github:https://github.com/yinwenpeng/Answer_Selection。
摘要
如何對一個句子對進行模組化是許多NLP任務中的關鍵問題,例如答案選擇(AS),複述識别(PI)和文本蘊涵(TE)。大多數先前的工作通過如下方法來解決問題:(1)通過微調特定系統來處理一項單獨的任務; (2)分别對每個句子的表示進行模組化,很少考慮另一句話的影響;(3)完全依賴人為設計的,用于特定任務的語言特征。在這項工作中,我們提出了一種基于注意力的卷積神經網絡(ABCNN),用于對句子對進行模組化。我們做出了以下三個貢獻:(1)ABCNN可以應用于需要對句子對進行模組化的各種任務;(2)我們提出三種注意力方案,将句子之間的互相影響納入CNN,是以,每個句子的表示都考慮到了它的對應句子。這些互相依賴的句子對表示比孤立的句子表示更強大;(3)ABCNN在AS,PI和TE任務上實作了最佳性能。
1 介紹
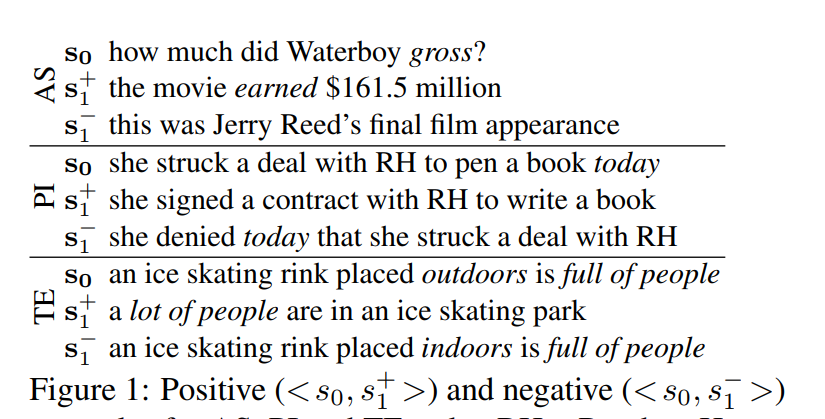
如何對一對句子進行模組化是許多NLP任務中的關鍵問題,例如答案選擇(AS),複述識别(PI),文本蘊涵(TE)等。
大多數先前的工作分别得到每個句子的表示,很少考慮另一個句子的影響。這忽略了兩個句子在相同任務背景下的互相影響。分别得到句子表示也與人類在比較兩個句子時的行為相沖突。我們通常通過從另一個句子中提取與身份,同義詞,反義和其他關系相關的部分來比較與另一個句子的關鍵内容。是以,人類将通過兩個句子一起模組化,使用一個句子的内容來指導另一個句子的表示。
圖1表明,一個句子對中的每個句子部分地決定了我們必須關注另一個句子的哪些部分。在上圖的AS中,正确回答 s 0 s_0 s0需要注意 g r o s s gross gross: s 1 + s^+_1 s1+包含相應的部分( e a r n e d earned earned),而 s 1 − s^-_1 s1−則不包含。對于PI,注意力應該從 t o d a y today today中删除,以正确識别 < s 0 , s 1 + > <s_0,s^+_1> <s0,s1+>作為釋義, < s 0 , s 1 − > <s_0,s^-_1> <s0,s1−>作為非釋義。 對于TE,我們需要關注 f u l l o f p e o p l e full~of~people full of people(識别TE為 < s 0 , s 1 + > <s_0,s^+_1> <s0,s1+>)和 o u t d o o r s / i n d o o r s outdoors/indoors outdoors/indoors(以識别非TE為 < s 0 , s 1 − > <s_0,s^-_1> <s0,s1−>)。這些示例表明需要一種體系結構來計算在不同 s 1 − i ( i ∈ 0 , 1 ) s_{1-i}(i∈{0,1}) s1−i(i∈0,1)的情況下 s i s_i si的不同表示。
卷積神經網絡(CNNs)被廣泛用于模組化句子和句子對,特别是在分類任務中。CNN應該善于提取出健壯和抽象的輸入特征。 在這項工作中提出了ABCNN,一種基于注意力的卷積神經網絡,它具有強大的機制,通過考慮兩個句子之間的互相依賴性來模組化句子對。ABCNN是一種通用架構,可以處理各種句子對模組化任務。
一些先前的工作提出了簡單的機制,可以解釋為控制不同的注意力; 例如,Yih等人使用單詞對齊來比對兩個句子的相關部分。相比之下,我們基于CNN的注意力方案完全自動地模拟了兩個部分之間的相關性。此外,當我們堆疊多個用來增加抽象特征的卷積層時,不僅在字元級上,其在多個粒度上實作了注意力機制。
深度學習(DL)中在注意力機制上的先前工作主要涉及長期短期記憶網絡(LSTM)。LSTM通常在單詞到單詞方案中計算注意力,并且單詞表示主要由句子中的整個上下文進行編碼。目前尚不清楚這是否是最佳政策,例如,在圖1的AS示例中,在不考慮整個句子上下文的情況下,可以确定 s 0 s_0 s0中的 “ h o w m u c h ” “how~much” “how much”與 s 1 s_1 s1中的 “ 161.5 m i l l i o n ” “161.5~million” “161.5 million”比對。Yao等人也研究了這一觀察結果,其中資訊檢索系統通過命名實體識别來檢索具有标記為DATE的字元的句子,或者如果存在 “ w h e n ” “when” “when”問題則通過POS标記為CD。但是,标簽或POS标簽需要額外的工具。CNN受益于将注意力集中到由filter檢測到的局部短語的表示中,相比之下,LSTM編碼整個上下文以形成基于注意力的單詞表示 - 一種比CNN政策更複雜的政策,而對于某些任務來說則效果不是特别好。
