github:https://github.com/yinwenpeng/Answer_Selection。
摘要
如何对一个句子对进行建模是许多NLP任务中的关键问题,例如答案选择(AS),复述识别(PI)和文本蕴涵(TE)。大多数先前的工作通过如下方法来解决问题:(1)通过微调特定系统来处理一项单独的任务; (2)分别对每个句子的表示进行建模,很少考虑另一句话的影响;(3)完全依赖人为设计的,用于特定任务的语言特征。在这项工作中,我们提出了一种基于注意力的卷积神经网络(ABCNN),用于对句子对进行建模。我们做出了以下三个贡献:(1)ABCNN可以应用于需要对句子对进行建模的各种任务;(2)我们提出三种注意力方案,将句子之间的相互影响纳入CNN,因此,每个句子的表示都考虑到了它的对应句子。这些相互依赖的句子对表示比孤立的句子表示更强大;(3)ABCNN在AS,PI和TE任务上实现了最佳性能。
1 介绍
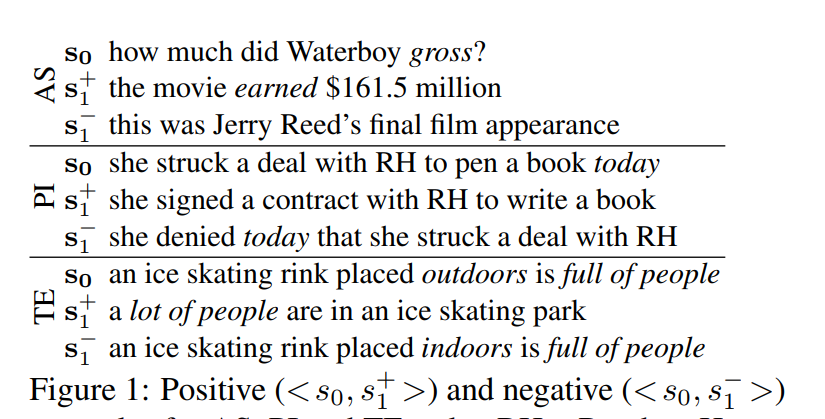
如何对一对句子进行建模是许多NLP任务中的关键问题,例如答案选择(AS),复述识别(PI),文本蕴涵(TE)等。
大多数先前的工作分别得到每个句子的表示,很少考虑另一个句子的影响。这忽略了两个句子在相同任务背景下的相互影响。分别得到句子表示也与人类在比较两个句子时的行为相矛盾。我们通常通过从另一个句子中提取与身份,同义词,反义和其他关系相关的部分来比较与另一个句子的关键内容。因此,人类将通过两个句子一起建模,使用一个句子的内容来指导另一个句子的表示。
图1表明,一个句子对中的每个句子部分地决定了我们必须关注另一个句子的哪些部分。在上图的AS中,正确回答 s 0 s_0 s0需要注意 g r o s s gross gross: s 1 + s^+_1 s1+包含相应的部分( e a r n e d earned earned),而 s 1 − s^-_1 s1−则不包含。对于PI,注意力应该从 t o d a y today today中删除,以正确识别 < s 0 , s 1 + > <s_0,s^+_1> <s0,s1+>作为释义, < s 0 , s 1 − > <s_0,s^-_1> <s0,s1−>作为非释义。 对于TE,我们需要关注 f u l l o f p e o p l e full~of~people full of people(识别TE为 < s 0 , s 1 + > <s_0,s^+_1> <s0,s1+>)和 o u t d o o r s / i n d o o r s outdoors/indoors outdoors/indoors(以识别非TE为 < s 0 , s 1 − > <s_0,s^-_1> <s0,s1−>)。这些示例表明需要一种体系结构来计算在不同 s 1 − i ( i ∈ 0 , 1 ) s_{1-i}(i∈{0,1}) s1−i(i∈0,1)的情况下 s i s_i si的不同表示。
卷积神经网络(CNNs)被广泛用于建模句子和句子对,特别是在分类任务中。CNN应该善于提取出健壮和抽象的输入特征。 在这项工作中提出了ABCNN,一种基于注意力的卷积神经网络,它具有强大的机制,通过考虑两个句子之间的相互依赖性来建模句子对。ABCNN是一种通用架构,可以处理各种句子对建模任务。
一些先前的工作提出了简单的机制,可以解释为控制不同的注意力; 例如,Yih等人使用单词对齐来匹配两个句子的相关部分。相比之下,我们基于CNN的注意力方案完全自动地模拟了两个部分之间的相关性。此外,当我们堆叠多个用来增加抽象特征的卷积层时,不仅在字符级上,其在多个粒度上实现了注意力机制。
深度学习(DL)中在注意力机制上的先前工作主要涉及长期短期记忆网络(LSTM)。LSTM通常在单词到单词方案中计算注意力,并且单词表示主要由句子中的整个上下文进行编码。目前尚不清楚这是否是最佳策略,例如,在图1的AS示例中,在不考虑整个句子上下文的情况下,可以确定 s 0 s_0 s0中的 “ h o w m u c h ” “how~much” “how much”与 s 1 s_1 s1中的 “ 161.5 m i l l i o n ” “161.5~million” “161.5 million”匹配。Yao等人也研究了这一观察结果,其中信息检索系统通过命名实体识别来检索具有标记为DATE的字符的句子,或者如果存在 “ w h e n ” “when” “when”问题则通过POS标记为CD。但是,标签或POS标签需要额外的工具。CNN受益于将注意力集中到由filter检测到的局部短语的表示中,相比之下,LSTM编码整个上下文以形成基于注意力的单词表示 - 一种比CNN策略更复杂的策略,而对于某些任务来说则效果不是特别好。
