作者:林偉
最新的十年是人工智能爆炸的十年,人工智能已經在社會各個領域如圖檔,語音,語言了解,推薦算法取得重大突破,使得其判斷的結果已經接近或者超越了人類。這個背後的主要原因是是網際網路的不斷發展使我們能夠快速地積累了海量資料,再加上硬體的快速發展以及神經網絡訓練方式的革新,使我們越來越有能力訓練深且寬的神經網絡,産出了超越人類“智能”的模型,并得到廣泛應用。是以如何實作大規模并行分布式深度學習就成為深度學習的研究熱點,進而成為推動算法創新的關鍵的人工智能工程能力。
并行分布式深度學習的曆史發展曆程和範式
最開始推動分布式訓練的場景是大規模搜尋廣告推薦模型。随着網際網路的發展,我們需要建立一個能夠滿足網際網路使用者以及資料規模一種搜尋廣告推薦模型,需要通過訓練能夠很好對使用者,網頁進行有效的向量化,進而能夠通過不同人或者網頁的特征,找出更加相關的資訊,提高人們在海量資料中比對資料的效率。而這類模型往往需要學習出來一個非常大的特征矩陣,比如現代系統這種特征規模以及從最開始百億[1]已經發展到千億乃至于萬億[2],這就需要一種分布式的系統來支撐這種機器學習的模型訓練。而且因為這種特征矩陣因為人群和網頁這種網際網路的特性,具有明顯的熱點效應,是非常稀疏的,使得其在通路時候常常具有在時間和空間上的不均勻性。這也是2014年谷歌等團隊在 OSDI 發表一個分布式系統《Scaling Distributed Machine Learning with the Parameter Server》[3](相關其他研究還有[4][5]),該系統(Figure 1)建立一個分布式Key-Value的存儲系統來儲存海量的特征向量,然後我們把海量訓練資料分發到多個沒有狀态的訓練工作節點( worker ),每個工作節點從分布式KV的參數伺服器取得最新的參數,在目前這批資料進行訓練算出在這批資料上做出的估計和希望的答案(一般是把使用者最後真實點選的網頁或者商品作為目标答案)的差距,進而計算出需要對于參數調整的梯度,然後在把這些梯度推送會參數伺服器進行相關權重平均,彙總後再調整參數,使得整個模型的預測能夠更加貼近目标值。因為稀疏的特性,為了能夠充分發揮系統的性能,也因為這類模型往往追求的目标是一個動态的目标,因為人的興趣和網頁本身都是時刻在變化的。是以我們可以利用這個特性進行異步訓練,也就是在訓練時候可以适當使用過期的參數以及利用異步的方式來更新參數,進而能夠更好的,在更大範圍來容忍參數伺服器參數通路的不均勻性以及分布式場景下容錯以及網絡通訊的壓力,使得分布式訓練效率更優。更加具體的可以參照NIPS 2013年的《More effective distributed ml via a stale synchronous parallel parameter server》等論文[5]。
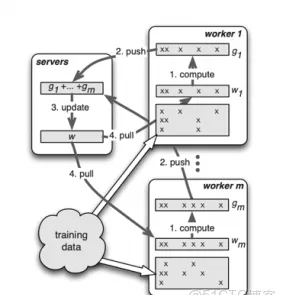
圖1參數伺服器(選自[3])
于此同時,在圖檔,語音和語言等感覺類領域,随着海量資料的積累以及算力發展,神經網絡算法終于可以取得突破性的結果,随着 AlexNet[6], GoogleNet[7],Resnet[8],模型的規模和深度也是越來越大,進而機器學習領域從神級網絡算法誕生出一支獨立學派:深度學習,并得到了快速爆炸性的發展,以至于如今人們談論人工智能往往和深度學習畫上了等号。但是因為GPU等硬體也是快速發展,顯存大小也是同步在變大,使得這類模型還是能夠在單塊顯示卡能夠放的下,加上我們可以通過 ZeRO optimizer[25],CPU-offload 等技術進一步提高 GPU 顯存的使用效率,以至有文章[26]說實用的模型總是能夠在單卡能夠放下并且得到訓練。但是即便如此,模型的參數還是有上億的規模,需要海量的資料來訓練,為了加速訓練,我們還是需要使用資料并行來分布式訓練,因為感覺類模型往往是稠密的參數,訓練每批資料後,幾乎是所有的參數都需要更新,這樣使得在通訊行為上有着非常顯著不同于稀疏模型的特點,于是我們有了另外一種并行分布式方式:AllReduce[27]的同步的資料并行。這種分布式訓練模式其實從高性能叢集 HPC 領域來,也就是每個訓練參與方都維護一個模型的副本,然後在訓練時候,每個工作節點分到 N 分之一的資料,通過前向和反向計算,得到這個資料下模型估計值和目标指的差距,進而得到這批資料上參數需要變換的梯度,然後利用高性能 HPC 叢集的通訊庫原語 AllReduce 使得每個節點同時權重平均所有節點局部梯度變化,使得每個工作節點都得到全局梯度變化的副本,最後同時将該梯度變化運用于模型參數上,使得其每個工作節點上的模型副本同步得到相同的更新。AllReduce 的有可以細分為 Ring-AllReduce[26]和 Reduce-Scatter 的方式來做,其中 Ring-Allreduce 因為去中心化以及非常确定性的消息傳遞,使得Nvidia可以根據這個特性建構多個 GPU 卡的實體拓撲NVLink[9],進而能夠高效進行 Ring 的 Allreduce,并且将這個通訊原語內建到自己軟體 NCCL 庫[10],進而大大推動同步的資料并行模型訓練的開展和人工智能應用的發展。當然也有其他研究比如位元組跳動的 BytePS[11] 利用參數伺服器的分布式架構來進行稠密模型的AllReduce 這個計算,以便在沒有良好 NVLink 拓撲上一樣能夠進行高效的同步的資料并行訓練。
