為大家有對資訊實時響應、實時互動的需求,是以軟體行業除了個人作業系統之外,資料庫(更精确的說是關系型資料庫)應該是發展最快、收益最為豐厚的産品了。記得十年前,很多銀行别說實時轉賬,連實時查詢都做不到,但是資料庫和高速網絡改變了這個情況。
随着網際網路的更進一步發展,從portal資訊浏覽型到search資訊搜尋型到sns關系互動傳遞型,以及電子商務、網際網路旅遊生活産品等将生活中的流通環節線上化。對效率的要求進一步提升了對實時性的要求,而資訊的互動和溝通正在從點對點向資訊鍊,甚至資訊網的方向發展,這樣必然帶來資料在各個次元的交叉關聯,資料爆炸已不可避免。是以流式處理加nosql産品應運而生,分别解決實時架構和資料大規模存儲計算的問題。早在7、8年前,諸如uc伯克利、斯坦福等大學就開始了對流式資料處理的研究,但是由于更多的關注于金融行業的業務場景或者網際網路流量監控的業務場景,以及當時網際網路資料場景的限制,造成了研究多是基于對傳統資料庫處理的流式化,對流式架構本身的研究偏少。目前這樣的研究逐漸沒有了聲音,工業界将更多的精力轉向了實時資料庫。
2010年yahoo!對s4的開源、2011年twitter對storm的開源,改變了這個情況。以前網際網路的開發人員在做一個實時應用時,除了要關注應用邏輯計算處理本身外,還要為了資料的實時流轉、互動、分布大傷腦筋。但是現在情況卻大為不同,以storm為例,開發人員可以快速地搭建一套健壯、易用的實時流處理架構,配合sql産品、nosql産品或者mapreduce計算平台,就可以低成本地做出很多以前很難想象的實時産品。例如,一淘資料部的量子恒道品牌旗下的多個産品就是建構在實時流處理平台上的。
1.2.2 storm簡介
storm是twitter開源的、分布式的、容錯的實時計算系統,遵循eclipse public license 1.0。storm通過簡單的api使開發者可以可靠地處理無界持續的流資料,進行實時計算。twitter storm是使用clojure(發音同closure)語言實作的。clojure是lisp語言的一種現代方言。類似于lisp,clojure支援一種功能性程式設計風格,但clojure還引入了一些特性來簡化多線程程式設計(一種對建立storm很有用的特性)。clojure是一種基于虛拟機(vm)的語言,在java虛拟機上運作。盡管storm是使用clojure語言開發的,但是仍然可以在storm中使用幾乎任何語言編寫應用程式,所需的隻是一個連接配接到storm架構的擴充卡。已存在針對scala、jruby、perl和php的擴充卡,但是還有支援流式傳輸到storm拓撲結構中的結構化查詢語言擴充卡——可以通過标準輸入、标準輸出以json格式協定與storm通信。
storm可以友善地在一個計算機叢集中編寫與擴充複雜的實時計算,storm之于實時處理,就好比hadoop之于批處理。storm保證每個消息都會得到處理,而且它很快——在一個小叢集中,每秒可以處理數以百萬計的消息。storm的處理速度非常驚人:經測試,每個節點每秒可以處理100萬個資料元組。
1.2.3 storm的設計思想
在storm中也有對流(stream)的抽象,流是一個不間斷的、無界的連續tuple(storm在模組化事件流時,把流中的事件抽象為tuple即元組)。storm認為每個流都有一個stream源,也就是原始元組的源頭,是以它将這個源頭抽象為spout,spout可能連接配接twitter api并不斷發出推文(tweet),也可能從某個隊列中不斷讀取隊列元素并裝配為tuple發射。
