作者丨水管工张师傅@知乎
3D视觉工坊
记录自己对刘兰个川大神文章的理解。
1.离线地图vs在线地图:
离线地图:
离线地图的数据源可以是卫星图像,也可以是由相机或激光雷达等车载传感器收集的数据。它可能来自同一辆车通过同一地点的多次通行,也可能来自众多车辆的拼接。地图的渲染(rending)是离线构建的,需要人工注释者在地图上注释语义信息并查看最终结果。传统的地图服务是以这种离线方式工作的,然后注释和策划的地图被提供给道路上的车辆。
在线地图:
在线地图是实时在车上或机器人上进行的。典型的例子SLAM(但是SLAM实时建图过于稀疏?)。最近,语义SLAM(semantic SLAM)专注于道路上表面标记的几何和语义,作为一种轻量级的建图方法进行了探索。此外,单目相机实时建立语义地图(monoSOM)是一个热门话题,它使用神经网络将来自多个摄像头的单目图像的时间序列融合到语义鸟瞰图中。(在其他文章中写)
2.SD Maps vs HD Maps
根据传入数据分辨率的的不同,分为两种地图。
拓扑地图(SD Maps),例如道路网络,通常不包含车道级别的信息。它们只需要相对低分辨率的图像,精度大约为米级(图左)。
高清地图(HD Maps),:侧重于提取车道级别的信息,例如车道线、路面箭头和其他语义标记。这需要分辨率更高、精度达到厘米级的图像。相应地,这两种类型的地图在本文的其余部分将被松散地称为SD地图和HD地图(图右上)。
附:HD MAP 的文章:HDMapNet: An Online HD Map Construction and Evaluation Framework
是清华大学赵行老师的文章,非常强的一个组!
1.SD映射(Road Topology Discovery)
深度学习在地图绘制上的早期应用侧重于从相对低分辨率的航拍图像中提取道路级拓扑。深度学习为 SD Map创建了一种经济实惠的解决方案,覆盖范围广。SD Map中生成的道路拓扑的主要目的在自动驾驶环境中相对有限——用于路由和导航。然而,其中一些研究中提出的方法与后来的高清地图工作高度相关,因此在这里进行了回顾。
1.DeepRoadMapper (ICCV 2017)
接收从卫星获得的航拍图像并创建结构化的道路网络。它首先执行语义分割,并在生成的道路图上运行细化和修剪算法。由于语义分割的不准确(树木、建筑物等的遮挡),许多道路都处于断开状态。为了解决这个问题,DeepRoadMapper 使用 A* 搜索算法生成连接假设以缩小差距。
2.RoadTracer (CVPR 2018)
注意到不可靠的语义分割结果,并将其作为中间表示消除。它使用迭代图构造来直接获得道路的拓扑结构。该算法需要做出决定,朝着某个方向迈出一定的距离,类似于强化学习环境中的问题。
3.PolyMapper(ICCV 2019)
灵感可能来自RoadTracer,它还消除了中间表示。它明确地统一了不同类型对象(包括道路和建筑街区)的形状表示,并将它们表示为闭合多边形。该公式是非常聪明和干净的,遵循迷宫墙追随者算法。
PolyMapper 使用 Mask RCNN 架构来提取建筑物和道路的边界掩码。基于掩码,它提取顶点,找到起始顶点,并使用 RNN 对所有顶点进行自回归迭代以形成闭合多边形。

PolyMapper的网络结构
RoadTracer 和 PolyMapper 中地图结构化表示的自回归生成与HD Map中使用的非常相似。
2.HD Mapping (Lane Level Information Extraction)
为什么需要:
SD 地图缺乏自动驾驶汽车安全定位和运动规划所需的精细细节和准确性。高清地图对于自动驾驶是必要的。高清地图生成通常采用更高分辨率的鸟瞰 (BEV) 图像,通过拼接车载摄像头图像和/或激光雷达扫描生成。
1.HRAN (Hierarchical Recurrent Attention Networks for Structured Online Maps, CVPR 2018)
