作者丨水管工張師傅@知乎
3D視覺工坊
記錄自己對劉蘭個川大神文章的了解。
1.離線地圖vs線上地圖:
離線地圖:
離線地圖的資料源可以是衛星圖像,也可以是由相機或雷射雷達等車載傳感器收集的資料。它可能來自同一輛車通過同一地點的多次通行,也可能來自衆多車輛的拼接。地圖的渲染(rending)是離線建構的,需要人工注釋者在地圖上注釋語義資訊并檢視最終結果。傳統的地圖服務是以這種離線方式工作的,然後注釋和策劃的地圖被提供給道路上的車輛。
線上地圖:
線上地圖是實時在車上或機器人上進行的。典型的例子SLAM(但是SLAM實時建圖過于稀疏?)。最近,語義SLAM(semantic SLAM)專注于道路上表面标記的幾何和語義,作為一種輕量級的建圖方法進行了探索。此外,單目相機實時建立語義地圖(monoSOM)是一個熱門話題,它使用神經網絡将來自多個攝像頭的單目圖像的時間序列融合到語義鳥瞰圖中。(在其他文章中寫)
2.SD Maps vs HD Maps
根據傳入資料分辨率的的不同,分為兩種地圖。
拓撲地圖(SD Maps),例如道路網絡,通常不包含車道級别的資訊。它們隻需要相對低分辨率的圖像,精度大約為米級(圖左)。
高清地圖(HD Maps),:側重于提取車道級别的資訊,例如車道線、路面箭頭和其他語義标記。這需要分辨率更高、精度達到厘米級的圖像。相應地,這兩種類型的地圖在本文的其餘部分将被松散地稱為SD地圖和HD地圖(圖右上)。
附:HD MAP 的文章:HDMapNet: An Online HD Map Construction and Evaluation Framework
是清華大學趙行老師的文章,非常強的一個組!
1.SD映射(Road Topology Discovery)
深度學習在地圖繪制上的早期應用側重于從相對低分辨率的航拍圖像中提取道路級拓撲。深度學習為 SD Map建立了一種經濟實惠的解決方案,覆寫範圍廣。SD Map中生成的道路拓撲的主要目的在自動駕駛環境中相對有限——用于路由和導航。然而,其中一些研究中提出的方法與後來的高清地圖工作高度相關,是以在這裡進行了回顧。
1.DeepRoadMapper (ICCV 2017)
接收從衛星獲得的航拍圖像并建立結構化的道路網絡。它首先執行語義分割,并在生成的道路圖上運作細化和修剪算法。由于語義分割的不準确(樹木、建築物等的遮擋),許多道路都處于斷開狀态。為了解決這個問題,DeepRoadMapper 使用 A* 搜尋算法生成連接配接假設以縮小差距。
2.RoadTracer (CVPR 2018)
注意到不可靠的語義分割結果,并将其作為中間表示消除。它使用疊代圖構造來直接獲得道路的拓撲結構。該算法需要做出決定,朝着某個方向邁出一定的距離,類似于強化學習環境中的問題。
3.PolyMapper(ICCV 2019)
靈感可能來自RoadTracer,它還消除了中間表示。它明确地統一了不同類型對象(包括道路和建築街區)的形狀表示,并将它們表示為閉合多邊形。該公式是非常聰明和幹淨的,遵循迷宮牆追随者算法。
PolyMapper 使用 Mask RCNN 架構來提取建築物和道路的邊界掩碼。基于掩碼,它提取頂點,找到起始頂點,并使用 RNN 對所有頂點進行自回歸疊代以形成閉合多邊形。

PolyMapper的網絡結構
RoadTracer 和 PolyMapper 中地圖結構化表示的自回歸生成與HD Map中使用的非常相似。
2.HD Mapping (Lane Level Information Extraction)
為什麼需要:
SD 地圖缺乏自動駕駛汽車安全定位和運動規劃所需的精細細節和準确性。高清地圖對于自動駕駛是必要的。高清地圖生成通常采用更高分辨率的鳥瞰 (BEV) 圖像,通過拼接車載攝像頭圖像和/或雷射雷達掃描生成。
1.HRAN (Hierarchical Recurrent Attention Networks for Structured Online Maps, CVPR 2018)
