文章目錄
-
- 一、《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
-
- 1.原文位址
- 2.TensorFlow官方
- 3.論文亮點
- 4.代碼學習
- 二、《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
-
- 1.原文位址
- 2.非官方Pytorch代碼
- 3.論文亮點
- 4.代碼學習
- 三、《HybridSN: Exploring 3-D–2-DCNN Feature Hierarchy for Hyperspectral Image Classification》
-
- 1.原文位址
- 2.代碼
- 3.論文解讀
- 3.代碼學習
- 4.問題思考
- 5.注意力機制在CV的簡單總結
- 四、《Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising》
-
- 1.原文位址
- 2.代碼
- 3.論文解讀
- 五、《Squeeze-and-Excitation Networks》
-
- 1.原文位址
- 2.代碼
- 3.論文解讀
- 六、《Deep Supervised Cross-modal Retrieval》
-
- 1.原文位址
- 2.非官方代碼
- 3.論文解讀
一、《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
1.原文位址
2.TensorFlow官方
3.論文亮點
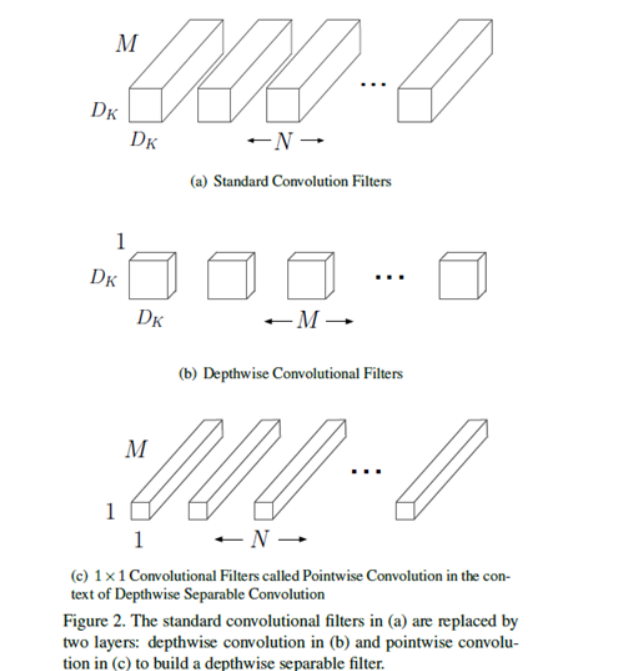
1.MobileNet模型基于深度可分解卷積(depthwise separable convolutions),它由分解後的卷積組成,分解後的卷積就是将标準卷積分解成一個深度卷積(depthwise convolution)和一個1x1的點卷積(pointwise convolution)。深度卷積将每個卷積核應用于輸入的每一個通道;然後,深度卷積的輸出作為點卷積的輸入,點卷積用1x1卷積來組合這些輸入。大大減少了運算量和參數數量。結構如下圖所示:

2.引入控制模型大小的超參數:
- 寬度因子α (Width multiplier ),用于控制輸入和輸出的通道數。對于深度可分離卷積,其計算量為: D k × D k × α M × D F × D F + 1 × 1 × α M × α N × D F × D F D_k×D_k×αM×D_F×D_F+1×1×αM×αN×D_F×D_F Dk×Dk×αM×DF×DF+1×1×αM×αN×DF×DF
- 分辨率因子ρ (resolution multiplier ),用于控制輸入和内部層表示。即用分辨率因子控制輸入的分辨率。對于深度可分離卷積,其計算量為: D k × D k × α M × ρ D F × ρ D F + 1 × 1 × α M × α N × ρ D F × ρ D F D_k×D_k×αM×ρD_F×ρD_F+1×1×αM×αN×ρD_F×ρD_F Dk×Dk×αM×ρDF×ρDF+1×1×αM×αN×ρDF×ρDF
注:α,ρ是人為手動設定的,在給出的測試代碼中,α,ρ均設定為1。
4.代碼學習
注:如果真實複現MobileNetV1網絡結構,需将代碼中的
cfg = [(64, 1), (128, 2), (128, 1), (256, 2), (256, 1), (512, 2), (512, 1),
(1024, 2), (1024, 1)]
修改成
cfg = [(64, 1), (128, 2), (128, 1), (256, 2), (256, 1), (512, 2), (512, 1),
(512, 1),(512, 1),(512, 1),(512, 1),(1024, 2), (1024, 1)]
參考文章:
論文筆記:MobileNet v1
【深度學習】經典分類網絡 亮點及結構
MobileNet網絡詳解
MobileNets: Efficient CNN for Mobile Vision Applications[1704.04861]
二、《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
1.原文位址
2.非官方Pytorch代碼
3.論文亮點
- Inverted Residuals(倒殘差結構),先升維再降維,增強梯度的傳播,顯著減少推理期間所需的記憶體占用。
- 網絡為全卷積的,使得模型可以适應不同尺寸的圖像;使用 RELU6(最高輸出為 6)激活函數,使得模型在低精度計算下具有更強的魯棒性
- Linear Bottlenecks,去掉 Narrow layer(low dimension or depth) 後的 ReLU,保留特征多樣性,增強網絡的表達能力。
注:針對于論文中給出的shortcut連接配接表述是有誤的,隻有當stride=1且輸入特征矩陣與輸出特征矩陣的shape相同時,滿足這兩個條件的時候,才會有shortcut連接配接,其他情況均沒有。
4.代碼學習
2個epoch結果
10個epoch結果
注:
代碼細節部分:
cfg = [(1, 16, 1, 1),
#根據MobileNetV2網絡結構,應将老師給出的代碼中,(6, 24, 2, 1)應改成(6, 24, 2, 2)
(6, 24, 2, 2),
(6, 32, 3, 2),
(6, 64, 4, 2),
(6, 96, 3, 1),
(6, 160, 3, 2),
(6, 320, 1, 1)]
應該使用nn.ReLU6代替F.relu激活函數
參考文章:
MobileNetV1 & MobileNetV2 簡介
輕量級網絡–MobileNetV2論文解讀
論文閱記 MobileNetV2:Inverted Residuals and Linear Bottlenecks
MobileNet網絡詳解
關于shortcut的一點思考
三、《HybridSN: Exploring 3-D–2-DCNN Feature Hierarchy for Hyperspectral Image Classification》
1.原文位址
2.代碼
3.論文解讀
1.高光譜圖像(HyperSpectral Image,簡稱HSI)是三維立體資料,包含兩個空間次元和一個光譜次元。
作者提出HybirdSN模型:将空間光譜和光譜的互補資訊分别以3D-CNN和2D-CNN層組合到了一起,進而充分利用了光譜和空間特征圖,結合二維和三維卷積的優勢,設計的網絡結構中先使用三維卷積,再堆疊二維卷積,最後連接配接分類器。既發揮了三維卷積的優勢,充分提取光譜-空間特征,也避免了完全使用三維卷積而導緻的模型複雜。
2.網絡結構
網絡首先進行的PCA降維操作,然後由3層三維卷積(3D Conv)→ 1層二維卷積(2D Conv)→ 2層全連接配接層(Fc) → 1層softmax分類層組成。
3.代碼學習
根據給出的網絡結構,搭建網絡。參考網上代碼,Batch Norm适合用于分類任務,是以在搭建網絡的時候,添加Batch Norm可以使訓練更容易、加速收斂、防止模型過拟合。
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
self.conv3d_1 = nn.Sequential(
nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(8),
nn.ReLU(inplace = True),
)
self.conv3d_2 = nn.Sequential(
nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(16),
nn.ReLU(inplace = True),
)
self.conv3d_3 = nn.Sequential(
nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU(inplace = True)
)
self.conv2d_4 = nn.Sequential(
nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0),
nn.BatchNorm2d(64),
nn.ReLU(inplace = True),
)
self.fc1 = nn.Linear(18496,256)
self.fc2 = nn.Linear(256,128)
self.fc3 = nn.Linear(128,16)
self.dropout = nn.Dropout(p = 0.4)
def forward(self,x):
out = self.conv3d_1(x)
out = self.conv3d_2(out)
out = self.conv3d_3(out)
out = self.conv2d_4(out.reshape(out.shape[0],-1,19,19))
out = out.reshape(out.shape[0],-1)
out = F.relu(self.dropout(self.fc1(out)))
out = F.relu(self.dropout(self.fc2(out)))
out = self.fc3(out)
return out
測試結果:
4.問題思考
1.2D卷積和3D卷積的差別?
- 二維卷積(2D-CNN):可以提取高光譜圖像的空間特征(spatial feauture);特點是相對三維卷積,模型比較簡單,但不能提取高光譜圖像的光譜特征;
- 三維卷積(3D-CNN):可以同時提取高光譜圖像的光譜特征(spectral feature)和空間特征;同時提取三個次元的資料的特征,能同時進行空間和空間特征表示,但資料計算量要比二維卷積大不少;但捕獲光譜特征之後可以提升分類準确率;
2、每次分類的結果為什麼都不一樣?
(1)首先,權重初始化都是随機的,經過梯度下降以後最後的權值肯定也不是相同的。
(2)其次,就是在網絡中,為了防止過拟合,采用了Dropout,随機dropout掉不同的隐藏神經元來進行網絡訓練,是以最終的分類結果也不一樣。可以通過model.train(),model.eval()來解決和這個問題。
3、如果想要進一步提升高光譜圖像的分類性能,可以如何改進?