有了源頭即spout也就是有了流,同樣的思想,twitter将流的中間狀态轉換抽象為bolt,bolt可以消費任意數量的輸入流,隻要将流方向導向該bolt,同時它也可以發送新的流給其他bolt使用,這樣一來,隻要打開特定的spout(管口),再将spout中流出的tuple導向特定的bolt,由bolt處理導入的流後再導向其他bolt或者目的地。
假設spout就是一個一個的水龍頭,并且每個水龍頭裡流出的水是不同的,想獲得哪種水就擰開哪個水龍頭,然後使用管道将水龍頭的水導向到一個水處理器(bolt),水處理器處理後使用管道導向另一個處理器或者存入容器中。圖1-8和圖1-9為spout、tuple和bolt之間的關系和流程。
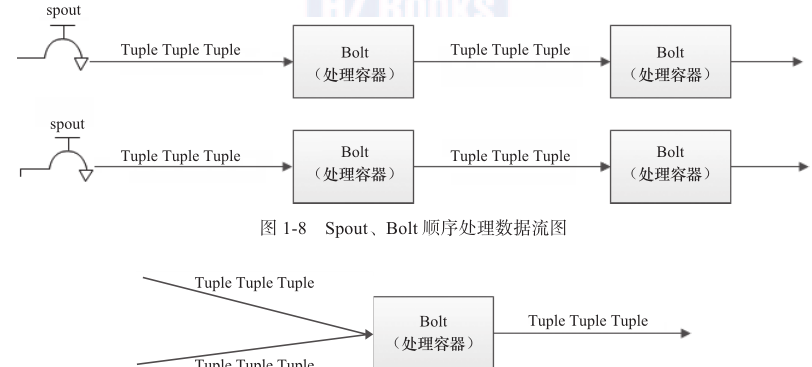
為了增大水處理效率,可以在同一個水源處接上多個水龍頭并使用多個水處理器,如
圖1-10所示。

對應上文的介紹,可以很容易地了解圖1-10,這是一張有向無環圖。storm将這個圖抽象為topology(即拓撲),拓撲是storm中最高層次的一個抽象概念,送出拓撲到storm叢集執行,一個拓撲就是一個流轉換圖。圖中的每個節點是一個spout或者bolt,圖中的邊是指bolt訂閱了哪些流。
1.2.4 storm與hadoop的角色群組件比較
storm叢集和hadoop叢集表面上看很類似。但是hadoop上運作的是mapreduce作業,而在storm上運作的是拓撲topology,這兩者之間是非常不同的。一個關鍵的差別是:一個mapreduce作業最終會結束,而一個topology拓撲會永遠運作(除非手動殺掉)。表1-1列出了hadoop與storm的不同之處。
如果隻用一個短語來描述storm,可能會是這樣:分布式實時計算系統。按照storm作者的說法,storm對于實時計算的意義類似于hadoop對于批處理的意義。衆所周知,根據google mapreduce來實作的hadoop提供了map和reduce原語,使批處理程式變得非常簡單和優美。那麼storm則是在批處理之前,及時處理了資料。
storm與其他大資料解決方案的不同之處在處理方式上。hadoop在本質上是一個批處理系統。資料被引入hdfs并分發到各個節點進行處理。當處理完成時,結果資料傳回到hdfs供始發者使用。storm支援建立拓撲結構來轉換沒有終點的資料流。不同于hadoop作業,這些轉換從不停止,它們會持續處理到達的資料。
hadoop專注于批處理。這種模型對許多情形(如為網頁建立索引)已經足夠,但還存在其他一些使用模型,它們需要來自高度動态來源的實時資訊。為了解決該問題,就得借助twitter推出的storm。storm不處理靜态資料,但它處理預計會連續的流資料。考慮到twitter使用者每天生成1.4億條推文,很容易看到此技術的巨大用途。
storm不隻是一個傳統的大資料分析系統:它是複雜事件處理(cep)系統的一個示例。cep系統通常分為計算和面向檢測兩類,其中每個系統都可通過使用者定義的算法在storm中實作。例如,cep可用于識别事件洪流中有意義的事件,然後實時處理這些事件。
storm作者nathan marz提供了在twitter中使用storm的大量示例。一個最有趣的示例是生成趨勢資訊。twitter從海量的推文中提取所浮現的趨勢,并在本地和國家級别維護這些趨勢資訊。這意味着當一個案例開始浮現時,twitter的趨勢主題算法就會實時識别該主題。這種實時算法是使用storm實作的基于twitter資料的一種連續分析。