除了这些差异之外,很明显,注意力机制在CNNs上的应用具有和LSTMs相同的潜力。据我们所知,这是第一个将注意力纳入CNN的NLP论文。我们的ABCNN在AS和TE任务中获得最好的效果,在PI中具有竞争性,然后在使用语言特征时获得对所有三个任务的进一步改进。
2 相关工作
(1)非深度学习的句子对建模
在过去的几十年里,句子对建模引起了很多关注。许多的任务可以简化为语义文本匹配问题。在本文中,我们采用了Yih等人的论证,他们反对浅层方法以及语义文本匹配方法,这些方法在计算上可能很昂贵:
Due to the variety of word choices and inherent ambiguities in natural language, bag-of-word approaches with simple surface-form word matching tend to produce brittle results with poor prediction accuracy (Bilotti et al., 2007). As a result, researchers put more emphasis on exploiting syntactic and semantic structure. Representative examples include methods based on deeper semantic analysis (Shen and Lapata, 2007; Moldovan et al., 2007), tree edit-distance (Punyakanok et al., 2004; Heilman and Smith, 2010) and quasi-synchronous grammars (Wang et al., 2007) that match the dependency parse trees of the two sentences.
不是专注于高级语义表示,Yih等人通过基于潜在的词对齐结构执行语义匹配,将注意力转向改进浅层语义成分、词汇语义。 Lai和Hockenmaier使用否定,上位词,同义词和反义词关系来探索两个句子之间的细粒度重叠和对齐。 姚等人通过条件随机场CRF将词对齐扩展到词组到词组的对齐。然而,这种方法通常需要更多的计算资源。 此外,使用句法或语义解析器(在许多句子上产生错误)来找到两个句子的结构化表示之间的最佳匹配并非易事。
(2)深度学习的句子对建模
为了解决非DL工作的一些挑战,最近的工作使用神经网络来对AS,PI和TE的句子对进行建模。
对于AS,Yu等人提出了一个二元CNN来建模问答候选集。杨等人扩展了此方法并在WikiQA数据集上获得最好的性能(第5.1节)。冯等人在保险领域QA数据集上测试二元CNN架构的各种参数设置。Tan等人在同一数据集上探索双向LSTM。我们的方法是不同的,因为我们不是通过两个独立的神经网络并行建模句子,而是作为一个相互依赖的句子对,使用注意力机制进行建模。
对于PI,Blacoe和Lapata通过总合单词词嵌入来形成句子表示。Socher等使用递归自动编码器(RAE)来模拟句子中的局部短语的表示,然后将来自两个句子的短语的相似度值作为二元分类的特征。Yin和Schutze同样用CNN取代了RAE。在以上三篇论文中,一个句子的表示不受另一个句子的影响,这与我们基于注意力的模型相反。
对于TE,Bowman等人使用递归神经网络编码SICK上的蕴涵。Rocktaschel等人为斯坦福自然语言推理语料库提出了一种基于注意力的LSTM。我们的系统是第一个基于CNN的TE工作。
一些先前的工作旨在解决一般句子匹配问题。胡等人提出双CNN架构,ARC-I和ARC-II,用于句子匹配。ARC-I侧重于句子表示学习,而ARC-II侧重于短语级别的匹配特征。两个系统都在PI,句子填空(SC)和tweetresponse匹配上进行了测试。Yin和Schutze提出了MultiGranCNN架构,以基于多个粒度级别的短语匹配对一般句子匹配进行建模,并在PI和SC上获得了有效的结果。Wan等人尝试通过多个句子表示来匹配AS和SC中的两个句子,每个句子来自两个LSTM的局部表示。我们的工作是第一个研究基于注意力的一般句子匹配任务的工作。
