Pseduo-Label
- 僞标簽的介紹
- 論文介紹
-
- 核心思想
- 相關流程
- 相關函數
-
- Denoising Auto-Encoder
- 模型整體的目标函數
- 僞标簽有效的原因
-
- 類間的低密度分離
- 熵正則化
- 實驗結果
- 讀後感
-
- 思考
- 存在不足
論文位址:Pseduo-Label
從DAFomer溯源到的論文
僞标簽的介紹
僞标簽的介紹可以參考:僞标簽(Pseudo-Labelling)——鋒利的匕首,詳細介紹了什麼是僞标簽方法以及僞标簽方法的分類,本論文用到的方法就是上文中的 創新版僞标簽的方法(将沒有标簽的資料的損失函數也加入進來,就是最後公式後邊那一坨,具體如下圖)
論文介紹
核心思想
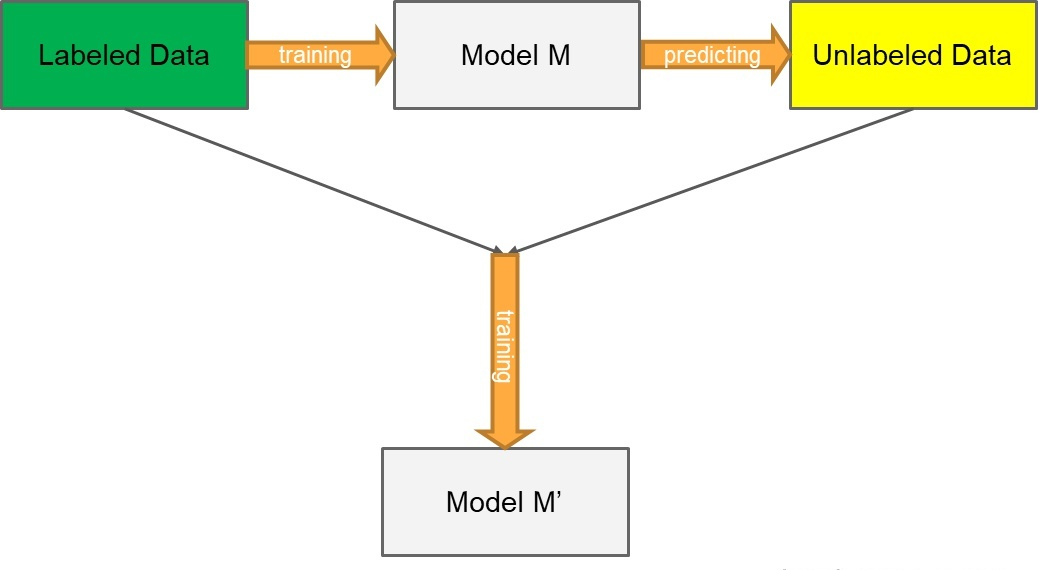
Pseudo-Label 模型作為一個簡單、有效的半監督學習方法早在 2013年就被提出,其核心思想包括兩步:
- 第一步:運用訓練出的模型給予無标簽的資料一個僞标簽。方法很直接:用訓練中的模型對無标簽資料進行預測,以機率最高的類别作為無标簽資料的僞标簽
- 第二步:運用 entropy regularization(熵正則化化) 思想,将無監督資料轉為目标函數的正則項(如下文公式)。實際中,就是将擁有僞标簽的無标簽資料視為有标簽的資料,然後用交叉熵來評估誤差大小
相關流程
使用有标簽資料和無标簽資料同時以有監督的方式訓練預訓練網絡。對于無标簽的資料,在每次權值更新時重新計算的僞标簽,被用于與監督學習任務相同的損失函數計算(即每次權值更新時,都重新計算僞标簽,并将該僞标簽當作真是标簽用于計算損失函數)。
相關函數
Denoising Auto-Encoder
去噪自動編碼器是一種無監督學習算法,基于使學習的表示對輸入模式的部分破壞具有魯棒性的思想。該方法可以用于訓練自動編碼器,這些微分代數方程組(DAE)可以堆疊起來初始化深度神經網絡:
h i = s ( ∑ j = 1 d v W i j x ~ j + b i ) h_i=s(\sum_{j=1}^{d_v}W_{ij}\tilde x_j+b_i) hi=s(∑j=1dvWijx~j+bi)
x ^ j = s ( ∑ i = 1 d h W i j h i + a j ) \widehat x_j=s(\sum_{i=1}^{d_h} W_{ij}h_i+a_j) x ⎨ ⎧1,0,if i=argmaxi′fi′(x)otherwise
L公式左邊是評估有标簽資料的誤差交叉熵,右邊是評估僞标簽資料的誤差交叉熵
