1.網絡總述
計算機經網絡體系結構:
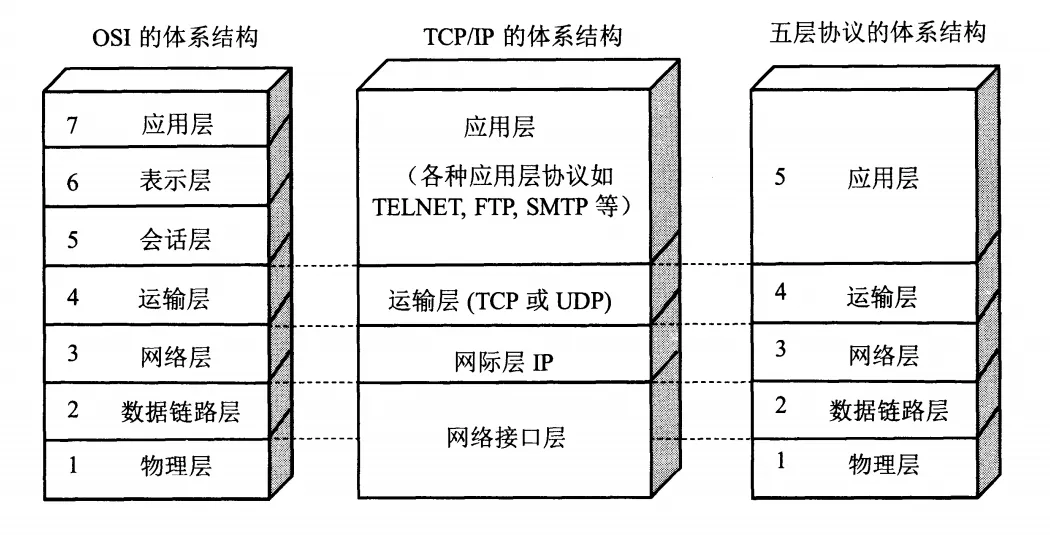
各層作用及協定
| 分層 | 作用 | 協定 |
| 實體層 | 通過媒介傳輸比特,确定機械及電氣規範(比特 Bit) | RJ45、CLOCK、IEEE802.3(中繼器,集線器) |
| 資料鍊路層 | 将比特組裝成幀和點到點的傳遞(幀 Frame) | PPP、FR、HDLC、VLAN、MAC(網橋,交換機) |
| 網絡層 | 負責資料包從源到宿的傳遞和網際互連(包 Packet) | IP、ICMP、ARP、RARP、OSPF、IPX、RIP、IGRP(路由器) |
| 運輸層 | 提供端到端的可靠封包傳遞和錯誤恢複( 段Segment) | TCP、UDP、SPX |
| 會話層 | 建立、管理和終止會話(會話協定資料單元 SPDU) | NFS、SQL、NETBIOS、RPC |
| 表示層 | 對資料進行翻譯、加密和壓縮(表示協定資料單元 PPDU) | JPEG、MPEG、ASII |
| 應用層 | 允許通路OSI環境的手段(應用協定資料單元 APDU) | FTP、DNS、Telnet、SMTP、HTTP、WWW、NFS |
OSI七層模型和TCP/IP四層模型分别是什麼?有什麼差別?
- OSI模型
- 應用層:HTTP、SMTP、SNMP、FTP、Telnet、SSH、NFS
- 表示層:SMB、AFP
- 會話層:SSH、RPC、NetBIOS、ASP、Winsock、BSD sockets
- 傳輸層:TCP、UDP、
- 網絡層:IP、ICMP、IGMP、BGP、OSPF、RIP、ARP、RARP
- 資料鍊路層:以太網、PPP
- 實體層:線路、無線電、光纖
- TCP/IP協定棧模型
- 應用層(OSI5到7層):網絡應用程式及它們的應用層協定存留的地方
- 傳輸層(OSI4層):在應用程式端點之間傳送應用層封包(端對端)
- 網絡層(OSI3層):将資料報從一台主機移動到另一台主機(主機對主機)
- 接口層(OSI1和2層):通過源和目的地之間的一系列路由器路由資料報(裝置對裝置)
- 兩種模型的差別
-
OSI
強調提供很可靠的的資料傳輸服務,每一層都要進行檢測和處理錯誤。
- TCP/IP認為可靠要由端對端來保證,不要把系統搞得太複雜。傳輸層利用檢驗和、确認分組、重傳、序号和定時器等手段來保證可靠性控制。
2.應用層
2.1 應用程式體系結構
- 客戶機/伺服器(C/S)體系結構
- P2P 體系結構
2.2 網際網路傳輸服務
當建立一個新的網際網路應用時,首先要做出的決定是選擇 UDP 還是 TCP,它們能為應用程式提供下列服務:
• TCP
面向連接配接的服務
可靠資料傳輸服務 • UDP
無連接配接的服務
不可靠資料傳輸服務(不保證到達,也不保證有序到達) 除此之外, TCP 具有擁塞控制機制,擁塞控制不一定能為應用程式帶來直接好處,但能對整個網絡帶來好處。UDP 沒有擁塞控制。
2.3 應用層協定
2.3.1 HTTP
- HTTP(HyperText Transfer Protocol,超文本傳輸協定)是用于從 WWW(World Wide Web,網際網路)伺服器傳輸超文本到本地浏覽器的傳送協定。HTTP 是網際網路的資料通信的基礎。
使用 TCP 作為運輸層協定
無狀态協定:伺服器向客戶機發送被請求的檔案時,并不存儲任何關于該客戶機的狀态資訊。假如某個特定
的客戶機在短短的幾秒鐘内兩次請求同一個對象,伺服器并不會因為剛剛為該使用者提供了該對象就不再做出反
應,而是重新發送該對象。
• HTTP 客戶機: web 浏覽器
• HTTP 伺服器: web 伺服器,包含 web 對象(HTML 檔案、 JPEG 檔案、 java 小程式、視訊片段等)
連接配接類型:
• 非持久連接配接:每個請求/響應對是經一個單獨的 TCP 連接配接發送
• 持久連接配接:所有請求/響應對使用同一個 TCP 連接配接發送
如果使用非持久連接配接,将 TCP 握手第三步與一個 HTTP 請求封包結合起來發送,伺服器接收請求後響應一個
對象。是以,傳輸一個對象消耗 2 個 RTT。(可以同時建立多個連接配接并行傳輸)但是,由于 TCP 連接配接會配置設定
緩沖區和變量,大量使用非持久連接配接會給伺服器造成壓力
如果使用持久連接配接,則客戶機接收到請求對象後伺服器不會發送一個 TCP 連接配接關閉請求。這個連接配接服務于所
有 web 對象的傳輸(流水線發送),如果經過一個時間間隔仍未被使用,則 HTTP 伺服器關閉連接配接
• http1.0 使用非持久連接配接
• http1.1 使用持久連接配接
1) HTTP 封包格式(請求封包)
- 請求行
- 請求方式
- GET POST PUT HEAD DELETE
- 請求資源路徑
- HTTP協定版本
- HTTP/1.1與HTTP/1.0的差別:
- 長連接配接:HTTP/1.1預設使用長連接配接
- 帶寬優化:HTTP/1.1中在請求消息中新引入了用于帶寬優化的頭域
-
range頭域與Content-Range頭域:請求消息中如果包含比較大的實體内容,但不确定伺服器是否能夠接收該請求,它允許隻請求資源的某個部分。在響應消息中Content-Range頭域聲明了傳回的這部分對象的偏移值和長度。
響應100則繼續發送整體,響應401則停止發送。
- Accept-Encoding頭域與Content-Encoding頭域:對消息進行端到端的編碼。
- 錯誤提示:
-
HTTP1.1增加了OPTIONS, PUT, DELETE, TRACE,
CONNECT這些Request方法。
- HTTP/1.1引入了一個Warning頭域,增加對錯誤或警告資訊的描述。
- 在HTTP/1.1中新增了24個狀态響應碼,如409(Conflict)表示請求的資源與資源的目前狀态發生沖突;410(Gone)表示伺服器上的某個資源被永久性的删除。
- 請求頭(首部行)
- Host:(1.1引入)請求的目标主機
- If-Modified-Since:如果請求封包中包含此字段,則為條件GET請求封包,用于緩存(響應封包304代碼表示緩存未修改)
- Referer:檢測來源,防盜鍊