除了這些差異之外,很明顯,注意力機制在CNNs上的應用具有和LSTMs相同的潛力。據我們所知,這是第一個将注意力納入CNN的NLP論文。我們的ABCNN在AS和TE任務中獲得最好的效果,在PI中具有競争性,然後在使用語言特征時獲得對所有三個任務的進一步改進。
2 相關工作
(1)非深度學習的句子對模組化
在過去的幾十年裡,句子對模組化引起了很多關注。許多的任務可以簡化為語義文本比對問題。在本文中,我們采用了Yih等人的論證,他們反對淺層方法以及語義文本比對方法,這些方法在計算上可能很昂貴:
Due to the variety of word choices and inherent ambiguities in natural language, bag-of-word approaches with simple surface-form word matching tend to produce brittle results with poor prediction accuracy (Bilotti et al., 2007). As a result, researchers put more emphasis on exploiting syntactic and semantic structure. Representative examples include methods based on deeper semantic analysis (Shen and Lapata, 2007; Moldovan et al., 2007), tree edit-distance (Punyakanok et al., 2004; Heilman and Smith, 2010) and quasi-synchronous grammars (Wang et al., 2007) that match the dependency parse trees of the two sentences.
不是專注于進階語義表示,Yih等人通過基于潛在的詞對齊結構執行語義比對,将注意力轉向改進淺層語義成分、詞彙語義。 Lai和Hockenmaier使用否定,上位詞,同義詞和反義詞關系來探索兩個句子之間的細粒度重疊和對齊。 姚等人通過條件随機場CRF将詞對齊擴充到詞組到詞組的對齊。然而,這種方法通常需要更多的計算資源。 此外,使用句法或語義解析器(在許多句子上産生錯誤)來找到兩個句子的結構化表示之間的最佳比對并非易事。
(2)深度學習的句子對模組化
為了解決非DL工作的一些挑戰,最近的工作使用神經網絡來對AS,PI和TE的句子對進行模組化。
對于AS,Yu等人提出了一個二進制CNN來模組化問答候選集。楊等人擴充了此方法并在WikiQA資料集上獲得最好的性能(第5.1節)。馮等人在保險領域QA資料集上測試二進制CNN架構的各種參數設定。Tan等人在同一資料集上探索雙向LSTM。我們的方法是不同的,因為我們不是通過兩個獨立的神經網絡并行模組化句子,而是作為一個互相依賴的句子對,使用注意力機制進行模組化。
對于PI,Blacoe和Lapata通過總合單詞詞嵌入來形成句子表示。Socher等使用遞歸自動編碼器(RAE)來模拟句子中的局部短語的表示,然後将來自兩個句子的短語的相似度值作為二進制分類的特征。Yin和Schutze同樣用CNN取代了RAE。在以上三篇論文中,一個句子的表示不受另一個句子的影響,這與我們基于注意力的模型相反。
對于TE,Bowman等人使用遞歸神經網絡編碼SICK上的蘊涵。Rocktaschel等人為斯坦福自然語言推理語料庫提出了一種基于注意力的LSTM。我們的系統是第一個基于CNN的TE工作。
一些先前的工作旨在解決一般句子比對問題。胡等人提出雙CNN架構,ARC-I和ARC-II,用于句子比對。ARC-I側重于句子表示學習,而ARC-II側重于短語級别的比對特征。兩個系統都在PI,句子填空(SC)和tweetresponse比對上進行了測試。Yin和Schutze提出了MultiGranCNN架構,以基于多個粒度級别的短語比對對一般句子比對進行模組化,并在PI和SC上獲得了有效的結果。Wan等人嘗試通過多個句子表示來比對AS和SC中的兩個句子,每個句子來自兩個LSTM的局部表示。我們的工作是第一個研究基于注意力的一般句子比對任務的工作。
