本節書摘來自華章出版社《深入淺出dpdk》一書中的第2章,第2.5節cache預取,作者朱河清,梁存銘,胡雪焜,曹水 等,更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
2.5 cache預取
以上章節講到了多種和cache相關的技術,但是事實上,cache對于絕大多數程式員來說都是透明不可見的。程式員在編寫程式時不需要關心是否有cache的存在,有幾級cache,每級cache的大小是多少;不需要關心cache采取何種政策将指令和資料從記憶體中加載到cache中;也不需要關心cache何時将處理完畢的資料寫回到記憶體中。這一切,都是硬體自動完成的。但是,硬體也不是完全智能的,能夠完美無缺地處理各種各樣的情況,保證程式能夠以最優的效率執行。是以,一些體系架構引入了能夠對cache進行預取的指令,進而使一些對程式執行效率有很高要求的程式員能夠一定程度上控制cache,加快程式的執行。
接下來,将簡單介紹一下硬體預取的原理,通過英特爾netburst架構具體介紹其預取的原則,最後介紹軟體可以使用的cache預取指令。
2.5.1 cache的預取原理
cache之是以能夠提高系統性能,主要是程式執行存在局部性現象,即時間局部性和空間局部性。
1)時間局部性:是指程式即将用到的指令/資料可能就是目前正在使用的指令/資料。是以,目前用到的指令/資料在使用完畢之後可以暫時存放在cache中,可以在将來的時候再被處理器用到。一個簡單的例子就是一個循環語句的指令,當循環終止的條件滿足之前,處理器需要反複執行循環語句中的指令。
2)空間局部性:是指程式即将用到的指令/資料可能與目前正在使用的指令/資料在空間上相鄰或者相近。是以,在處理器處理目前指令/資料時,可以從記憶體中把相鄰區域的指令/資料讀取到cache中,這樣,當處理器需要處理相鄰記憶體區域的指令/資料時,可以直接從cache中讀取,節省通路記憶體的時間。一個簡單的例子就是一個需要順序處理的數組。
所謂的cache預取,也就是預測資料并取入到cache中,是根據空間局部性和時間局部性,以及目前執行狀态、曆史執行過程、軟體提示等資訊,然後以一定的合理方法,在資料/指令被使用前取入cache。這樣,當資料/指令需要被使用時,就能快速從cache中加載到處理器内部進行運算和執行。
以上介紹的隻是基本的預取原理,在不同體系架構,甚至不同處理器上,具體采取的預取方法都可能是不同的。以下以英特爾netburst架構的處理器為例介紹其預取的原則。詳細内容請參見[ref2-1]。
2.5.2 netburst架構處理器上的預取
在netburst架構上,每一級cache都有相應的硬體預取單元,根據相應原則來預取資料/指令。由于篇幅原因,僅以一級資料cache進行介紹。
1.一級資料cache的預取單元
netburst架構的處理器上有兩個硬體預取單元,用來加快程式,這樣可以更快速地将所需要的資料送到一級資料cache中。
1)資料cache預取單元:也叫基于流的預取單元(streaming prefetcher)。當程式以位址遞增的方式通路資料時,該單元會被激活,自動預取下一個cache行的資料。
2)基于指令寄存器(instruction pointer,ip)的預取單元:該單元會監測指令寄存器的讀取(load)指令,當該單元發現讀取資料塊的大小總是相對固定的情況下,會自動預取下一塊資料。假設目前讀取位址是0xa000,讀取資料塊大小為256個位元組,那位址是0xa100-0xa200的資料就會自動被預取到一級資料cache中。該預取單元能夠追蹤的最大資料塊大小是2k位元組。