- User-Agent:使用者代理,即向伺服器發送請求的浏覽器的類型(伺服器可以正确地為不同類型的使用者代理發送相同對象的不同版本)
- Cookie:在無狀态的HTTP之上建立一個使用者會話層
- Cache-Control:緩存相關
- Connection:
- 短連接配接:每個TCP連接配接隻傳輸一個請求封包和一個響應封包
- 給web伺服器帶來嚴重的負擔(高并發短連接配接,TIME_WAIT)
- 安全性好
- 長連接配接:所有的請求響應經相同的的TCP連接配接發送
- HTTP1.1的預設模式是使用帶流水線的持續連接配接
- 在一個TCP連接配接内,多個HTTP請求可以并行,下一個HTTP請求在上一個HTTP請求的應答完成之前就發起
- 節約資源
- Range:允許隻擷取檔案部分内容
- 實體内容
- GET封包:
- 通過URL參數傳遞的方式送出資料
- 通過"?"區分資源路徑和送出的資料
- 參數間用&分隔
- 長度受限
- 安全性低
- POST封包:
- 表單送出
- 長度不受限制
- 不被緩存,安全性高
“Connection:close”:浏覽器告訴伺服器不希望使用持久連接配接,而是要求伺服器在發送完請求後關閉連接配接
“Accept-language”:使用者想得到該對象的文法版本計算機網絡
方法字段:
• GET:絕大部分 HTTP 請求封包使用 GET 方法
• POST:使用者送出表單時(如向搜尋引擎提供關鍵字),但送出表單不一定要用 POST 方法
• HEAD:類似于 GET,差別在于伺服器傳回的響應封包中不包含請求對象(常用于故障跟蹤)
• PUT:用于向伺服器上傳對象
• DELETE:用于删除伺服器上的對象
【注】GET 與 POST 的差別與聯系
2) HTTP 封包格式(響應封包)
- 響應狀态行
- 協定版本
- 狀态碼
- 200 OK:請求成功,資訊包含在傳回的響應封包中
- 301 Moved Permanently:請求的對象已經被永久轉移了,新的 URL 定義在響應封包的 Location 首部中。客戶機軟體自動用新的 URL 擷取對象
- 302:找到
- 304:Not Modified:條件 GET 的響應封包中的狀态碼, web 伺服器告訴 web 緩存相應對象未被修改(If-Modified-Since,Last-Modified,緩存,條件GET)
- 400 Bad Request:請求不能被伺服器了解
- 401:未經授權
- 403 Forbidden:伺服器收到請求,但是拒絕提供服務。伺服器通常會在響應封包中給出不提供服務的原因
- 404 Not Found:被請求的文檔不在伺服器上
- 500:伺服器錯誤
- 502:無效網關
- 504:網關逾時
- 505 HTTP Version Not Supported:伺服器不支援請求封包使用的 HTTP 協定版本
- 描述資訊
- 響應頭
- Server
- Date:封包生成、發送時的日期
- Expires:控制緩存過期時間
- Location
- Accept-Ranges
- Content-*
- Last-Modified: web 對象最後修改的日期
- ETag:最後緩存時間和檔案大小的哈希
- Expires:在某時間前,直接使用,不必請求
- Cache-Control:在某時間内,直接使用,不必請求
- Transfer-Encoding
- Set-Cookie
- Connection
- 實體内容
- MIME類型:大類别/具體類型
“Connection:close”:告訴客戶機在封包發送完後關閉了 TCP 連接配接
Telnet: HTTP 響應封包檢視工具
3) cookie>
用于識别使用者,可能出于下列意圖:
• 伺服器想限制使用者的通路
• 伺服器想把内容與使用者身份關聯起來
cookie 包含 4 個組成部分:
- 在 HTTP 響應封包中有一個 Set-cookie 首部行
- 在 HTTP 請求封包中有一個 Cookie 首部行
- 在使用者端系統中保留有一個 cookie 檔案,由使用者的浏覽器管理
- 在 web 站點有一個後端資料庫
4) web 緩存>
web 緩存器也叫代理伺服器,用于緩存 web 對象。使用者可以配置其浏覽器,使得所有 HTTP 請求首先指向web 緩存器。
如果 web 緩存器沒有請求的對象,會與初始伺服器直接建立一條 TCP 連接配接, web 緩存器進一步發送 HTTP 請
求,擷取對象,當接收到對象後,首先在本地緩存,然後生成一個 HTTP 響應封包,發送給客戶機(是以,web 緩存器既是客戶機,又是伺服器)。
web 緩存器類似于記憶體與處理器之間的 cache,它能從整體上大大降低網際網路上的 web 流量,進而改善所有應用的性能。
條件 GET: web 緩存器使用條件 GET 向 web 伺服器确認某個對象是否已經被修改(不是最新的對象)。如果
1)請求封包使用 GET 方法;
2)并且包含一個 If-modified-since:首部行,那麼這個 HTTP 請求封包就是一個條件 GET計算機網絡。如果相應對象未被修改, web 伺服器傳回一個實體為空的響應封包(也就是說并沒有包含請求對象),狀态碼為
“304 Not Modified
請求方法
| 方法 | 意義 |
| OPTIONS | 請求一些選項資訊,允許用戶端檢視伺服器的性能 |
| GET | 請求指定的頁面資訊,并傳回實體主體 |
| HEAD | 類似于 get 請求,隻不過傳回的響應中沒有具體的内容,用于擷取報頭 |
| POST | 向指定資源送出資料進行處理請求(例如送出表單或者上傳檔案)。資料被包含在請求體中。POST請求可能會導緻新的資源的建立和/或已有資源的修改 |
| PUT | 從用戶端向伺服器傳送的資料取代指定的文檔的内容 |
| DELETE | 請求伺服器删除指定的頁面 |
| TRACE | 回顯伺服器收到的請求,主要用于測試或診斷 |
狀态碼(Status-Code)
- 1xx:表示通知資訊,如請求收到了或正在進行處理
- 100 Continue:繼續,用戶端應繼續其請求
- 101 Switching Protocols 切換協定。伺服器根據用戶端的請求切換協定。隻能切換到更進階的協定,例如,切換到 HTTP 的新版本協定