(3)在非NLP領域的基于注意力的深度學習
盡管基于注意力機制的CNN在NLP領域的研究很少,但基于注意力的CNN已被用于計算機視覺中的視覺問答,圖像分類, 标題生成,圖像分割和目标定位。
Mnih等人将注意力應用于循環神經網絡(RNNs),通過自适應地選擇一系列區域或位置以提取來自圖像或視訊的資訊,并且僅以高分辨率處理所選區域。Gregor等将空間注意力機制與RNN結合用于圖像生成。Ba等人研究基于注意力的RNN,用于識别圖像中的多個目标。Chorowski和Chorowski等人在RNN中使用注意力進行語音識别。
(2)在NLP領域的基于注意力的深度學習
在計算機視覺和語音識别方面取得成功之後,基于注意力的DL系統已應用于NLP。它們主要依靠RNNs和端到端的編碼解碼器來完成機器翻譯和文本重建等任務。我們的工作率先探索了CNN中針對NLP任務的注意力機制。
3 BCNN:Basic Bi-CNN

我們現在介紹基于Siamese架構的基本(非注意力)CNN,即它由兩個權重共享CNN組成,每個CNN負責處理兩個句子中的一個,最後一層則解決句子對任務。參見圖2,我們将此體系結構稱為BCNN。接下來的部分将介紹ABCNN,這是一種擴充BCNN的注意力架構。表1給出了我們的符号約定。
在我們的實作中以及下面給出的模型的數學形式化中,我們将兩個句子填充為具有相同的長度 s = m a x ( s 0 , s 1 ) s=max(s_0,s_1) s=max(s0,s1)。但是,在圖中我們顯示了不同的長度,因為這樣可以更好地直覺地了解模型的工作原理。
我們現在描述BCNN的四種類型的層:輸入層,卷積層,平均池化層和輸出層。
(1)輸入層
在圖中的示例中,兩個輸入句子分别具有5個和7個單詞。每個單詞被表示為一個 d 0 = 300 d_0=300 d0=300維的預先計算的word2vec詞嵌入。結果是,每個句子被表示為一個次元是 d 0 × s d_0×s d0×s的特征映射。
(2)卷積層
設 v 1 , v 2 , . . . , v s v_1,v_2,...,v_s v1,v2,...,vs是一個句子的單詞, c i ∈ R w ⋅ d 0 , 0 < i < s + w c_i∈R^{w·d_0},0<i<s+w ci∈Rw⋅d0,0<i<s+w為 v i − w + 1 , . . . , v i v_{i-w+1},...,v_i vi−w+1,...,vi的連接配接詞嵌入,當 j < 1 j<1 j<1或 j > s j>s j>s時, v j v_j vj的嵌入被設定為零。然後,我們使用卷積權重 W ∈ R d 1 × w d 0 W∈R^{d_1×wd_0} W∈Rd1×wd0為短語 v i − w + 1 , . . . , v i v_{i-w+1},... ,v_i vi−w+1,...,vi生成表示 p i ∈ R d 1 p_i∈R^{d_1} pi∈Rd1,公式如下:
p i = t a n h ( W ⋅ c i + b ) p_i=tanh(W\cdot c_i+b) pi=tanh(W⋅ci+b)
其中, b ∈ R d i b\in R^{d_i} b∈Rdi是偏差。
(3)平均池化層
池化(包括最小值,最大值,平均池化)通常用于從卷積中提取健壯特征。在本文中,我們引入注意力權重作為替代,但使用平均池化作為一個baseline。
對于最後一個卷積層的輸出特征映射,我們對所有列進行按列平均,表示為 a l l − a p all-ap all−ap。通過這種方法,為兩個句子中的每一個生成一個表示向量,如圖2中““Logistic regression”下面頂部的“Average pooling (all-ap)”層所示。這兩個向量是句子對進行決策的基礎。
對于非最終卷積層的輸出特征映射,我們對 w w w個連續列的視窗進行按列平均,表示為 w − a p w-ap w−ap;圖2中顯示為較低的“Average pooling (w-ap)”層。對于filter寬度 w w w,卷積層将 s s s列的輸入特征映射轉換為 s + w − 1 s + w-1 s+w−1列的新特征映射; 平均池化将其轉換回 s s s列。該體系結構支援堆疊任意數量的卷積-池化塊,以提取越來越抽象的特征。底層的輸入要素是單詞,下一層的輸入要素是短語等。每個級别都會生成更高粒度的抽象表示。