對道路進行稀疏點雲掃描,并輸出包含車道邊界執行個體的道路網絡的結構化表示。它首先疊代地找到每條車道線的起點,然後對于每條車道線,疊代地沿着這條線繪制下一個頂點。這兩個 RNN 以分層方式組織,是以命名為 HRAN——分層循環注意網絡。
Hierarchical recurrent attention networks
它提出了polyline loss(折線損失)的思想,以鼓勵神經網絡輸出結構化的折線。折線損失測量地面實況折線邊緣的偏差及其預測。這比頂點上的距離更合适,因為存在許多繪制等效折線的方法。
Polyline loss (又叫 Chamfer distance loss) 更注意形狀而不是頂點位置
HRAN 使用每像素 5 厘米的分辨率,并在 20 厘米精度内實作 0.91 次recall。主要故障模式來自錯過或額外的車道線。請注意,100% 的準确率不一定是最終目标,因為注釋者仍需要手動檢視這些圖像并修複它們。這些失敗案例可以相對容易地修複。在後來的工作 Deep Boundary Extractor 中使用的高度梯度圖可能能夠修複護欄被誤認為車道線的 FP 情況。
HRAN的分辨情況
2.Deep Structured Crosswalk(End-to-End Deep Structured Models for Drawing Crosswalks, ECCV 2018)
從雷射雷達點和相機圖像(雷射雷達 + RGB = 4 通道)生成的 BEV 圖像中提取結構化人行橫道。該網絡生成三個不同的特征圖——語義分割、輪廓檢測以及直接監督定義人行橫道方向的角度。
這項工作在某種意義上并不完全是端到端的,因為流程的最終目标是生成兩個結構化的、定向的人行橫道邊界。為了獲得結構化的邊界,三個中間特征圖以及一個粗略的地圖(OpenStreetMaps,它提供道路中心線和交叉路口多邊形)被輸入到能量最大化管道中,以找到人行橫道的最佳邊界和方向角。
Deep Structured Crosswalk 流程圖
注:上述結果是通過多次駕駛産生的輸入離線獲得的。該模型還可以通過同一位置單次線上運作,并可以實作類似的性能,但線上生成的圖像品質差的附加故障模式。
3.Deep Boundary Extractor(Convolutional Recurrent Network for Road Boundary Extraction, CVPR 2019)
使用折線提取道路邊界。它受到 Deep Structured Crosswalk 的啟發,并使用卷積 RNN(卷積 Snake,或 cSnake)以自回歸方式進行預測。輸入通過添加一個額外的雷射雷達高度梯度通道來擴充深度結構化人行橫道的輸入,該通道是通過采用 Sobel 過濾的雷射雷達 BEV 地圖的幅度生成的。cSnake 網絡疊代地處理旋轉的 ROI,并輸出對應于道路邊界的折線的頂點。它首先預測端點。基于每個端點,它以端點為中心裁剪和旋轉特征圖塊并定位下一個點。上述過程自回歸運作。
Deep Boundary Extractore的網絡結構
Deep Boundary Extractor 以 4 cm/pixel 的輸入分辨率運作,實作了 ~0.90 的逐點 F1 分數和 0.993 的拓撲精度。
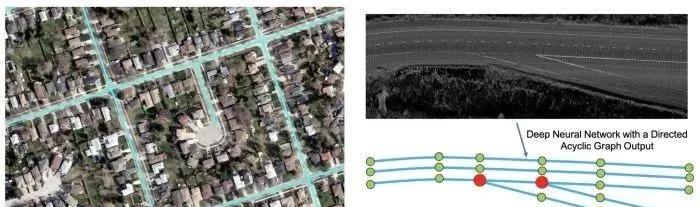
4.DAGMapper (Learning to Map by Discovering Lane Topology, ICCV 2019)
将HRAN的結構型車道線提取工作更進一步,并專注于像岔路口和彙集等更複雜的情況。它采用雷射雷達強度地圖并輸出DAG(定向非循環圖),而不是HRAN中的簡單折線。
在DAGMapper的核心中,也是一個recurrent的卷積頭,可疊代地參加圍繞最後一個預測點以圍繞最後一個預測點為中心的裁剪特征地圖更新檔,并預測下一個點的位置。變化的是它還可以預測要彙集,岔路或繼續的點的狀态。
DAGMapper 網路結構
總結:
1.離線地圖的深度學習要有人的參與。深度學習的結果需要結構化,以便于自動駕駛堆棧使用,并便于人類注釋者修改。(這句不太懂什麼意思)