- 2xx:表示成功,如接收或知道了
- 200 OK: 請求成功
- 3xx:表示重定向,如要完成請求還必須采取進一步的行動
- 301 Moved Permanently: 永久移動。請求的資源已被永久的移動到新 URL,傳回資訊會包括新的 URL,浏覽器會自動定向到新 URL。今後任何新的請求都應使用新的 URL 代替
- 4xx:表示客戶的差錯,如請求中有錯誤的文法或不能完成
- 400 Bad Request: 用戶端請求的文法錯誤,伺服器無法了解
- 401 Unauthorized: 請求要求使用者的身份認證
- 403 Forbidden: 伺服器了解請求用戶端的請求,但是拒絕執行此請求(權限不夠)
- 404 Not Found: 伺服器無法根據用戶端的請求找到資源(網頁)。通過此代碼,網站設計人員可設定 “您所請求的資源無法找到” 的個性頁面
- 408 Request Timeout: 伺服器等待用戶端發送的請求時間過長,逾時
- 5xx:表示伺服器的差錯,如伺服器失效無法完成請求
- 500 Internal Server Error: 伺服器内部錯誤,無法完成請求
- 503 Service Unavailable: 由于超載或系統維護,伺服器暫時的無法處理用戶端的請求。延時的長度可包含在伺服器的 Retry-After 頭資訊中
- 504 Gateway Timeout: 充當網關或代理的伺服器,未及時從遠端伺服器擷取請求
更多狀态碼:菜鳥教程 . HTTP狀态碼
HTTPS與HTTP協定的差別
- https協定需要到ca申請證書,一般免費證書較少,因而需要一定費用。
- http是超文本傳輸協定,資訊是明文傳輸,https則是具有安全性的ssl加密傳輸協定。
- http和https使用的是完全不同的連接配接方式,用的端口也不一樣,前者是80,後者是443。
- http的連接配接很簡單,是無狀态的;HTTPS協定是由SSL+HTTP協定建構的可進行加密傳輸、身份認證的網絡協定,比http協定安全。
SSL、TSL的加密方式是什麼?為什麼https理論上時間更長,現在怎麼優化的?
- 伺服器端檢查會話辨別是否在自己的緩存中
- 描述在浏覽器的位址欄鍵入www.baidu.com後發生了哪些事情?
- DHCP
- 擷取IP位址,網關位址,DNS伺服器位址
- DNS解析
- 從URL中抽取主機名,并将主機名傳給DNS應用的用戶端
- DNS查詢封包被封裝到目的位址為DNS伺服器的IP資料報中,通過ARP協定擷取網關路由器的MAC位址
- DNS客戶向DNS伺服器發送包含主機名的請求
- 經過一系列的遞歸查詢或疊代查詢,DNS客戶最終會收到一份回答封包,其中含有主機名對應的IP位址(有CDN和沒有CDN的情況不同,要分别說明,後面CDN部分會針對此做詳細說明)
- 建立連接配接
- TCP三向交握
- 使用者可以找到和打開socket檔案
- 發起請求
- 浏覽器運用socket檔案向伺服器發起各種請求
- 發送HTTP GET封包
- 應答請求
- 運用HTTP協定把請求傳輸到伺服器
- 任務處理
- 運用HTTP協把處理結果或請求的資源傳輸到浏覽器(響應封包)
- 關閉連接配接
2.3.2 SMTP
- SMTP(Simple Mail Transfer Protocol,簡單郵件傳輸協定)是一組用于由源位址到目的位址傳送郵件的規則,由它來控制信件的中轉方式。SMTP 協定屬于 TCP/IP 協定簇,它幫助每台計算機在發送或中轉信件時找到下一個目的地。是一個相對簡單的基于文本的協定。在其之上指定了一條消息的一個或多個接收者(在大多數情況下被确認是存在的),然後消息文本會被傳輸。可以很簡單地通過 Telnet 程式來測試一個 SMTP 伺服器。SMTP 使用 TCP 端口 25。
電子郵件系統有 3 個主要組成部分: 使用者代理、郵件伺服器、簡單郵件傳輸協定(SMTP)
• 每個使用者在郵件伺服器上有一個郵箱,儲存該使用者發送和接收的郵件
• 如果郵件未發送成功,會儲存在郵件伺服器上,通常 30 分鐘左右再進行嘗試,幾天後仍不成功則删除,并以郵件形式通知發送方
• SMTP 傳輸郵件之前,需要将封包主體編碼為 ASCII 碼,傳輸後需要解碼(HTTP 傳輸不需要)
• SMTP 一般不使用中間郵件伺服器發送郵件,即使兩個郵件伺服器位于地球的兩端
• SMTP 會把郵件中所有對象封裝在一個封包中,而 HTTP 則是每個封包封裝一個 web 對象
1)多用途網際網路郵件擴充(MIME)
普通的郵件封包主體為 ASCII 編碼的資料,封包首部适合于發送普通的 ASCII 文本,但是不能充分滿足多媒體
封包或攜帶非 ASCII 文本格式(非英文字元)的封包需求。需要額外的首部行提供對發送這些檔案的支援
MIME 中包含 2 個支援發送上述檔案的首部:
• Content-Transfer-Encoding:指出所用編碼類型,接收方可以根據這個字段還原
• Content-Type:檔案類型,接收方可以根據這個首部采取一些适當動作(如解壓)
2)接收方郵件拉取>
SMTP 是一個”推協定“,不能用于接收方代理從郵件伺服器上拉取郵件,拉取郵件需要使用 POP3(第三版的郵
局協定)、 IMAP(網際網路郵件通路協定)或 HTTP
POP3(第三版的郵局協定):當使用者打開一個到郵件伺服器端口 110 上的 TCP 連接配接後, POP3 就開始工作了,
包含 3 個階段
• 特許:使用者發送使用者名和密碼鑒别身份
• 事務處理:使用者代理取回封包(還能标記封包、擷取郵件統計資訊)
• 更新:客戶機發出了 quit 指令後,結束了 POP3 會話,郵件伺服器會删除被标記為删除的封包
使用 POP3 拉取時,可以設定為”拉取并删除“或”拉取并保留“
IMAP(網際網路郵件通路協定): POP3 不能提供遠端檔案夾功能, IMAP 可以, IMAP 伺服器把每個封包與一個
檔案夾聯系起來, IMAP 為使用者提供了建立檔案夾以及在檔案夾之間移動郵件的指令。除此之外,還提供在遠
程檔案夾中查詢郵件、按指定條件查詢比對檔案的指令。與 POP3 不同, IMAP 伺服器維護了 IMAP 會話的用