(4)輸出層
最後一層是輸出層,根據任務選擇;例如,對于二分類任務,該層是邏輯回歸(參見圖2)。下面介紹其他類型的輸出層。
我們發現,在大多數情況下,如果我們提供所有池化層的輸出作為輸出層的輸入,則性能會提高。對于每個非最終平均池化層,我們如上所述執行 w − a p w-ap w−ap(彙集w列的視窗),但我們同樣執行 a l l − a p all-ap all−ap(彙集所有列)并将結果轉發到輸出層。這提高了模型性能,因為來自不同層的表示覆寫了不同抽象級别的句子屬性,并且所有這些級别對于特定句子對都很重要。
4.ABCNN:Attention-Based BCNN
我們現在描述基于BCNN的三種體系結構,ABCNN-1,ABCNN-2和ABCNN-3,它們各自引入了不同的用于句子對模組化的注意力機制;見圖3。
(1)ABCNN-1
ABCNN-1(圖3(a))采用注意力特征矩陣 A A A來影響卷積。注意力特征旨在以與 s 1 − i ( i ∈ 0 , 1 ) s_{1-i}(i∈{0,1}) s1−i(i∈0,1)的單元相關的卷積中更高的 s i s_i si單元權重;我們在這裡使用術語“單元”來指代最低級别的單詞和網絡較進階别的短語。圖3(a)顯示了紅色的兩個機關表示特征映射:ABCNN-1的這部分與BCNN中的相同(參見圖2)。每列是機關的表示,即最低級别的單詞和較進階别的短語。我們首先非正式地描述注意力特征矩陣 A A A(“Conv input”層的中間中部,見圖3(a))。通過将左表示特征映射的單元與右表示特征映射的單元比對來生成A,使得 A A A中的第 i i i行的注意力值表示 s 0 s_0 s0的第 i i i個單元相對于 s 1 s_1 s1的注意力分布,并且注意 A A A中的第 j j j列的值表示 s 1 s_1 s1的第 j j j個單元相對于 s 0 s_0 s0的注意分布。 A A A可以被視為 s 0 ( r e s p . s 1 ) s_0(resp.s_1) s0(resp.s1)在 r o w ( r e s p . c o l ) row(resp.col) row(resp.col)方向上的新特征映射,因為每 r o w ( r e s p . c o l ) row(resp.col) row(resp.col)是 s 0 ( r e s p . s 1 ) s_0(resp.s_1) s0(resp.s1)中單元的新特征向量。是以,将這個新的特征映射與表示特征映射組合并将它們用作卷積運算的輸入是有意義的。我們通過将 A A A轉換為圖3(a)中具有與表示特征映射相同格式的兩個藍色矩陣來實作這一點。是以,卷積的新輸入具有每個句子的兩個特征映射(以紅色和藍色顯示)。我們的動機是注意力特征映射将指導卷積學習“對應偏差”的句子表示。
更正式地,令 F i , r ∈ R d × s F_{i,r}∈R^{d×s} Fi,r∈Rd×s為句子 i ( i ∈ 0 , 1 ) i(i∈{0,1}) i(i∈0,1)的表示特征映射。然後我們将注意矩陣 A ∈ R s × s A∈R^{s×s} A∈Rs×s定義如下:
A i , j = m a t c h − s c o r e ( F 0 , r [ : , i ] , F 1 , r [ : , j ] ) ( 1 ) A_{i,j}=match-score(F_{0,r}[:, i], F_{1,r}[:, j]) \qquad (1) Ai,j=match−score(F0,r[:,i],F1,r[:,j])(1)
打分函數可以以多種方式定義。我們發現 1 / ( 1 + ∣ x − y ∣ ) 1 /(1+| x-y |) 1/(1+∣x−y∣)具有很好的效果,其中 ∣ ⋅ ∣ |·| ∣⋅∣是歐氏距離。
給定注意力矩陣 A A A,我們生成 s i s_i si的注意力特征映射 F i , a F_{i,a} Fi,a,如下所示:
F 0 , a = W 0 ⋅ A ⊤ , F 1 , a = W 1 ⋅ A F_{0,a} = W_0·A^{\top}, F_{1,a} = W_1 · A F0,a=W0⋅A⊤,F1,a=W1⋅A