随着深度學習演進,在搜尋推薦廣告領域也從原來邏輯回歸等傳統機器學習算法向深度學習演進,最有影響力以及開創深度學習模型在這個領域的模型訓練的是谷歌 2016 年發表于 DLRS 的《Wide & Deep Learning for Recommender System》[12]。為了能夠有效支援感覺類以及推薦類模型兩者的需要,谷歌團隊推出 TensorFlow 深度學習架構[13],進而能夠把多種并行分布式訓練範式都能夠統一在 Tensor 流圖的深度學習計算引擎上。
雖然 TensorFlow 從一開始就對于整個分布式深度學習訓練做了非常基礎和本質的抽象,該抽象可以支援任意的大規模的分布式訓練方式,并且在這個架構基礎上很快在 2018 年就出現了流水并行[14]和算子拆分[15]的模型并行的方式。流水并行是将模型層和層之間橫向分成多個階段,進而可以将模型的不同部分配置設定到不同的節點(GPU)中,進而我們可以訓練單個 GPU 存儲放不下的大模型。這種模式下不同 GPU 之間傳遞是層和層之間的計算結果,但是我們知道整個神經網絡的訓練過程是前向和反向的計算過程,是以這些 GPU 因為計算依賴是依次進行計算的(圖 2 中的 b 所示),并不能在計算進行很好并行,無法充分利用 GPU 的算力。是以 Gpipe[14]進一步把計算進行 mini-batch的切割,進而進一步讓計算在 GPU 間類似微流水(圖 2 中 c 所示)的方式進行并行。進一步提高 GPU 的使用率。另外一種并行方式是算子拆分,就是将神經網絡縱向分割(如圖 3 所示),把一個算子計算切割到不同節點進行計算,這種方式克服了流水因為計算依賴關系造成的 GPU 閑置的問題,但是不同算子分布式計算需要不同計算和拆分方式才能有效進行并行化,并且并行效率也和算子類型息息相關,是以這種方式往往需要非常大開發成本才能很好對模型進行并行訓練。其實大規模推薦稀疏模型也是一種算子拆分的方式,隻是這個算子是一個簡單的稀疏特征的 lookup 算子而已。雖然研究人員很快在TensorFlow 這個架構基礎上給出多樣的并行方式進而能夠訓練任意大的模型,但是因為 GPU 的硬體發展也很快,GPU 的顯存大小也得到快速的發展。是以在很長的時間,除了推薦類大規模稀疏模型訓練,感覺類模型訓練隻是需要資料并行方式進行訓練,直到 2019 年有一篇重量性工作《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》[16]的發表。

圖 2 流水并行(選自[14])
圖 3 算子拆分
Bert推動超大規模預訓練模型快速發展,這種 transformer 為基礎的模型結構推動着感覺類模型的參數規模從億級别迅速進入到千億以及萬億規模,例如GTP-2[17],GTP-3[18],T5[19],M6[20]等等。終于複雜的模型并行從學術研究領域進入到企業界實際落地過程中。目前的超大規模模型往往需要根據模型的特點,進行多種并行訓練方式的混合并行。這也是大家有時候叫做 3D,4D,5D 分布式訓練,其實本質上就是把所有這些技巧綜合在一起。
是以總結起來分布式并行訓練的範式分為
- 大規模稀疏模型訓練:參數伺服器方式,異步訓練為主
- 大規模稠密模型訓練
- 資料并行:AllReduce 或者參數伺服器進行梯度彙總,利用極緻的顯存優化(CPU-offload,Zero 梯度優化器優化,checkpoint 等)進一步擴大單節點的模型大小
- 流水并行
- 算子切分
- 混合并行
大規模并行分布式訓練的發展方向
自動分布式訓練:模型混合并行日益重要,但是混合并行往往需要根據模型的特點和叢集資源現狀,選擇不同并行方式在模型不同部分,如果這個都需要模型的建構者來進行選擇,整個問題是一個 NP 問題,會給模型建構者帶來巨大的研發成本,使得很難進行快速算法研發疊代,為了更加系統的解決這個混合并行的尋優問題,産研界進行積極相應的研究,比如 GShard[21],OneFlow[22],Whale[23]等。其核心思路就是利用靜态圖邏輯性地描述一個網絡訓練步驟,執行的時候再進行系統化的分圖和分布式訓練,利用反映了現實限制的成本分析模型(Cost Model)對于不同并行政策進行評估,最後自動選擇最優的并行方案。
這些工作中,GShard 更多關注于谷歌的 TPU 叢集,OneFlow 從重新建構一個面向分布式的深度學習生态,而 Whale 其實采取的理念是讓算法同學利用現有深度學習生态,如同建構一個單卡的模型訓練的方式去建構,并且能夠在異構資源(不同能力的加速卡能力)環境找到更優的混合并行方案。圖 4 展示了 Whale 的整體架構圖。Whale 會把模型訓練腳本轉換成一個的 DAG 靜态圖,然後進一步轉化成自有中間代碼(Intermediate Representation,IR)描述的邏輯執行計劃,然後系統進行自動規劃,再根據規劃出來的并行政策對執行計劃進行切圖,并且把系統資源進行相應的劃分,再把切圖的結果和資源綁定,最後讓 Cost Model 在多個可能并行政策上進行選擇,進而自動尋找到接近最優的分布式政策。