L = 1 n ∑ m = 1 n ∑ i = 1 C L ( y i m , f i m ) + α ( t ) 1 n ′ ∑ m = 1 n ′ ∑ i = 1 C L ( y i ′ m , f i ′ m ) L=\frac{1}{n}\sum_{m=1}^n\sum_{i=1}^C L(y_i^m,f_i^m)+\alpha (t)\frac{1}{n'}\sum_{m=1}^{n'}\sum_{i=1}^C L(y_i'^m, f_i'^m) L=n1∑m=1n∑i=1CL(yim,fim)+α(t)n′1∑m=1n′∑i=1CL(yi′m,fi′m)
● n n n 是SGD中有标簽資料的mini-batch大小
● n ′ n' n′ 是SGD中無标簽資料的mini-batch大小
● f i m f_i^m fim 是有标簽資料中 m 個樣本的輸出集合
● y i m y_i^m yim 是有标簽資料中 m 個樣本的真實标簽
● f i ′ m f_i'^m fi′m 是無标簽資料中 m 個樣本的輸出集合
● y i ′ m y_i '^m yi′m 是無标簽資料中 m 個樣本的僞标簽
● α ( t ) \alpha(t) α(t) 是平衡它們的系數
為了平衡有标簽和無标簽之間的損失引入了 α ( t ) \alpha(t) α(t)
α ( t ) \alpha(t) α(t) 的合理排程對網絡性能至關重要:
● 如果 α ( t ) \alpha(t) α(t) 太大,甚至對有标記資料的訓練也會産生幹擾
● 如果 α ( t ) \alpha(t) α(t) 太小,則無法獲得來自未标簽資料的好處
此外,期望通過緩慢增加 α ( t ) \alpha(t) α(t) 的确定性退火過程,來幫助優化過程,以避免較差的局部極小值,進而使無标簽資料的僞标簽盡可能類似于真實标簽。
α ( t ) = { 0 , t < T 1 t − T 1 T 2 − T 1 α f , T 1 ≤ t < T 2 α f , T 2 ≤ t \alpha(t)= \begin{cases} 0, & \text{$t<T_1$} \\ \frac{t-T_1}{T_2-T_1}\alpha_f, & \text{$T_1\leq t < T_2$} \\ \alpha_f, & \text{$T_2 \leq t$} \end{cases} α(t)=⎩ ⎨ ⎧0,T2−T1t−T1αf,αf,t<T1T1≤t<T2T2≤t
● α f = 3 , T 1 = 100 , T 2 = 600 \alpha_f =3, \quad T_1=100, \quad T_2=600 αf=3,T1=100,T2=600
僞标簽有效的原因
類間的低密度分離

這個世界是非黑即白的,什麼是非黑即白?