權重矩陣 W 0 ∈ R d × s W_0∈R^{d×s} W0∈Rd×s, W 1 ∈ R d × s W_1∈R^{d×s} W1∈Rd×s是訓練中要學習的模型的參數
我們将表示特征映射 F i , r F_{i,r} Fi,r和注意力特征映射 F i , a F_{i,a} Fi,a作為3維張量堆疊并将其饋送到卷積以生成 s i ( i ∈ 0 , 1 ) s_i(i∈{0,1}) si(i∈0,1)的更進階别表示特征映射。在圖3(a)中, s 0 s_0 s0有5個單元, s 1 s_1 s1有7個。卷積的輸出(在頂層顯示,filter寬度w = 3)是一個更進階别的表示特征映射,其中7列用于 s 0 s_0 s0和9列用于 s 1 s_1 s1。
(2)ABCNN-2
ABCNN-1直接在輸入表示上計算注意力權重,目的是改進通過卷積計算的特征。ABCNN-2(圖3(b))改為計算卷積層輸出的注意力權重,目的是重新權重該卷積層的輸出。在圖3(b)所示的例子中,通過卷積輸出的 s 0 s_0 s0和 s 1 s_1 s1的特征映射(圖3(b)中标記為“Convolution”的層)分别具有7列和9列; 每列是一個單元的表示。注意力矩陣 A A A将 s 0 s_0 s0中的所有單元與 s 1 s_1 s1的所有單元進行比較。我們将一個單元的所有注意力值相加,以得出該單元的單個注意力。對于 s 0 s_0 s0,這對應于對 A A A中一行的所有值求和(“col-wise sum”,得到顯示的大小為7的列向量),對于 s 1 s_1 s1,則對應于對 A A A中每一列中的所有值求和(“row-wise sum”,得到顯示大小為9的行向量)。
更正式地,令 A ∈ R s × s A∈R^{s×s} A∈Rs×s為注意力矩陣, a 0 , j = ∑ A [ j , : ] a_{0,j} =\sum A[j,:] a0,j=∑A[j,:]為 s 0 s_0 s0中的單元 j j j的注意力權重, a 1 , j = ∑ A [ : , j ] a_{1,j} =\sum A[:,j] a1,j=∑A[:,j]為 s 1 s_1 s1中的單元 j j j的注意力權重,并且 F i , r c ∈ R d × ( s i + w − 1 ) F^c_{i,r}∈R^{d×(si + w-1)} Fi,rc∈Rd×(si+w−1)為 s i s_i si的卷積輸出。然後由 w − a p w-ap w−ap生成的新特征映射 F i , r p F^p_{i,r} Fi,rp的第 j j j列由以下公式導出:
F i , r p [ : , j ] = ∑ k = j : j + w a i , k F i , r c [ : , k ] , j = 1... s i F^p_{i,r}[:, j]=\sum_{k=j:j+w}a_{i,k}F^c_{i,r}[:, k],\qquad j = 1 . . . s_i Fi,rp[:,j]=k=j:j+w∑ai,kFi,rc[:,k],j=1...si
注意, F i , r p ∈ R d × s i F^p_{i,r}∈R^{d×s_i} Fi,rp∈Rd×si,即ABCNN-2的池化層生成一個與卷積的輸入特征映射相同大小的輸出特征映射。這允許我們堆疊多個卷積池子產品以提取更加抽象的特征。
ABCNN-1和ABCNN-2之間存在三個主要差異。(i)ABCNN-1中的注意力間接影響卷積,而ABCNN-2中的注意力通過直接注意力權重影響池化層。(ii)ABCNN-1要求使用兩個矩陣 W i W_i Wi将注意力矩陣轉換為注意力特征映射;并且卷積的輸入具有兩倍的特征映射。是以,ABCNN-1具有比ABCNN-2更多的參數,并且更容易過拟合。(iii)由于池化是在卷積後進行的,是以池化處理比卷積更大的粒度機關;例如,如果卷積的輸入具有詞級别的粒度,則對池化的輸入具有短語級别的粒度,短語大小等于filter的大小 w w w。是以,ABCNN-1和ABCNN-2實作了針對不同粒度級别的語言單元的注意力機制。ABCNN-1和ABCNN-2的互補性促使我們提出ABCNN-3,這是結合兩者特性的第三種結構。
(3)ABCNN-3
ABCNN-3(圖3©)通過堆疊ABCNN-1和ABCNN-2組合而成;它結合了ABCNN-1和-2的優勢,允許注意力機制:(i)同時計算卷積池和池化層部分(ii)同時計算輸入粒度和更抽象的輸出粒度。