戶狀态資訊
基于 web 的電子郵件:當使用 web 浏覽器發送接收郵件時,推送到郵件伺服器和從郵件伺服器拉取郵件使用的是 HTTP 協定。
【注】SMTP和HTTP協定的差別
- SMTP是個推協定,HTTP是個拉協定,是以使用者從自己的郵件伺服器上收取封包時,需要使用POP3(110)、IMAP()以及HTTP協定
- POP3協定沒有給使用者提供任何建立遠端檔案夾并為封包指派檔案夾的方法,不維護使用者狀态資訊
- IMAP解決以上問題
- SMTP要求每個封包用7比特ASCII碼格式
- SMTP把所有封包對象放在一個封包中
2.3.3 DNS
- DNS(Domain Name System,域名系統)是網際網路的一項服務。它作為将域名和 IP 位址互相映射的一個分布式資料庫,能夠使人更友善地通路網際網路。DNS 使用 TCP 和 UDP 端口 53。目前,對于每一級域名長度的限制是 63 個字元,域名總長度則不能超過 253 個字元。
域名:
-
域名 ::= {<三級域名>.<二級域名>.<頂級域名>}
DNS運作于UDP之上,使用53号端口,它提供下列服務:
- 主機名到IP位址的轉換(主要)。
- 主機名稱:有着複雜主機名的主機可以擁有一個或多個别名,應用程式可以調用DNS來獲得主機名稱對應的規範主機名以及主機的IP位址
- 郵件伺服器别名:qq.com與foxmail.com,DNS可以解析郵件伺服器别名獲得規範名和IP位址
- 負載配置設定:繁忙的站點被備援分布在多台伺服器上,這些伺服器有不同IP位址,IP位址集合對應于一個規範主機名,當客戶機通過主機名擷取IP位址時,DNS伺服器用包含全部這些位址的封包進行回答,但在每個回答中選擇這些位址排放的順序,進而将負載配置設定到不同伺服器
1)DNS伺服器
集中設計(單一DNS伺服器)具有下列問題:
- 單點故障
- 通信容量:單個DNS伺服器承受所有查詢負載
- 遠距離的集中式資料庫:單個DNS伺服器不可能”鄰近“所有查詢客戶機
是以DNS伺服器使用分布式設計方案:
- 根DNS伺服器:網際網路上有13個根DNS伺服器(标号A到M),大部分位于北美洲
- 頂級域(TLD)DNS伺服器
- 權威DNS伺服器
除此之外,DNS伺服器還有本地DNS伺服器。嚴格來說,本地DNS伺服器不屬于DNS伺服器的層次結構,但對DNS層次結構很重要。一台主機具有一台或多台本地DNS伺服器的IP位址,本地DNS伺服器起着代理的作用,将請求轉發到DNS伺服器層次結構中。
2)DNS查詢步驟
DNS緩存:在查詢鍊中,當一個DNS伺服器接收到一個DNS回答時,DNS伺服器能将回答中的資訊緩存在本地存儲,以便加速後序可能的相同查詢。由于主機IP和主機名之間的映射不是永久的,DNS伺服器會在一段時間後丢棄緩存(本地DNS伺服器可以緩存TLD伺服器的IP位址,因而允許直接繞過查詢鍊中的根DNS伺服器)。
3)DNS記錄和封包
所有DNS伺服器共同存儲着資源記錄,資源記錄格式如下:
(Name,Value,Type,TTL)
- Type=A:此時Name是主機名,Value是對應IP位址
- Type=NS:Name是域(如foo.com),Value是知道如何擷取該域中主機IP位址的權威DNS伺服器的主機名
- Type=CNAME:Value是别名為Name的主機對應的規範主機名
- Type=MX:Value是别名為Name的郵件伺服器的規範主機名
如果一台DNS伺服器是某個特定主機名的權威DNS伺服器,那麼會有一條包含該主機名的類型A記錄(不是權威伺服器,也可能在緩存中包含A記錄)
如果DNS伺服器不是某個主機名的權威DNS伺服器,那麼會包含一條類型NS記錄,還将包含一條類型A記錄,提供了在NS記錄的Value字段中DNS伺服器的IP位址
DNS封包(查詢和響應封包格式相同)
nslookup:從主機直接向某些DNS伺服器發送DNS查詢封包
注冊域名
網際網路名字和位址配置設定機構(ICANN)向各種注冊登記機構授權,可以向這些機構申請注冊域名:
- 提供基本權威DNS伺服器和輔助權威伺服器的域名和IP
- 注冊登記機構會将NS和A類型的記錄輸入TLD伺服器
- 確定自身在提供的權威DNS伺服器中輸入了相應類型的記錄
4) DDos帶寬洪泛攻擊
如,攻擊者向每個DNS根伺服器連續不斷地發送大量的分組,進而使得大多數合法的DNS請求得不到回答
DNS根伺服器配置分組過濾器可以攔截這些分組,本地DNS伺服器緩存了頂級域名伺服器的IP位址,也能繞過DNS根伺服器,防止攻擊
【QA】
1.為什麼要DNS解析,DNS是什麼?
- 人類喜歡便于記憶的主機名辨別方式,路由器定長的有層次地IP位址。
- DNS是一個由分層的DNS伺服器實作的分布式資料庫,一個使得主機能夠查詢分布式資料庫的應用層協定。
2.DNS的解析過程,涉及到的檔案以及其記錄類型
- 遞歸查詢:本地、根、二級…本地
- 疊代查詢:本地、根伺服器、本地、二級、本地…本地
- 通常來說請求主機到本地DNS伺服器的查詢是遞歸的,其餘的查詢是疊代的
- 記錄類型
- CNAME:主機名稱比規範主機名更容易記憶,一個IP給許多主機用,隻修改CNAME對應的A記錄即可,CDN,主機名稱,規範主機名,CNAME
- A:主機名,IP,A(權威伺服器有)
- MX:郵件伺服器别名,規範主機名,MX
- NS:域,能擷取該域的主機IP位址的權威DNS伺服器的主機名,NS(非權威伺服器)
3.如果DNS解析出現錯誤,解決的思路是什麼?
- 本地緩存被污染
- 本地DNS伺服器被污染
- 中間人攻擊
- 牆
4.Anycast 的使用場景
- 大型DNS系統中廣泛使用的多點部署、分布式方案,對于提高可用性、提高性能、抵抗DDOS有重要作用。
=5.CDN(内容分發網絡) 技術
- CDN中涉及到的關鍵技術:
- 緩存算法[Squid]:緩存算法決定命中率、源伺服器壓力、POP節點存儲能力
- 分發能力:分發能力取決于IDC能力和IDC政策性分布
- 負載均衡[Nginx]:負載均衡(智能排程)決定最佳路由、響應時間、可用性、服務品質
-
基于DNS[BIND]:基于DNS的負載均衡以CNAME實作[to
cluster],智取最優節點服務
- 為什麼要有CNAME而不是直接傳回一個CDN邊緣節點的ip?
