本节书摘来自华章计算机《storm企业级应用:实战、运维和调优》一书中的第1章,第1.2节,作者:马延辉 陈书美 雷葆华著, 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
本节主要通过介绍storm出现的背景、简介、设计思想、与大数据框架hadoop的比较等内容,使读者了解storm的设计理念,从整体感观上切入,并快速掌握storm。
1.2.1 storm出现的背景
互联网从诞生的第一时间起,对世界的最大改变就是让信息能够实时交互,从而大大加速了各个环节的效率。正因为大家有对信息实时响应、实时交互的需求,所以软件行业除了个人操作系统之外,数据库(更精确的说是关系型数据库)应该是发展最快、收益最为丰厚的产品了。记得十年前,很多银行别说实时转账,连实时查询都做不到,但是数据库和高速网络改变了这个情况。
随着互联网的更进一步发展,从portal信息浏览型到search信息搜索型到sns关系交互传递型,以及电子商务、互联网旅游生活产品等将生活中的流通环节在线化。对效率的要求进一步提升了对实时性的要求,而信息的交互和沟通正在从点对点向信息链,甚至信息网的方向发展,这样必然带来数据在各个维度的交叉关联,数据爆炸已不可避免。因此流式处理加nosql产品应运而生,分别解决实时框架和数据大规模存储计算的问题。早在7、8年前,诸如uc伯克利、斯坦福等大学就开始了对流式数据处理的研究,但是由于更多的关注于金融行业的业务场景或者互联网流量监控的业务场景,以及当时互联网数据场景的限制,造成了研究多是基于对传统数据库处理的流式化,对流式框架本身的研究偏少。目前这样的研究逐渐没有了声音,工业界将更多的精力转向了实时数据库。
2010年yahoo!对s4的开源、2011年twitter对storm的开源,改变了这个情况。以前互联网的开发人员在做一个实时应用时,除了要关注应用逻辑计算处理本身外,还要为了数据的实时流转、交互、分布大伤脑筋。但是现在情况却大为不同,以storm为例,开发人员可以快速地搭建一套健壮、易用的实时流处理框架,配合sql产品、nosql产品或者mapreduce计算平台,就可以低成本地做出很多以前很难想象的实时产品。例如,一淘数据部的量子恒道品牌旗下的多个产品就是构建在实时流处理平台上的。
1.2.2 storm简介
storm是twitter开源的、分布式的、容错的实时计算系统,遵循eclipse public license 1.0。storm通过简单的api使开发者可以可靠地处理无界持续的流数据,进行实时计算。twitter storm是使用clojure(发音同closure)语言实现的。clojure是lisp语言的一种现代方言。类似于lisp,clojure支持一种功能性编程风格,但clojure还引入了一些特性来简化多线程编程(一种对创建storm很有用的特性)。clojure是一种基于虚拟机(vm)的语言,在java虚拟机上运行。尽管storm是使用clojure语言开发的,但是仍然可以在storm中使用几乎任何语言编写应用程序,所需的只是一个连接到storm架构的适配器。已存在针对scala、jruby、perl和php的适配器,但是还有支持流式传输到storm拓扑结构中的结构化查询语言适配器——可以通过标准输入、标准输出以json格式协议与storm通信。
storm可以方便地在一个计算机集群中编写与扩展复杂的实时计算,storm之于实时处理,就好比hadoop之于批处理。storm保证每个消息都会得到处理,而且它很快——在一个小集群中,每秒可以处理数以百万计的消息。storm的处理速度非常惊人:经测试,每个节点每秒可以处理100万个数据元组。
1.2.3 storm的设计思想
