本節書摘來自異步社群出版社《圖資料庫(第2版)》一書中的第2章,第2.3節,作者:【美】ian robinson(伊恩•羅賓遜) , jim webber(吉姆•韋伯) , emil eifrem(埃米爾•艾弗雷姆),更多章節内容可以通路雲栖社群“異步社群”公衆号檢視。
前面的例子處理了<code>隐式的</code>關聯資料。作為使用者,我們推斷實體之間的語義相關性,但資料模型與資料庫本身卻忽視了這些關聯。為了彌補這一點,我們的應用程式必須着手建立一個扁平的、無連接配接的資料之外的網絡,然後再處理那些由反規範化存儲導緻的緩慢查詢和延遲寫入。
我們真正想要的是一個全景圖,包括元素之間的關聯。與我們之前看到的不同,在圖的世界中,關聯資料被存儲為<code>關聯資料</code>。隻要問題域中存在關聯,資料中就存在關聯,如圖2-5表示的社交網絡。
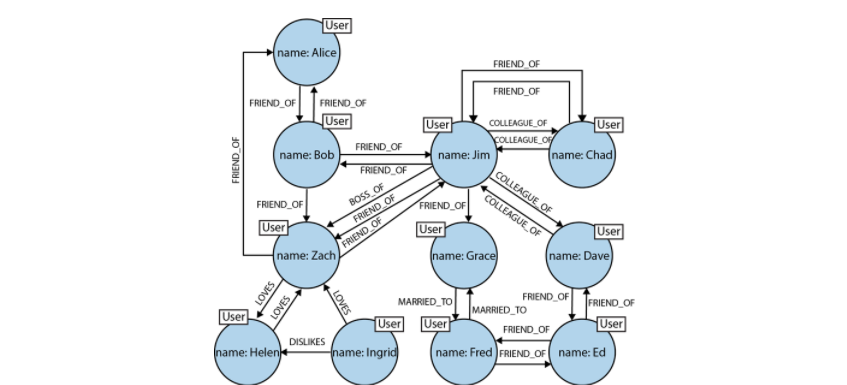
在這個社交網絡中,有如此多的實際情景中的關聯資料,但實體之間的關聯在領域之間并沒有表現得一緻—域是結構可變的。社交網絡是一個非常流行的密集關聯、結構可變的網絡的例子,它不該被作為一個普适模式,也不該被分割成多個無關聯的聚合資料。這個簡單的朋友網絡已經在規模上成長(潛在的朋友關系的距離已經深達6度),在表現力上豐富起來。圖模型的靈活性使我們能增加新的節點和新的聯系,與此同時不影響現有網絡,也不用做資料遷移—原始資料和其意圖都保持不變。
這個圖為該網絡提供了更豐富的資訊。我們可以看到誰loves(愛着)誰(無論這愛是不是在單相思),也可以看到誰是誰的colleague_of(同僚),誰是所有人的boss_of(老闆)。我們可以看到誰遠離市場,因為他們和别人是married_to(結婚)聯系。我們甚至可以在其他社交網絡中發現不善交際的元素,用dislikes(不喜歡)聯系來表示。有了我們所掌握的這個圖,我們現在就可以看看圖資料庫在處理關聯資料時的性能優勢了。
圖中的關系自然地形成了路徑。查詢圖或是周遊圖都涉及路徑。由于從根本上說,資料模型是面向路徑的,多數基于路徑的圖資料庫的操作都與資料模型本身呈現高度一緻性,是以它們極為高效。在<code>neo4j in action</code>一書中,<code>partner</code>和<code>vukotic</code>同時使用關系存儲和<code>neo4j</code>進行實驗。實驗通過對比表明,在處理關聯資料方面,圖資料庫(這裡是指<code>neo4j</code>及其周遊架構)比關系存儲要快得多。
圖中的标簽
我們市場希望在網絡中通過節點所扮演的角色對其進行分類。比如,有些節點可能代表使用者,而其他的代表訂單或産品。在neo4j中,使用labels表示節點在圖中扮演的角色。由于一個節點在圖中可以滿足多種不同角色,是以neo4j允許使用者對一個節點添加多個标簽。
這樣使用标簽可以對節點分類。比如,我們可以詢問資料庫來尋找所有标簽為user的節點。(标簽也提供了鈎子來聲明式地索引節點,之後會提及。)本書後面部分的示例中會廣泛用到标簽。我們給表示使用者的節點添加user标簽,給表示訂單的節點添加order标簽,諸如此類。下一章将會解釋标簽的文法。
partner和vukotic的實驗試圖在一個社交網絡裡找到最大深度為5的朋友的朋友。對于一個包含100萬人,每人約有50個朋友的社交網絡,結果明顯表明,圖資料庫是用于關聯資料的最佳選擇,如表2-1所示。

在深度為2時(即朋友的朋友),假設在一個線上系統中使用,無論關系型資料庫還是圖資料庫,它們的執行時間都表現得足夠好。雖然neo4j的查詢時間是關系資料庫的2/3,但終端使用者很難注意到兩者間毫秒級的時間差異。當深度為3時(即朋友的朋友的朋友),很明顯關系型資料庫無法在合理的時間内實作查詢了:一個線上系統無法接受30 s的查詢時間。相比之下,neo4j的響應時間則保持相對平坦:執行查詢僅需要不到1 s,這對線上系統來說足夠快了。
在深度為4時,關系型資料庫表現出很嚴重的延遲,使其無法應用于線上系統。neo4j所花時間也有所增加,但其時延處于線上系統的可接受範圍内。最後,在深度為5時,關系型資料庫所花時間過長以至于沒有完成查詢。相比之下,neo4j在2 s左右的時間就傳回了結果。在深度為5時,事實證明幾乎整個網絡都是我們的朋友。是以,在很多實際用例中,我們可能需要修剪查詢結果,進而縮短時長。