- 由于CDN對域名解析過程進行了調整,是以解析函數庫得到的是該域名對應的CNAME記錄(CNAME為CDN服務商域名),為了得到實際IP位址,浏覽器需要再次對獲得的CNAME域名進行解析以得到實際的IP位址;
- 在此過程中,使用的全局負載均衡DNS解析,如根據地理位置資訊解析對應的IP位址,使得使用者能就近通路。
- 支援協定:靜動态加速(圖檔加速、https帶證書加速)、下載下傳加速、流媒體加速、企業應用加速、手機應用加速
- CDN系統的通用組成架構
-
分發服務系統:最基本的工作單元就是Cache裝置,cache(邊緣cache)負責直接響應最終使用者的通路請求,把緩存在本地的内容快速地提供給使用者。同時cache還負責與源站點進行内容同步,把更新的内容以及本地沒有的内容從源站點擷取并儲存在本地。Cache裝置的數量、規模、總服務能力是衡
量一個CDN系統服務能力的最基本的名額
- 負載均衡系統:主要功能是負責對所有發起服務請求的使用者進行通路排程,确定提供給使用者的最終實際通路位址。兩級排程體系分為全局負載均衡(GSLB)和本地負載均衡(SLB)。GSLB主要根據使用者就近性原則,通過對每個服務節點進行"最優"判斷,确定向使用者提供服務的cache的實體位置。SLB主要負責節點内部的裝置負載均衡
- 營運管理系統:分為營運管理和網絡管理子系統,負責處理業務層面的與外界系統互動所必須的收集、整理、傳遞工作,包含客戶管理、産品管理、計費管理、統計分析等功能。
- 在解析過程中,企業的CDN是怎麼起作用的(在解析過程中,如何把請求打到CDN節點上)?
- 使用了CDN緩存後,針對網站的通路過程變為:
- 本地DNS伺服器在進行查詢的時候,将該DNS請求中繼到該域名的權威伺服器。權威伺服器通過分析二級域名,如video.baidu.com,不直接傳回IP位址,而是傳回一個對應的CNAME記錄,該記錄指向公司CDN的DNS權威伺服器。
- 使用者的本地伺服器對獲得的CNAME域名進行解析,向CDN的DNS權威伺服器發起請求。
- 權威伺服器通過在IP庫中查詢請求IP的地理位置(淘寶使用包裹記錄來校準),同時考慮網絡成本,流量分布,源站負載等,傳回一個最優節點緩存伺服器的IP。
- 緩存伺服器根據浏覽器提供的要通路的域名,通過Cache内部專用DNS解析得到此域名的實際IP位址,再由緩存伺服器向此實際IP位址送出通路請求。
- 緩存伺服器從實際IP位址得得到内容以後,一方面在本地進行儲存,以備以後使用,二方面把擷取的資料傳回給用戶端,完成資料服務過程。
2.3.4 DHCP
DHCP(Dynamic Host Configuration Protocol,動态主機設定協定)是一個區域網路的網絡協定,使用 UDP 協定工作,主要有兩個用途:
- 用于内部網絡或網絡服務供應商自動配置設定 IP 位址給使用者
- 用于内部網絡管理者作為對所有電腦作中央管理的手段
擷取IP位址,掩碼,路由器IP位址,DNS伺服器的IP位址
- 實作原理
- 發現:新到主機通過DHCP發現封包,在UDP分組中向端口67發送,使用廣播目的位址255.255.255.255,源位址0.0.0.0
- 提供:DHCP伺服器通過廣播位址能提供的IP資訊(位址、掩碼、租用期)
- 請求:新到主機從提供封包中選中一個伺服器,并響應一個DHCP請求封包,回顯配置參數
- ACK:伺服器用DHCP ACK封包證明所要求的參數
2.3.5 FTP
- FTP(File Transfer Protocol,檔案傳輸協定)是用于在網絡上進行檔案傳輸的一套标準協定,使用客戶/伺服器模式,使用 TCP 資料報,提供互動式通路,雙向傳輸。
- TFTP(Trivial File Transfer Protocol,簡單檔案傳輸協定)一個小且易實作的檔案傳輸協定,也使用客戶-伺服器方式,使用UDP資料報,隻支援檔案傳輸而不支援互動,沒有列目錄,不能對使用者進行身份鑒定。
FTP 使用兩個并行的 TCP 連接配接來傳輸檔案:
- 控制連接配接(持久):傳輸控制資訊,如使用者辨別、密碼、改變遠端目錄指令、檔案擷取上傳的指令
- 資料連接配接(非持久):傳輸實際檔案
FTP 客戶機發起向 FTP 伺服器的控制連接配接,然後在該連接配接上發送使用者辨別和密碼、改變遠端目錄指令。 FTP伺服器收到指令後,發起一個到客戶機的資料連接配接,在該連接配接上準确地傳送一個檔案并關閉連接配接。
有狀态的協定: FTP 伺服器在整個會話期間保留使用者的狀态資訊。伺服器必須把特定的使用者賬号和控制連接配接聯系起來
- 控制連接配接:長連接配接
- 以7比特ASCII格式傳輸
- 資料連接配接:短連接配接
- 使用者身份
- 實體使用者
- 訪客
- 匿名使用者
- 主動連接配接
- 防火牆(NAT)問題:使用iptables的ftp子產品
- 用戶端先發起,告知自己的端口号,連接配接到伺服器21端口,伺服器20端口主動連接配接用戶端
- 被動連接配接
- 用戶端發送被動連接配接辨別,伺服器21端口号告訴用戶端自己使用的資料端口,用戶端随即選用大于1024的端口主動連接配接伺服器,
- 安全性
- vsftpd
- 明文傳輸不安全
- chroot,限定使用者的通路目錄
2.3.6 SMB
- rpc
- showmount
- 防火牆設定:/etc/sysconfig/nfs:設定端口
- 權限:網段
- NFS
- ftp無法直接修改主機上的檔案資料,需要用戶端
- 共享列印機
- 架構在NetBIOS協定上,适合區域網路的共享
- 每台主機有NetBIOS Name
- 權限
- nmbd:管理工作組名稱的解析,使用UDP實作137 138端口
- smbd:管理主機共享的目錄檔案與列印機,利用TCP的139 445
- /etc/samba/smb.conf
- 賬号密碼放在TDB資料庫中user
- 在Linux下,必須是Linux的使用者,密碼可以不同
- 也可以使用外部伺服器的密碼domain
- NIS或LDAP來進行賬号對應
- PDC伺服器
- 讓PDC成為整個區域網路的域管理者,win主機加入域中,win登陸時會從伺服器驗證賬号密碼
- selinux、iptables、hosts allow|deny、
- 挂載
- monut -t cifs
2.3.7 P2P應用
不同于C/S架構,P2P架構中,每個主機既是客戶機也是伺服器,稱作對等方,由于檔案分布存儲在多個對等方中,是以檔案分發速度更快
• u:上傳速率
• d:下載下傳速率
• F:檔案(比特)大小
假設伺服器需要将檔案發送到N個對等方:
1)如果使用C/S架構
• 伺服器總共需要上傳NF比特資料,那麼至少需要NF/us的時間
• 設dmin為下載下傳速率最小的對等方,那麼該對等方不可能在F/dmin内獲得檔案
那麼有:Dcs ≥ max{NF/us,F/dmin},伺服器排程傳輸可使下屆作為實際分發時間,即:Dcs = max{NF/us,F/dmin}。當N足夠大時,分發時間取決于NF/us,随對等方數量線性增加