(3)在非NLP领域的基于注意力的深度学习
尽管基于注意力机制的CNN在NLP领域的研究很少,但基于注意力的CNN已被用于计算机视觉中的视觉问答,图像分类, 标题生成,图像分割和目标定位。
Mnih等人将注意力应用于循环神经网络(RNNs),通过自适应地选择一系列区域或位置以提取来自图像或视频的信息,并且仅以高分辨率处理所选区域。Gregor等将空间注意力机制与RNN结合用于图像生成。Ba等人研究基于注意力的RNN,用于识别图像中的多个目标。Chorowski和Chorowski等人在RNN中使用注意力进行语音识别。
(2)在NLP领域的基于注意力的深度学习
在计算机视觉和语音识别方面取得成功之后,基于注意力的DL系统已应用于NLP。它们主要依靠RNNs和端到端的编码解码器来完成机器翻译和文本重建等任务。我们的工作率先探索了CNN中针对NLP任务的注意力机制。
3 BCNN:Basic Bi-CNN

我们现在介绍基于Siamese架构的基本(非注意力)CNN,即它由两个权重共享CNN组成,每个CNN负责处理两个句子中的一个,最后一层则解决句子对任务。参见图2,我们将此体系结构称为BCNN。接下来的部分将介绍ABCNN,这是一种扩展BCNN的注意力架构。表1给出了我们的符号约定。
在我们的实现中以及下面给出的模型的数学形式化中,我们将两个句子填充为具有相同的长度 s = m a x ( s 0 , s 1 ) s=max(s_0,s_1) s=max(s0,s1)。但是,在图中我们显示了不同的长度,因为这样可以更好地直观地了解模型的工作原理。
我们现在描述BCNN的四种类型的层:输入层,卷积层,平均池化层和输出层。
(1)输入层
在图中的示例中,两个输入句子分别具有5个和7个单词。每个单词被表示为一个 d 0 = 300 d_0=300 d0=300维的预先计算的word2vec词嵌入。结果是,每个句子被表示为一个维度是 d 0 × s d_0×s d0×s的特征映射。
(2)卷积层
设 v 1 , v 2 , . . . , v s v_1,v_2,...,v_s v1,v2,...,vs是一个句子的单词, c i ∈ R w ⋅ d 0 , 0 < i < s + w c_i∈R^{w·d_0},0<i<s+w ci∈Rw⋅d0,0<i<s+w为 v i − w + 1 , . . . , v i v_{i-w+1},...,v_i vi−w+1,...,vi的连接词嵌入,当 j < 1 j<1 j<1或 j > s j>s j>s时, v j v_j vj的嵌入被设置为零。然后,我们使用卷积权重 W ∈ R d 1 × w d 0 W∈R^{d_1×wd_0} W∈Rd1×wd0为短语 v i − w + 1 , . . . , v i v_{i-w+1},... ,v_i vi−w+1,...,vi生成表示 p i ∈ R d 1 p_i∈R^{d_1} pi∈Rd1,公式如下:
p i = t a n h ( W ⋅ c i + b ) p_i=tanh(W\cdot c_i+b) pi=tanh(W⋅ci+b)
其中, b ∈ R d i b\in R^{d_i} b∈Rdi是偏差。
(3)平均池化层
池化(包括最小值,最大值,平均池化)通常用于从卷积中提取健壮特征。在本文中,我们引入注意力权重作为替代,但使用平均池化作为一个baseline。
对于最后一个卷积层的输出特征映射,我们对所有列进行按列平均,表示为 a l l − a p all-ap all−ap。通过这种方法,为两个句子中的每一个生成一个表示向量,如图2中““Logistic regression”下面顶部的“Average pooling (all-ap)”层所示。这两个向量是句子对进行决策的基础。
对于非最终卷积层的输出特征映射,我们对 w w w个连续列的窗口进行按列平均,表示为 w − a p w-ap w−ap;图2中显示为较低的“Average pooling (w-ap)”层。对于filter宽度 w w w,卷积层将 s s s列的输入特征映射转换为 s + w − 1 s + w-1 s+w−1列的新特征映射; 平均池化将其转换回 s s s列。该体系结构支持堆叠任意数量的卷积-池化块,以提取越来越抽象的特征。底层的输入要素是单词,下一层的输入要素是短语等。每个级别都会生成更高粒度的抽象表示。