不過需要指出的是,隻有以下的條件全部滿足的情況下,資料預取的機制才會被激活。
1)讀取的資料是回寫(writeback)的記憶體類型。
2)預取的請求必須在一個4k實體頁的内部。這是因為對于程式員來說,雖然指令和資料的虛拟位址都是連續的,但是配置設定的實體頁很有可能是不連續的。而預取是根據實體位址進行判斷的,是以跨界預取的指令和資料很有可能是屬于其他程序的,或者沒有被配置設定的實體頁。
3)處理器的流水線作業中沒有fence或者lock這樣的指令。
4)目前讀取(load)指令沒有出現很多cache不命中。
5)前端總線不是很繁忙。
6)沒有連續的存儲(store)指令。
在該硬體預取單元激活的情況下,也不一定能夠提高程式的執行效率。這取決于程式是如何執行的。
當程式需要多次通路某種大的資料結構,并且通路的順序是有規律的,硬體單元能夠捕捉到這種規律,進而能夠提前預取需要處理的資料,那麼就能提高程式的執行效率;當通路的順序沒有規律,或者硬體不能捕捉這種規律,這種預取不但會降低程式的性能,而且會占用更多的帶寬,浪費一級cache有限的空間;甚至在某些極端情況下,程式本身就占用了很多一級資料cache的空間,而預取單元為了預取它認為程式需要的資料,不适當地淘汰了程式本身存放在一級cache的資料,進而導緻程式的性能嚴重下降。
2.硬體預取所遵循的原則
在netburst架構的處理器中,硬體遵循以下原則來決定是否開啟自動預取。
1)隻有連續兩次cache不命中才能激活預取機制。并且,這兩次不命中的記憶體位址的位置偏差不能超過256或者512位元組(netburst架構的不同處理器定義的門檻值不一樣),否則也不會激活預取。這樣做的目的是因為預取也會有開銷,會占用内部總線的帶寬,當程式執行沒有規律時,盲目預取隻會帶來更多的開銷,并且并不一定能夠提高程式執行的效率。
2)一個4k位元組的頁(page)内,隻定義一條流(stream,可以是指令,也可以是資料)。因為處理器同時能夠追蹤的流是有限的。
3)能夠同時、獨立地追蹤8條流。每條流必須在一個4k位元組的頁内。
4)對4k位元組的邊界之外不進行預取。也就是說,預取隻會在一個實體頁(4k位元組)内發生。這和一級資料cache預取遵循相同的原則。
5)預取的資料存放在二級或者三級cache中。
6)對于uc(strong uncacheable)和wc(write combining)記憶體類型不進行預取。
2.5.3 兩個執行效率迥異的程式
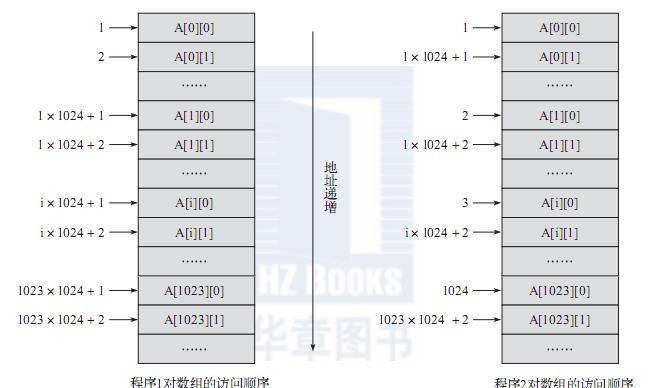
雖然絕大多數cache預取對程式員來說都是透明的,但是了解預取的基本原理還是很有必要的,這樣可以幫助我們編寫高效的程式。以下就是兩個相似的程式片段,但是執行效率卻相差極大。這兩個程式片段都定義了一個二維數組arr1024,對數組中每個元素都進行指派操作。在内循環内,程式1是依次對ai, ai, ai… ai進行指派;程式2是依次對a0, a1, a2 … a[1023] [i]進行指派。
通過圖2-8可以清晰地看到程式1和程式2的執行順序。程式1是按照數組在記憶體中的儲存方式順序通路,而程式2則是跳躍式通路。對于程式1,硬體預取單元能夠自動預取接下來需要通路的資料到cache,節省通路記憶體的時間,進而提高程式1的執行效率;對于程式2,硬體不能夠識别資料通路的規律,因而不會預取,進而使程式2總是需要在記憶體中讀取資料,降低了執行的效率。