对道路进行稀疏点云扫描,并输出包含车道边界实例的道路网络的结构化表示。它首先迭代地找到每条车道线的起点,然后对于每条车道线,迭代地沿着这条线绘制下一个顶点。这两个 RNN 以分层方式组织,因此命名为 HRAN——分层循环注意网络。
Hierarchical recurrent attention networks
它提出了polyline loss(折线损失)的思想,以鼓励神经网络输出结构化的折线。折线损失测量地面实况折线边缘的偏差及其预测。这比顶点上的距离更合适,因为存在许多绘制等效折线的方法。
Polyline loss (又叫 Chamfer distance loss) 更注意形状而不是顶点位置
HRAN 使用每像素 5 厘米的分辨率,并在 20 厘米精度内实现 0.91 次recall。主要故障模式来自错过或额外的车道线。请注意,100% 的准确率不一定是最终目标,因为注释者仍需要手动查看这些图像并修复它们。这些失败案例可以相对容易地修复。在后来的工作 Deep Boundary Extractor 中使用的高度梯度图可能能够修复护栏被误认为车道线的 FP 情况。
HRAN的分辨情况
2.Deep Structured Crosswalk(End-to-End Deep Structured Models for Drawing Crosswalks, ECCV 2018)
从激光雷达点和相机图像(激光雷达 + RGB = 4 通道)生成的 BEV 图像中提取结构化人行横道。该网络生成三个不同的特征图——语义分割、轮廓检测以及直接监督定义人行横道方向的角度。
这项工作在某种意义上并不完全是端到端的,因为流程的最终目标是生成两个结构化的、定向的人行横道边界。为了获得结构化的边界,三个中间特征图以及一个粗略的地图(OpenStreetMaps,它提供道路中心线和交叉路口多边形)被输入到能量最大化管道中,以找到人行横道的最佳边界和方向角。
Deep Structured Crosswalk 流程图
注:上述结果是通过多次驾驶产生的输入离线获得的。该模型还可以通过同一位置单次在线运行,并可以实现类似的性能,但在线生成的图像质量差的附加故障模式。
3.Deep Boundary Extractor(Convolutional Recurrent Network for Road Boundary Extraction, CVPR 2019)
使用折线提取道路边界。它受到 Deep Structured Crosswalk 的启发,并使用卷积 RNN(卷积 Snake,或 cSnake)以自回归方式进行预测。输入通过添加一个额外的激光雷达高度梯度通道来扩展深度结构化人行横道的输入,该通道是通过采用 Sobel 过滤的激光雷达 BEV 地图的幅度生成的。cSnake 网络迭代地处理旋转的 ROI,并输出对应于道路边界的折线的顶点。它首先预测端点。基于每个端点,它以端点为中心裁剪和旋转特征图块并定位下一个点。上述过程自回归运行。
Deep Boundary Extractore的网络结构
Deep Boundary Extractor 以 4 cm/pixel 的输入分辨率运行,实现了 ~0.90 的逐点 F1 分数和 0.993 的拓扑精度。
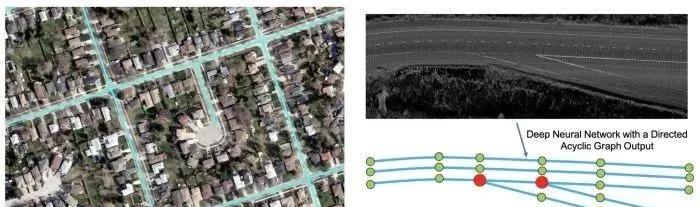
4.DAGMapper (Learning to Map by Discovering Lane Topology, ICCV 2019)
将HRAN的结构型车道线提取工作更进一步,并专注于像岔路口和汇集等更复杂的情况。它采用激光雷达强度地图并输出DAG(定向非循环图),而不是HRAN中的简单折线。
在DAGMapper的核心中,也是一个recurrent的卷积头,可迭代地参加围绕最后一个预测点以围绕最后一个预测点为中心的裁剪特征地图补丁,并预测下一个点的位置。变化的是它还可以预测要汇集,岔路或继续的点的状态。
DAGMapper 网路结构
总结:
1.离线地图的深度学习要有人的参与。深度学习的结果需要结构化,以便于自动驾驶堆栈使用,并便于人类注释者修改。(这句不太懂什么意思)