(4)输出层
最后一层是输出层,根据任务选择;例如,对于二分类任务,该层是逻辑回归(参见图2)。下面介绍其他类型的输出层。
我们发现,在大多数情况下,如果我们提供所有池化层的输出作为输出层的输入,则性能会提高。对于每个非最终平均池化层,我们如上所述执行 w − a p w-ap w−ap(汇集w列的窗口),但我们同样执行 a l l − a p all-ap all−ap(汇集所有列)并将结果转发到输出层。这提高了模型性能,因为来自不同层的表示覆盖了不同抽象级别的句子属性,并且所有这些级别对于特定句子对都很重要。
4.ABCNN:Attention-Based BCNN
我们现在描述基于BCNN的三种体系结构,ABCNN-1,ABCNN-2和ABCNN-3,它们各自引入了不同的用于句子对建模的注意力机制;见图3。
(1)ABCNN-1
ABCNN-1(图3(a))采用注意力特征矩阵 A A A来影响卷积。注意力特征旨在以与 s 1 − i ( i ∈ 0 , 1 ) s_{1-i}(i∈{0,1}) s1−i(i∈0,1)的单元相关的卷积中更高的 s i s_i si单元加权;我们在这里使用术语“单元”来指代最低级别的单词和网络较高级别的短语。图3(a)显示了红色的两个单位表示特征映射:ABCNN-1的这部分与BCNN中的相同(参见图2)。每列是单位的表示,即最低级别的单词和较高级别的短语。我们首先非正式地描述注意力特征矩阵 A A A(“Conv input”层的中间中部,见图3(a))。通过将左表示特征映射的单元与右表示特征映射的单元匹配来生成A,使得 A A A中的第 i i i行的注意力值表示 s 0 s_0 s0的第 i i i个单元相对于 s 1 s_1 s1的注意力分布,并且注意 A A A中的第 j j j列的值表示 s 1 s_1 s1的第 j j j个单元相对于 s 0 s_0 s0的注意分布。 A A A可以被视为 s 0 ( r e s p . s 1 ) s_0(resp.s_1) s0(resp.s1)在 r o w ( r e s p . c o l ) row(resp.col) row(resp.col)方向上的新特征映射,因为每 r o w ( r e s p . c o l ) row(resp.col) row(resp.col)是 s 0 ( r e s p . s 1 ) s_0(resp.s_1) s0(resp.s1)中单元的新特征向量。因此,将这个新的特征映射与表示特征映射组合并将它们用作卷积运算的输入是有意义的。我们通过将 A A A转换为图3(a)中具有与表示特征映射相同格式的两个蓝色矩阵来实现这一点。因此,卷积的新输入具有每个句子的两个特征映射(以红色和蓝色显示)。我们的动机是注意力特征映射将指导卷积学习“对应偏差”的句子表示。
更正式地,令 F i , r ∈ R d × s F_{i,r}∈R^{d×s} Fi,r∈Rd×s为句子 i ( i ∈ 0 , 1 ) i(i∈{0,1}) i(i∈0,1)的表示特征映射。然后我们将注意矩阵 A ∈ R s × s A∈R^{s×s} A∈Rs×s定义如下:
A i , j = m a t c h − s c o r e ( F 0 , r [ : , i ] , F 1 , r [ : , j ] ) ( 1 ) A_{i,j}=match-score(F_{0,r}[:, i], F_{1,r}[:, j]) \qquad (1) Ai,j=match−score(F0,r[:,i],F1,r[:,j])(1)
打分函数可以以多种方式定义。我们发现 1 / ( 1 + ∣ x − y ∣ ) 1 /(1+| x-y |) 1/(1+∣x−y∣)具有很好的效果,其中 ∣ ⋅ ∣ |·| ∣⋅∣是欧氏距离。
给定注意力矩阵 A A A,我们生成 s i s_i si的注意力特征映射 F i , a F_{i,a} Fi,a,如下所示:
F 0 , a = W 0 ⋅ A ⊤ , F 1 , a = W 1 ⋅ A F_{0,a} = W_0·A^{\top}, F_{1,a} = W_1 · A F0,a=W0⋅A⊤,F1,a=W1⋅A