2) 如果使用P2P架構:
• 剛開始隻有伺服器擁有檔案,為了将檔案的所有比特傳至網絡,需要F/us
• 設dmin為下載下傳速率最小的對等方,那麼該對等方不可能在F/dmin内獲得檔案
• 設utotal = us + u1 + … + un表示系統總上傳速率。由于最終每個對等方會有一個檔案,那麼總共需要上傳NF
比特,那麼所有資料的上傳時間不可能小于NF/utotal
是以又:Dp2p ≥ max{F/us,F/dmin,NF/utotal},如果每個對等方接收到一個比特就重新分發一個比特,可使下屆作為實際分發時間,即:Dp2p = max{F/us,F/dmin,NF/utotal}。實際上,重新分發的是檔案塊而不是一個個比特
下圖展示了在兩種架構下分發時間與對等方數量的關系,可以看出使用P2P進行檔案分發速度快,具有自我擴充性:
P2P中檔案的搜尋方式
• 集中式索引:使用一個集中式索引伺服器存儲索引,是一種P2P和C/S混合的體系結構,檔案分發是P2P的,搜尋是C/S的
• 查詢洪泛:建立在Gnutella協定基礎上,索引全面分布在對等方區域中,對等方向相鄰對等方發出檔案查詢請求,相鄰對等方進一步轉發查詢請求
• 層次覆寫:結合以上兩種,與網際網路高速連接配接并具有高可用性的對等方被指派為超級對等方,新的對等方與超級對等方之一建立TCP連接配接,将其可供共享的所有檔案告訴超級對等方,超級對等方維護着一個索引,超級對等方之間通過TCP連接配接,可以轉發查詢。
2.3.8 TELNET
- TELNET 協定是 TCP/IP 協定族中的一員,是 Internet 遠端登陸服務的标準協定和主要方式。它為使用者提供了在本地計算機上完成遠端主機工作的能力。
2.3.9 WWW
- WWW(World Wide Web,環球資訊網,網際網路)是一個由許多互相連結的超文本組成的系統,通過網際網路通路。
2.3.10 SNMP
- SNMP(Simple Network Management Protocol,簡單網絡管理協定)構成了網際網路工程工作小組(IETF,Internet Engineering Task Force)定義的 Internet 協定族的一部分。該協定能夠支援網絡管理系統,用以監測連接配接到網絡上的裝置是否有任何引起管理上關注的情況。
2.3.11 URL
- URL(Uniform Resource Locator,統一資源定位符)是網際網路上标準的資源的位址(Address)
标準格式:
-
協定類型:[//伺服器位址[:端口号]][/資源層級UNIX檔案路徑]檔案名[?查詢][#片段ID]
完整格式:
-
協定類型:[//[通路資源需要的憑證資訊@]伺服器位址[:端口号]][/資源層級UNIX檔案路徑]檔案名[?查詢][#片段ID]
其中【通路憑證資訊@;:端口号;?查詢;#片段ID】都屬于選填項
3.傳輸層
3.1端口号與套接字
3.3.1 端口号
通常在一台主機上能夠運作許多網絡應用程式。IP位址可以辨別一台主機,端口号則是用來辨別這台主機上的特定程序。
端口号是一個16bit的數字,大小在0 ~ 65535之間,0 ~ 1023範圍的端口号稱為周知端口号,保留給周知的應用層協定。
| 應用層協定 | 端口号 | 傳輸層協定 |
| DNS | 53 | UDP |
| FTP | 21(控制連接配接),20(資料連接配接) | TCP |
| TFTP | 69 | UDP |
| TELNET | 23 | TCP |
| DHCP | 67(伺服器),68(用戶端) | UDP |
| HTTP | 80 | TCP |
| HTTPS | 443 | TCP |
| SMTP | 25 | TCP |
| POP3 | 110 | TCP |
| IMAP | 143 | TCP |
3.3.2 套接字
網絡應用由成對程序組成,程序通過一個稱為套接字的軟體接口在網絡上發生和接收封包
套接字是同一台主機内應用層與運輸層之間的接口,也可稱為應用程式和網絡之間的應用程式程式設計接口
TCP套接字:(源IP,源端口,目的IP,目的端口)
UDP套接字:(目的IP,目的端口)
3.2多路複用與多路分解
• 多路分解:将運輸層封包段中的資料傳遞到正确的套接字的過程(通過封包段的端口号字段)
• 多路複用:從源主機不同套接字收集資料,并為資料封裝上首部資訊進而生成封包段,傳遞到網絡的過程
3.3可靠資料傳輸原理
- rdt:可靠資料傳輸
- udt:不可靠資料傳輸
3.3.1完全可靠信道上的可靠資料傳輸(rdt1.0)
假設底層信道是完全可靠的
3.3.2具有比特差錯信道上的可靠資料傳輸(rdt2.0、rdt2.1、rdt2.2)
更現實的底層信道模型是分組中的比特可能受損
引入了自動重傳請求(ARQ)協定,ARQ還需要另外3種協定來處理存在的比特差錯:
- 差錯檢測
- 接收方回報:肯定确認(ACK)和否定确認(NAK)
- 重傳:接收方收到有差錯的分組時,發送方重傳
對于發送方,在等待ACK或NAK狀态時,不能發送更多分組。類似于rdt2.0這種行為的協定被稱為停等協定rdt2.0的問題在于沒有考慮到ACK和NAK分組可能受損的情況
處理受損ACK或NAK的辦法是,如果收到受損的ACK或NAK,則重傳一次分組,但是這樣又無法确認是一次新的分組還是重傳的分組。解決辦法是在分組中添加一個序号字段,接收方隻需檢查序号即可确定收到的分組是否是一次重傳。對于rdt2.0,隻需1比特序号即可,進而得到rdt2.1
如果收到受損的分組,接收方也可以發送一個對上次正确接收分組的ACK,也能實作與NAK一樣的效果,也就是rdt2.2
3.3.3 具有比特差錯的丢包信道上的可靠資料傳輸(rdt3.0)
現在假定除了比特受損外,底層信道還會丢包,是以需要引入時間機制決定何時重傳分組
3.3.4 流水線可靠資料傳輸
rdt3.0功能正确,但由于是一個停等協定,是以性能很差。如果能在收到确認之前發送多個分組,可以大大提升性能
1)回退N步(GBN)
也被稱為滑動視窗協定
- 發送方
逾時重傳所有已發送但未确認的分組
- 接收方
每接收到一個有序分組傳遞到上層,丢棄無序分組
累積确認收到的有序分組
丢棄無序分組的優點在于接收方緩存簡單,需要維護的唯一資訊就是下一個按序接收的分組的序号;缺點是對于丢棄的分組,随後重傳也許會丢失或出錯,是以甚至需要更多的重傳
2)選擇重傳(SR)
一個單個分組的差錯就可能引起GBN重傳大量分組,許多分組根本沒有必要重傳。随着信道差錯率的增加,流水線可能被這些沒有必要重傳的分組填滿
- 發送方
如果收到的ACK對應一個視窗内的分組,則标記為已接收,序号等于send_base則移動視窗至具有最小序号的未确認分組處
如果視窗移動了,并且有序号落在視窗内的未發送分組,則發送這些分組
如果發生逾時,隻能發送1個分組
- 接收方
确認(ACK)一個正确接收到的分組(收到滑動視窗前的分組也要再次确認,因為這種情況通常意味着這個分組的前一次确認未被發送方收到);
失序分組會被緩存直到所有丢失分組都被收到,此時将一批分組按序傳遞給上層.