添加注意力機制,自從Transformer提出之後,自注意力機制也随即在CV領域大放異彩。Attention是從大量資訊中有篩選出少量重要資訊,并聚焦到這些重要資訊上,忽略大多不重要的資訊。權重越大越聚焦于其對應的Value值上,即權重代表了資訊的重要性,而Value是其對應的資訊。
# 通道注意力機制
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
# 空間注意力機制
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
測試結果,相比較未添加注意力機制的代碼,準确率竟然從0.9822下降到0.9771:
5.注意力機制在CV的簡單總結
參考文章:
[HSI論文閱讀] | HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification
《HybridSN: Exploring 3-D–2-DCNN Feature Hierarchy for Hyperspectral Image Classification》論文閱讀
【AI】高光譜圖像分類 — HybridSN模型
高光譜圖像分類 HybridSN
四、《Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising》
1.原文位址
2.代碼
3.論文解讀
- 強調了residual learning(殘差學習)和batch normalization(批量标準化)在圖像複原中相輔相成的作用,可以在較深的網絡的條件下,依然能帶來快的收斂和好的性能。
- 文章提出DnCNN,在高斯去噪問題下,用單模型應對不同程度的高斯噪音;甚至可以用單模型應對高斯去噪、超分辨率、JPEG去鎖三個領域的問題。
參考文章:
【論文略讀40】DnCNNs——經典去噪方法
【圖像去噪】DnCNN論文詳解(Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising)
五、《Squeeze-and-Excitation Networks》
1.原文位址
2.代碼
3.論文解讀
SENet的核心思想在于模組化通道之間的互相依賴關系,通過網絡的全局損失函數自适應的重新矯正通道之間的特征相應強度。
1)擠壓(squeeze)部分,對卷積後的特征圖做全局平均池化,這一步相當于得到所有特征通道的數值分布;
2)激勵(excitation)部分,對各個特征通道進行互動,捕獲通道間的依賴關系,為每個特征通道生成權重;
3)scale(attention)部分,将生成的權重乘回到原輸入特征圖中。
通道域的注意力機制一般需要對輸入的特征圖C×H×W進行全局池化得到一個一維向量1×1×C,然後對這個一維向量進行特征互動,計算相關性,最後将互動之後的特征向量進行歸一化得到通道權重向量,将通道權重向量施加到原特征圖中
參考文章:
深度學習論文翻譯解析(十六):Squeeze-and-Excitation Networks
Squeeze-and-Excitation Networks
六、《Deep Supervised Cross-modal Retrieval》
1.原文位址
2.非官方代碼
3.論文解讀
本文旨在找到一個通用的表示空間,在其中可以直接比較來自不同模态的樣本。
Contribution:
- 提出了一個監督的跨模态學習結構作為不同模态的橋梁。它可以通過保留語義的區分性和模态的不變性有效學習到公共的表達。
- 在最後一層開發了兩個具有權重共享限制的子網,以學習圖像和文本模态之間的交叉模态相關性。此外,模态不變性損失被直接計算到目标函數中,以消除跨模态差異。
- 應用線性分類器對公共表示空間中的樣本進行分類。 這樣,DSCM-R最大限度地減少了标簽空間和公共表示空間中的辨識損失,進而使學習到的公共表示具有顯着性。
網絡結構:
-
圖像:利用預訓練在 ImageNet 的網絡提取出圖像的 4096
維的特征作為原始的圖像進階語義表達。然後後續是幾個全連接配接層,來得到圖像在公共空間中的表達。
- 文本:利用預訓練在 Google News 上的 Word2Vec 模型,來得到 k維的特征向量。一個句子可以表示為一個矩陣,然後使用一個 Text CNN來得到原始的句子進階語義表達。之後也是同樣的形式,後面是幾個全連接配接層來得到句子在公共空間中的表達。
- 為了確定兩個子網絡能夠為圖像和文本學到公共的表達,我們使這兩個子網絡的最後幾層共享權重。直覺上這樣可以使得同一類的圖檔和文本生成盡可能相似的表達。
- 最後面是一層全連接配接層來進行分類。
目标函數:
1.分類的損失,其中 Y Y Y 是 l a b e l label label 的 o n e − h o t one-hot one−hot表示,計算一下分類結果與 Y Y Y 的差别。
2.損失函數包括三項,分别代表模态間的,圖像模态的和文本模态的負對數似然。最小化負對數似然相當于最大化機率,這裡的機率指的是兩個特征屬于同一個類别的機率。
3.為了消除跨模态差異,我們建議最小化所有圖像-文本對的表示之間的距離,兩種模态公共空間中的距離度量
參考文章:
論文閱讀:深度監督跨模态檢索 Deep Supervised Cross-modal Retrieval, CVPR 2019
CVPR2019跨模态檢索-Deep Supervised Cross-modal Retrieval
深度監督跨模态檢索(DSCMR)