权重矩阵 W 0 ∈ R d × s W_0∈R^{d×s} W0∈Rd×s, W 1 ∈ R d × s W_1∈R^{d×s} W1∈Rd×s是训练中要学习的模型的参数
我们将表示特征映射 F i , r F_{i,r} Fi,r和注意力特征映射 F i , a F_{i,a} Fi,a作为3维张量堆叠并将其馈送到卷积以生成 s i ( i ∈ 0 , 1 ) s_i(i∈{0,1}) si(i∈0,1)的更高级别表示特征映射。在图3(a)中, s 0 s_0 s0有5个单元, s 1 s_1 s1有7个。卷积的输出(在顶层显示,filter宽度w = 3)是一个更高级别的表示特征映射,其中7列用于 s 0 s_0 s0和9列用于 s 1 s_1 s1。
(2)ABCNN-2
ABCNN-1直接在输入表示上计算注意力权重,目的是改进通过卷积计算的特征。ABCNN-2(图3(b))改为计算卷积层输出的注意力权重,目的是重新加权该卷积层的输出。在图3(b)所示的例子中,通过卷积输出的 s 0 s_0 s0和 s 1 s_1 s1的特征映射(图3(b)中标记为“Convolution”的层)分别具有7列和9列; 每列是一个单元的表示。注意力矩阵 A A A将 s 0 s_0 s0中的所有单元与 s 1 s_1 s1的所有单元进行比较。我们将一个单元的所有注意力值相加,以得出该单元的单个注意力。对于 s 0 s_0 s0,这对应于对 A A A中一行的所有值求和(“col-wise sum”,得到显示的大小为7的列向量),对于 s 1 s_1 s1,则对应于对 A A A中每一列中的所有值求和(“row-wise sum”,得到显示大小为9的行向量)。
更正式地,令 A ∈ R s × s A∈R^{s×s} A∈Rs×s为注意力矩阵, a 0 , j = ∑ A [ j , : ] a_{0,j} =\sum A[j,:] a0,j=∑A[j,:]为 s 0 s_0 s0中的单元 j j j的注意力权重, a 1 , j = ∑ A [ : , j ] a_{1,j} =\sum A[:,j] a1,j=∑A[:,j]为 s 1 s_1 s1中的单元 j j j的注意力权重,并且 F i , r c ∈ R d × ( s i + w − 1 ) F^c_{i,r}∈R^{d×(si + w-1)} Fi,rc∈Rd×(si+w−1)为 s i s_i si的卷积输出。然后由 w − a p w-ap w−ap生成的新特征映射 F i , r p F^p_{i,r} Fi,rp的第 j j j列由以下公式导出:
F i , r p [ : , j ] = ∑ k = j : j + w a i , k F i , r c [ : , k ] , j = 1... s i F^p_{i,r}[:, j]=\sum_{k=j:j+w}a_{i,k}F^c_{i,r}[:, k],\qquad j = 1 . . . s_i Fi,rp[:,j]=k=j:j+w∑ai,kFi,rc[:,k],j=1...si
注意, F i , r p ∈ R d × s i F^p_{i,r}∈R^{d×s_i} Fi,rp∈Rd×si,即ABCNN-2的池化层生成一个与卷积的输入特征映射相同大小的输出特征映射。这允许我们堆叠多个卷积池模块以提取更加抽象的特征。
ABCNN-1和ABCNN-2之间存在三个主要差异。(i)ABCNN-1中的注意力间接影响卷积,而ABCNN-2中的注意力通过直接注意力加权影响池化层。(ii)ABCNN-1要求使用两个矩阵 W i W_i Wi将注意力矩阵转换为注意力特征映射;并且卷积的输入具有两倍的特征映射。因此,ABCNN-1具有比ABCNN-2更多的参数,并且更容易过拟合。(iii)由于池化是在卷积后进行的,因此池化处理比卷积更大的粒度单位;例如,如果卷积的输入具有词级别的粒度,则对池化的输入具有短语级别的粒度,短语大小等于filter的大小 w w w。因此,ABCNN-1和ABCNN-2实现了针对不同粒度级别的语言单元的注意力机制。ABCNN-1和ABCNN-2的互补性促使我们提出ABCNN-3,这是结合两者特性的第三种结构。
(3)ABCNN-3
ABCNN-3(图3©)通过堆叠ABCNN-1和ABCNN-2组合而成;它结合了ABCNN-1和-2的优势,允许注意力机制:(i)同时计算卷积池和池化层部分(ii)同时计算输入粒度和更抽象的输出粒度。