圖 4 Whale 整體構架圖
更大規模異構多模态多任務的模型訓練: 随着模型算法,資料以及算力的發展,研究者終于可以開始建構神經網絡算法最初的設想,就是建立類似大腦多任務綜合在一起學習的方式,進而使得機器學習能夠進一步仿真人腦的認知過程,把語言,視覺,聽覺等多個認知任務關聯在一起來進行整體訓練,這個就要求更加異構的訓練過程。Pathways[24] 就是在這個方向最新的探索。
總之,随着網際網路的蓬勃發展,人們開始積累非常多的有價值的資料,同時随着半導體行業的方式使得我們具備足夠算力使得模型研究者能夠更敢去建構更加大型的模型,進而大大提升了模型的效果,産生能夠媲美人類認知的人工智能模型,而大規模分布式訓練的工程成為能夠粘合資料,算力和算法的關鍵。
參考文獻:
[1] KunPeng: Parameter Server based Distributed Learning Systems and Its Applications in Alibaba and Ant Financial. KDD 2017.
[2] Persia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters.CoRR 2021.
[3] Scaling Distributed Machine Learning with the Parameter Server. OSDI 2014.
[4] Parameter server for distributed machine learning. NIPS 2013.
[5] More effective distributed ml via a stale synchronous parallel parameter server. NIPS 2013.
[6] ImageNet Classification with Deep Convolutional Neural Networks. NIPS 2012.
[7] Going deeper with convolution. CVPR 2015.
[8] Deep Residual Learning for Image Recognition. CVPR 2016.
[9] https://www.nvidia.com/en-us/data-center/nvlink/
[10] https://developer.nvidia.com/nccl
[11] A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters. OSDI 2020.
[12]Wide & Deep Learning for Recommender System. DLRS 2016.
[13]https://www.tensorflow.org
[14] GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism. NIPS 2019.
[15] Mesh-TensorFlow: Deep Learning for Supercomputers. NIPS 2018.
[16] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL-HLT 2019
[17] https://huggingface.co/docs/transformers/model_doc/gpt2
[18] https://openai.com/blog/gpt-3-apps/
[19] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Mach. Learn. Res. 2021.
[20] M6: Multi-Modality-to-Multi-Modality Multitask Mega-transformer for Unified Pretraining. KDD 2021
[21] GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. CoRR 2020.
[22] OneFlow: Redesign the Distributed Deep Learning Framework from Scratch. CoRR 2021
[23] Whale: Scaling Deep Learning Model Training to the Trillions. https://arxiv.org/pdf/2011.09208.pdf
[24] https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/
[25] ZeRO: memory optimizations toward training trillion parameter models. SC 2020
[25] DeepSpeed: https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/