在storm中也有对流(stream)的抽象,流是一个不间断的、无界的连续tuple(storm在建模事件流时,把流中的事件抽象为tuple即元组)。storm认为每个流都有一个stream源,也就是原始元组的源头,所以它将这个源头抽象为spout,spout可能连接twitter api并不断发出推文(tweet),也可能从某个队列中不断读取队列元素并装配为tuple发射。
有了源头即spout也就是有了流,同样的思想,twitter将流的中间状态转换抽象为bolt,bolt可以消费任意数量的输入流,只要将流方向导向该bolt,同时它也可以发送新的流给其他bolt使用,这样一来,只要打开特定的spout(管口),再将spout中流出的tuple导向特定的bolt,由bolt处理导入的流后再导向其他bolt或者目的地。
假设spout就是一个一个的水龙头,并且每个水龙头里流出的水是不同的,想获得哪种水就拧开哪个水龙头,然后使用管道将水龙头的水导向到一个水处理器(bolt),水处理器处理后使用管道导向另一个处理器或者存入容器中。图1-8和图1-9为spout、tuple和bolt之间的关系和流程。
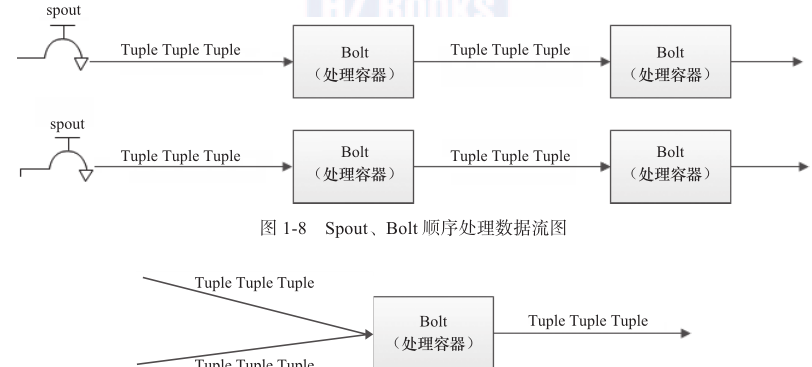
为了增大水处理效率,可以在同一个水源处接上多个水龙头并使用多个水处理器,如
图1-10所示。

对应上文的介绍,可以很容易地理解图1-10,这是一张有向无环图。storm将这个图抽象为topology(即拓扑),拓扑是storm中最高层次的一个抽象概念,提交拓扑到storm集群执行,一个拓扑就是一个流转换图。图中的每个节点是一个spout或者bolt,图中的边是指bolt订阅了哪些流。
1.2.4 storm与hadoop的角色和组件比较
storm集群和hadoop集群表面上看很类似。但是hadoop上运行的是mapreduce作业,而在storm上运行的是拓扑topology,这两者之间是非常不同的。一个关键的区别是:一个mapreduce作业最终会结束,而一个topology拓扑会永远运行(除非手动杀掉)。表1-1列出了hadoop与storm的不同之处。
如果只用一个短语来描述storm,可能会是这样:分布式实时计算系统。按照storm作者的说法,storm对于实时计算的意义类似于hadoop对于批处理的意义。众所周知,根据google mapreduce来实现的hadoop提供了map和reduce原语,使批处理程序变得非常简单和优美。那么storm则是在批处理之前,及时处理了数据。
storm与其他大数据解决方案的不同之处在处理方式上。hadoop在本质上是一个批处理系统。数据被引入hdfs并分发到各个节点进行处理。当处理完成时,结果数据返回到hdfs供始发者使用。storm支持创建拓扑结构来转换没有终点的数据流。不同于hadoop作业,这些转换从不停止,它们会持续处理到达的数据。
hadoop专注于批处理。这种模型对许多情形(如为网页建立索引)已经足够,但还存在其他一些使用模型,它们需要来自高度动态来源的实时信息。为了解决该问题,就得借助twitter推出的storm。storm不处理静态数据,但它处理预计会连续的流数据。考虑到twitter用户每天生成1.4亿条推文,很容易看到此技术的巨大用途。
storm不只是一个传统的大数据分析系统:它是复杂事件处理(cep)系统的一个示例。cep系统通常分为计算和面向检测两类,其中每个系统都可通过用户定义的算法在storm中实现。例如,cep可用于识别事件洪流中有意义的事件,然后实时处理这些事件。
storm作者nathan marz提供了在twitter中使用storm的大量示例。一个最有趣的示例是生成趋势信息。twitter从海量的推文中提取所浮现的趋势,并在本地和国家级别维护这些趋势信息。这意味着当一个案例开始浮现时,twitter的趋势主题算法就会实时识别该主题。这种实时算法是使用storm实现的基于twitter数据的一种连续分析。