一個SR運作的例子:
對于SR而言,接收方視窗長度必須小于等于序号空間大小的一半,否則可能無法确認一個分組是重傳還是初次傳送
3.4 TCP
TCP是面向連接配接的,提供全雙工的服務:資料流可以雙向傳輸。也是點對點的,即在單個發送方與單個接收方之間的連接配接。
特征:
- 面向連接配接
- 隻能點對點(一對一)通信
- 可靠互動
- 全雙工通信
- 面向位元組流
TCP 如何保證可靠傳輸:
- 确認和逾時重傳
- 資料合理分片和排序
- 流量控制
- 擁塞控制
- 資料校驗
3.4.1 TCP封包段結構
TCP 封包結構

TCP頭部
字段定義
- 源端口号(16位)
- 目的端口号(16位)
- 序号(32位)TCP的序号是資料流中的位元組數,不是分組的序号。表示該封包段資料字段首位元組的序号
- 确認号(32位)TCP使用累積确認,确認号是第一個未收到的位元組序号,表示希望接收到的下一個位元組
- 首部長度(4位)通常選項字段為空,是以一般TCP首部的長度是20位元組
- 保留(6位)
- 标志字段(6位)
- ACK:訓示确認字段中的值是有效的
- RST,SYN,FIN:連接配接建立與拆除
- PSH:訓示接收方應立即将資料交給上層
- URG:封包段中存在着(被發送方的上層實體置位)“緊急”的資料
- 視窗(16位)
- 校驗和(16位)
- 緊急指針(16位)
- 選項
TCP:狀态控制碼(Code,Control Flag),占 6 比特,含義如下:
- URG:緊急比特(urgent),當
URG=1
- ACK:确認比特(Acknowledge)。隻有當
ACK=1
ACK=0
- PSH:(Push function)若為 1 時,代表要求對方立即傳送緩沖區内的其他對應封包,而無需等緩沖滿了才送。
- RST:複位比特(Reset),當
RST=1
- SYN:同步比特(Synchronous),SYN 置為 1,就表示這是一個連接配接請求或連接配接接受封包,通常帶有 SYN 标志的封包表示『主動』要連接配接到對方的意思。
- FIN:終止比特(Final),用來釋放一個連接配接。當
FIN=1
3.4.2 TCP流量控制
概念
流量控制(flow control)就是讓發送方的發送速率不要太快,要讓接收方來得及接收。
方法
利用可變視窗進行流量控制
如果應用程式讀取資料相當慢,而發送方發送資料太多、太快,會很容易使接收方的接收緩存溢出,流量控制就是用來進行發送速度和接收速度的比對。發送方維護一個“接收視窗”變量,這個變量表示接收方目前可用的緩存空間
- LastByteRead:接收方應用程式從接收緩存中讀取的最後一個位元組
- LastByteRcvd:接收方接收到的最後一個位元組
要防止緩存溢出,則應該滿足如下條件:
LastByteRecv - LastByteRead <= RcvBuffer
接收方可通過下列公式計算RcvWindow:
RcvWindow = RcvBuffer - [LastByteRecv - LastByteRead]
然後将RcvWindow的值記錄在TCP封包段中,發送給發送方。發送方輪流跟蹤兩個變量LastByteSent和LastByteAcked,這兩個變量之差就是發送到連接配接中但未被确認的資料量。通過将其控制在RcvWindow内,就能實作流量控制:
LastByteSent - LastByteAcked <= RcvWindow
這個方案存在一個問題,當接收方緩存已滿時,将RcvWindow=0通告給發送方,并且接收方沒有任何資料要發送給發送方,随着接收方應用程序清空緩存,TCP并不向發送方發送帶有RcvWindow新值的新封包段;TCP僅在它有資料或确認要發送時才會發送封包段。這樣,發送方不會知道接收方緩存已經有新的空間,發送方是以被阻塞而不能再發送資料。為解決這個問題,TCP規約中要求:當接收方的接收視窗為0時,發送方繼續發送隻有1個位元組資料的封包段。這些封包段将會被接收方确認。最終緩存将開始清空,并且确認封包裡将包含一個非0的RcvWindow值。
3.4.3 TCP連接配接管理
因為 TCP 三次握手建立連接配接、四次揮手釋放連接配接很重要。
TCP 三次握手建立連接配接
【TCP 建立連接配接全過程解釋】
- 用戶端發送 SYN 給伺服器,說明用戶端請求建立連接配接;
- 服務端收到用戶端發的 SYN,并回複 SYN+ACK 給用戶端(同意建立連接配接);
- 用戶端收到服務端的 SYN+ACK 後,回複 ACK 給服務端(表示用戶端收到了服務端發的同意封包);
- 服務端收到用戶端的 ACK,連接配接已建立,可以資料傳輸。
TCP 為什麼要進行三次握手?
【答案一】因為信道不可靠,而 TCP 想在不可靠信道上建立可靠地傳輸,那麼三次通信是理論上的最小值。(而 UDP 則不需建立可靠傳輸,是以 UDP 不需要三次握手。)
Google Groups . TCP 建立連接配接為什麼是三次握手?{技術}{網絡通信}
【答案二】因為雙方都需要确認對方收到了自己發送的序列号,确認過程最少要進行三次通信。
知乎 . TCP 為什麼是三次握手,而不是兩次或四次?