假設現在有一大堆的data,有标注資料,有非标注資料,在兩個類别之間會有一個明顯的鴻溝。給一些标注資料,可以把邊界分在上圖右邊的線,也可以把邊界分在上圖左邊的線。但是考慮非标注資料,那麼左邊的邊界會好一點,在邊界處,兩個類别的密度是低的(不會出現data)。
熵正則化
熵正則化是在最大後驗估計架構中受益于無标簽資料的一種手段。該方案通過最小化無标簽資料的類别機率的條件熵,支援類間的低密度分離,而無需對密度進行任何模組化。
H ( y ∣ x ′ ) = − 1 n ′ ∑ m = 1 n ′ ∑ i = 1 C P ( y i m = 1 ∣ x ′ m ) l o g P ( y i m = 1 ∣ x ′ m ) H(y|x')=-\frac{1}{n'}\sum_{m=1}^{n'}\sum_{i=1}^{C}P(y_i^m=1|x'^m)logP(y_i^m=1|x'^m) H(y∣x′)=−n′1∑m=1n′∑i=1CP(yim=1∣x′m)logP(yim=1∣x′m)
● n ′ n' n′ 是無标簽資料的數目
● C C C 是類别數目
● y i m y_i^m yim是第 m 個無标簽樣本的未知标簽
● x ′ m x'^m x′m 是第 m 個無标簽樣本的輸入向量
這個熵用于度量類間的重疊。随着類間重疊的減少,決策邊界上的資料點密度降低。
MAP估計被定義為後驗分布的最大化:
C ( θ , λ ) = ∑ m = 1 n l o g P ( y m ∣ x m ; θ ) − λ H ( y ∣ x ′ ; θ ) C(\theta ,\lambda)=\sum_{m=1}^nlogP(y^m|x^m;\theta)-\lambda H(y|x';\theta) C(θ,λ)=∑m=1nlogP(ym∣xm;θ)−λH(y∣x′;θ)
● n 是有标簽資料的數目
● x m x^m xm 是第 m 個有标簽樣本
● λ \lambda λ 是平衡兩項的系數
通過最大化有标簽資料的條件對數似然(第一項),并最小化無标簽資料的熵(第二項),我們可以利用無标簽資料獲得更好的泛化性能。
就如上文相關流程中所說: pseudo label多是先用标注資料訓練模型,然後在未标注樣本上預測,篩選高置信的未标注樣本再訓練新模型,訓練多輪直到模型效果不再提升,而這篇文章的實作其實是把未标注樣本作為正則項的一部分。因為預測label和預測機率是相同模型給出的,是以最小化預測label的交叉熵,也就是最大化預測為1的class對應的機率值,和MinEnt直接最小化未标注樣本交叉熵的操作一樣。(在思考子產品詳細講解個人想法)
實驗結果
在實驗中,研究人員用 MNIST 資料集進行了實驗驗證,并嘗試了在有标簽資料僅為100、600、1000和3000時的結果入下圖所示:
DROPNN、PL 和 PL+DAE 分别是實驗中的 baseline 模型、baseline 模型+Pseudo-Label 方法 以及 baseline 模型+Pseudo-Label 方法+ DAE 預訓練方案。
這裡我們主要關注Pseudo-Label 方法的效果,其結果如表中倒數第二行所示。從表中可以看出,當有标簽資料僅為 600 條時,Pseudo-Label 方法相對于其他公開模型,可以達到最佳的效果。但在其他實驗條件下,隻能實作相對較好的表現。不過相對于 baseline,此方法在所有情況下均能實作一定的提升。有标簽資料量越少,這一提升越明顯。這說明 Pseudo-Label 方法确實可以在一定程度上從無标簽資料中提取有效信号。
進一步,研究人員通過降維可視化的方式展示了 Pseudo-Label 模型使用前後的效果,實驗資料包含 600 有标簽資料 + 60000 無标簽資料:
對比上面左右兩張圖可以看出來, Pseudo-Label 模型相對于單獨的有監督模型,可以有效改善各類别資料在空間中的聚集密度。
讀後感
思考
熵正則化的目的是為了讓相同類别的分布更加集中,減少class overlap;而降低預測值和僞标簽的交叉熵,也就是最大化預測為1(或者一個類的機率非常接近1,可以近似等于1?)的class對應的機率值,也就是讓最有可能的預測結果最大,這樣的話資訊熵自然就很小。
存在不足
Pseudo-Label 方法隻在訓練時間這個次元上,采用了退火思想,即采用時變系數α(t)。而在僞标簽這個次元,對于模型給予的預測标簽一視同仁,這種方法在實際中存在明顯問題。很顯然,如果模型對于一個樣本所預測的幾個類别都具有相似的低機率值,如共有十個類别,每個類别的預測機率值都接近 0.1,那麼再以最大機率值對應的類别作為僞标簽,是不合适的,将會引入很大的錯誤信号。(概括一下也就是:Pseudo-Label 方法,以最大機率值對應的類别作為僞标簽這個操作是不太合适的(考慮到每個類别的預測機率值都接近 0.1,每個類别的預測結果都很差))
本文内容參考如下:
僞标簽(Pseudo-Labelling)——鋒利的匕首
我們真的需要那麼多标注資料嗎?半監督學習技術近年來的發展曆程及典型算法架構的演進
[論文筆記]Pseudo-Label:The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
Pseudo-Label 代碼