聚合存儲和關系型資料庫對于超出中等規模的集合操作(那些它們本該做得不錯的)表現得都不太好。當我們試圖從圖中挖掘路徑資訊時(比如朋友的朋友那個例子),操作慢了下來。我們并非想要貶低聚合存儲和關系型資料庫。它們在各自所擅長的方面有很好的技術能力,但在管理關聯資料時卻無能為力。任何超出尋找直接朋友或是尋找朋友的朋這樣的淺周遊的查詢,都将因為涉及的索引數量過多而使查找變得緩慢。而圖資料庫由于使用了免索引鄰接,確定了周遊關聯資料是非常迅速的。
社交網絡這個例子有助于說明不同的技術是如何處理關聯資料的,但它是否是有效用例呢?我們是否真的需要尋找這樣遠的“朋友”呢?也許不是。但将社交網絡替換為任何其他領域時,你會發現我們在性能、模組化和維護方都能面獲得類似的好處。無論是音樂領域還是資料中心管理,無論是生物資訊還是足球統計,無論是網絡傳感器還是時序交易,圖都能對這些資料提供強有力而深入的了解。讓我們來看看圖在當代的另一個應用:基于使用者自己的購買曆史和他的朋友、鄰居以及其他喜歡他的人的購買曆史為他推薦商品。這個例子中,我們能将使用者生活方式中多個獨立的方面彙集起來,做出準确而有商業意義的推薦。
首先,我們将使用者的購買曆史模組化為關聯資料。這在圖中很簡單,隻需将使用者和他的訂單連結起來,然後我們再将這些訂單連結為購買曆史,如圖2-6所示。
圖2-6所示的圖深入洞察了消費者的行為。我們可以看到使用者已經訂購(<code>placed</code>)的所有訂單,同時可以容易地推出每個訂單包含(<code>contains</code>)了什麼。對這個核心領域資料結構,我們已經添加了對幾種熟知的通路模式的支援。例如,使用者往往希望看到自己的訂單曆史,是以我們在圖中增加一個連結清單結構,這樣我們可以通過向外的最近(<code>most_recent</code>)聯系找到使用者最近的訂單。随後,我們可以通過疊代該連結清單,沿着每個上一個(<code>previous</code>)聯系回溯到更早的訂單。如果我們希望找到更近的訂單,我們則可以反向尋找<code>previous</code>聯系,或者添加一個反向的下一個(<code>next</code>)聯系。
現在我們可以開始進行推薦了。如果我們發現許多購買草莓冰淇淋的使用者還購買了意大利咖啡豆,我們就可以推薦那些通常隻買冰淇淋的使用者也去買意大利咖啡豆。這隻不過是個一維的推薦:我們可以做得更好。為了提高圖的能力,我們可以将其與其他領域的圖連接配接起來。由于圖天然是多元結構,是以可以更直接地提出更複雜的問題,以此獲得市場需要微調的部分。例如,我們可以通過圖知道“喜歡意式咖啡但不喜歡球芽甘藍的人喜歡什麼口味的冰淇淋,以及哪些人住在某個特定的街區。”
為了解釋資料,我們需要考慮反複購買同一商品的使用者在多大程度上象征着他喜歡這款商品。但如何才能定義“住在附近”?事實證明,地理坐标可以被很友善地模組化為圖。最流行的表示地理坐标的結構被稱為<code>r樹</code>。r樹是描述有邊界區域的類圖索引。使用這樣的結構可以描述地理區域的重疊層次。例如,我們可以陳述一個事實,倫敦在英國,郵編為sw111bd的地方在巴特西,這是倫敦的一個區域,倫敦在英格蘭的東南部,而英格蘭在英國。而由于英國的郵政編碼粒度很細,是以可以把郵編作為标準來界定有相似口味的目标人群。[1]
在sql中或是聚合存儲中寫這樣的模式比對查詢都非常困難,并且其查詢性能都很不好。而圖資料庫在這方面做了優化,能夠在這類周遊和模式比對查詢方面提供精确到毫秒級别的響應。此外,多數圖資料庫提供了适合表達圖結構和圖查詢的查詢語言。下一章我們将講解cypher,這是一個适合描述圖的模式比對語言。
除了可以用例子中的圖向使用者進行推薦,我們還能借此使賣方獲益。例如,對于某些購買模式(商品、典型訂單的價格等),我們能建立模式來判斷特定的事務是否是潛在的欺詐。通過圖可以很簡單地識别特定使用者的非正常模式,進而能将其标記出來用于進一步關注(可以使用關于圖的資料挖掘文獻中的知名的相似性度量方法),進而減少賣方的風險。[2]
從資料從業者的角度來看,很明顯,圖資料庫是處理複雜的、結構可變的、密集關聯的資料的最好的技術,也就是說,對于如此複雜的資料,使用别的方式處理遠不如使用圖實用。