2.5.4 軟體預取
從上面的介紹可以看出,硬體預取單元并不一定能夠提高程式執行的效率,有些時候可能會極大地降低執行的效率。是以,一些體系架構的處理器增加了一些指令,使得軟體開發者和編譯器能夠部分控制cache。能夠影響cache的指令很多,本書僅介紹預取相關的指令。
軟體預取指令
預取指令使軟體開發者在性能相關區域,把即将用到的資料從記憶體中加載到cache,這樣目前資料處理完畢後,即将用到的資料已經在cache中,大大減小了從記憶體直接讀取的開銷,也減少了處理器等待的時間,進而提高了性能。增加預取指令并不是讓軟體開發者需要時時考慮到cache的存在,讓軟體自己來管理cache,而是在某些熱點區域,或者性能相關區域能夠通過顯示地加載資料到cache,提高程式執行的效率。不過,不正确地使用預取指令,造成cache中負載過重或者無用資料的比例增加,反而還會造成程式性能下降,也有可能造成其他程式執行效率降低(比如某程式大量加載資料到三級cache,影響到其他程式)。是以,軟體開發者需要仔細衡量利弊,充分進行測試,才能夠正确地優化程式。需要指出的是,預取指令隻對資料有效,對指令預取是無效的。表2-1給出了預取的指令清單。

預取指令是彙編指令,對于很多軟體開發者來說,直接插入彙編指令不是很友善,一些程式庫也提供了相應的軟體版本。比如“mmintrin.h”提供了如下的函數原型:
void _mm_prefetch(char *p, int i);
p是需要預取的記憶體位址,i對應相應的預取指令,如表2-2所示。
接下來,我們将以dpdk中pmd(polling mode driver)驅動中的一個程式片段看看dpdk是如何利用預取指令的。
dpdk中的預取
在讨論之前,我們需要了解另外一個和性能相關的話題。dpdk一個處理器核每秒鐘大概能夠處理33m個封包,大概每30納秒需要處理一個封包,假設處理器的主頻是2.7ghz,那麼大概每80個處理器時鐘周期就需要處理一個封包。那麼,處理封包需要做一些什麼事情呢?以下是一個基本過程。
1)寫接收描述符到記憶體,填充資料緩沖區指針,網卡收到封包後就會根據這個位址把封包内容填充進去。
2)從記憶體中讀取接收描述符(當收到封包時,網卡會更新該結構)(記憶體讀),進而确認是否收到封包。
3)從接收描述符确認收到封包時,從記憶體中讀取控制結構體的指針(記憶體讀),再從記憶體中讀取控制結構體(記憶體讀),把從接收描述符讀取的資訊填充到該控制結構體。
4)更新接收隊列寄存器,表示軟體接收到了新的封包。
5)記憶體中讀取封包頭部(記憶體讀),決定轉發端口。
6)從控制結構體把封包資訊填入到發送隊列發送描述符,更新發送隊列寄存器。
7)從記憶體中讀取發送描述符(記憶體讀),檢查是否有包被硬體傳送出去。
8)如果有的話,從記憶體中讀取相應控制結構體(記憶體讀),釋放資料緩沖區。
可以看出,處理一個封包的過程,需要6次讀取記憶體(見上“記憶體讀”)。而之前我們讨論過,處理器從一級cache讀取資料需要3~5個時鐘周期,二級是十幾個時鐘周期,三級是幾十個時鐘周期,而記憶體則需要幾百個時鐘周期。從性能資料來說,每80個時鐘周期就要處理一個封包。
是以,dpdk必須保證所有需要讀取的資料都在cache中,否則一旦出現cache不命中,性能将會嚴重下降。為了保證這點,dpdk采用了多種技術來進行優化,預取隻是其中的一種。
而從上面的介紹可以看出,控制結構體和資料緩沖區的讀取都沒有遵循硬體預取的原則,是以dpdk必須用一些預取指令來提前加載相應資料。以下就是部分接收封包的代碼。