TCP 四次揮手釋放連接配接
【TCP 釋放連接配接全過程解釋】
- 用戶端發送 FIN 給伺服器,說明用戶端不必發送資料給伺服器了(請求釋放從用戶端到伺服器的連接配接);
- 伺服器接收到用戶端發的 FIN,并回複 ACK 給用戶端(同意釋放從用戶端到伺服器的連接配接);
- 用戶端收到服務端回複的 ACK,此時從用戶端到伺服器的連接配接已釋放(但服務端到用戶端的連接配接還未釋放,并且用戶端還可以接收資料);
- 服務端繼續發送之前沒發完的資料給用戶端;
- 服務端發送 FIN+ACK 給用戶端,說明服務端發送完了資料(請求釋放從服務端到用戶端的連接配接,就算沒收到用戶端的回複,過段時間也會自動釋放);
- 用戶端收到服務端的 FIN+ACK,并回複 ACK 給用戶端(同意釋放從服務端到用戶端的連接配接);
- 服務端收到用戶端的 ACK 後,釋放從服務端到用戶端的連接配接。
TCP 為什麼要進行四次揮手?
【問題一】TCP 為什麼要進行四次揮手? / 為什麼 TCP 建立連接配接需要三次,而釋放連接配接則需要四次?
【答案一】因為 TCP 是全雙工模式,用戶端請求關閉連接配接後,用戶端向服務端的連接配接關閉(一二次揮手),服務端繼續傳輸之前沒傳完的資料給用戶端(資料傳輸),服務端向用戶端的連接配接關閉(三四次揮手)。是以 TCP 釋放連接配接時伺服器的 ACK 和 FIN 是分開發送的(中間隔着資料傳輸),而 TCP 建立連接配接時伺服器的 ACK 和 SYN 是一起發送的(第二次握手),是以 TCP 建立連接配接需要三次,而釋放連接配接則需要四次。
【問題二】為什麼 TCP 連接配接時可以 ACK 和 SYN 一起發送,而釋放時則 ACK 和 FIN 分開發送呢?(ACK 和 FIN 分開是指第二次和第三次揮手)
【答案二】因為用戶端請求釋放時,伺服器可能還有資料需要傳輸給用戶端,是以服務端要先響應用戶端 FIN 請求(服務端發送 ACK),然後資料傳輸,傳輸完成後,服務端再提出 FIN 請求(服務端發送 FIN);而連接配接時則沒有中間的資料傳輸,是以連接配接時可以 ACK 和 SYN 一起發送。
【問題三】為什麼用戶端釋放最後需要 TIME-WAIT 等待 2MSL 呢?
【答案三】
- 為了保證用戶端發送的最後一個 ACK 封包能夠到達服務端。若未成功到達,則服務端逾時重傳 FIN+ACK 封包段,用戶端再重傳 ACK,并重新計時。
- 防止已失效的連接配接請求封包段出現在本連接配接中。TIME-WAIT 持續 2MSL 可使本連接配接持續的時間内所産生的所有封包段都從網絡中消失,這樣可使下次連接配接中不會出現舊的連接配接封包段。
3次握手
1.用戶端向伺服器發送SYN封包段(不包含應用層資料,首部的一個标志位(即SYN比特)被置位,用戶端随機化選擇(避免攻擊)一個起始序号x)
2.伺服器為該TCP連接配接配置設定TCP緩存和變量,傳回一個SYNACK封包段(也不包含應用層資料,SYN比特被置為1,ACK為x+1,伺服器選擇自己的初始序列y)
3.客戶機為該連接配接配置設定緩存和變量,傳回一個對SYNACK封包段進行确認的封包段(因為連接配接已經建立了,是以SYN比特被置為0)
如果用戶端不發送ACK來完成第三次握手,最終(通常是一分鐘後)伺服器将終止該半開連接配接并回收已配置設定的資源(在第三次握手前配置設定緩存和變量,可能會受到SYN洪泛攻擊)
如果第二次握手丢包怎麼辦?第三次呢?——知乎車小胖的回答
- 第二個包,即B發給A的SYN +ACK 中途被丢,沒有到達A:B會周期性逾時重傳,直到收到A的确認
- 第三個包,即A發給B的ACK 中途被丢,沒有到達B:A發完ACK,單方面認為TCP為 Established狀态,而B顯然認為TCP為Active狀态
- 假定此時雙方都沒有資料發送:B會周期性逾時重傳,直到收到A的确認,收到之後B的TCP 連接配接也為Established狀态,雙向可以發包
- 假定此時A有資料發送:B收到A的 Data + ACK,自然會切換為established 狀态,并接受A的Data
- 假定B有資料發送:資料發送不了,會一直周期性逾時重傳SYN + ACK,直到收到A的确認才可以發送資料
SYN洪泛攻擊:攻擊者發送大量的TCP SYN封包段,而不完成三次握手的第三步。通過從多個源發送SYN能夠加大攻擊力度,産生DDos(分布式拒絕服務) SYN洪泛攻擊 預防:SYN cookies。
- 當伺服器接收到一個SYN封包段時,它并不知道該封包段是來自一個合法的使用者,還是一個SYN洪泛攻擊的一部分。是以伺服器不會為該封包段生成一個半開TCP連接配接。相反,伺服器生成一個初始TCP序列号y,該序列号是SYN封包段的源和目的IP位址、端口号以及僅被該伺服器所知的秘密數的一個散列函數,這種精心制作的初始序列号被稱作“cookie”。伺服器發送具有這種特殊序列号的SYNACK分組,伺服器并不記憶該cookie或任何對應于SYN的其他狀态資訊
SYN cookies預防SYN洪泛攻擊:
- 當伺服器接收到一個SYN封包段時,它并不知道該封包段是來自一個合法的使用者,還是一個SYN洪泛攻擊的一部分。是以伺服器不會為該封包段生成一個半開TCP連接配接。相反,伺服器生成一個初始TCP序列号y,該序列号是SYN封包段的源和目的IP位址、端口号以及僅被該伺服器所知的秘密數的一個散列函數,這種精心制作的初始序列号被稱作“cookie”。伺服器發送具有這種特殊序列号的SYNACK分組,伺服器并不記憶該cookie或任何對應于SYN的其他狀态資訊
- 如果客戶機是合法的,它将傳回一個ACK封包段。伺服器一旦收到該ACK,需要驗證與前面發送的某些SYN對應的ACK。對于一個合法的ACK,确認字段中的值等于SYNACK序号字段y的值加1。伺服器将使用在ACK封包段中的相同字段和秘密數運作相同的函數。如果該函數的結果加1與确認号相同,伺服器就認為該ACK對應于前面發送的SYN封包段,生成一個具有套接字的全開的連接配接
- 如果客戶機沒有傳回一個ACK封包段,則初始化的SYN也沒有對該伺服器産生危害,因為伺服器沒有為它配置設定任何資源
前兩次握手不包含有效載荷,第三次“握手”可以承載有效載荷
為什麼需要3次握手而不是4次或2次?——知乎車小胖的回答
- 流程
- 用戶端發送syn包(syn=x)到伺服器,并進入SYN_SEND狀态,等待伺服器确認;
- 伺服器收到syn包,必須确認客戶的SYN(ack=x+1),同時自己也發送一個SYN包(syn=y),即SYN+ACK包,此時伺服器進入SYN_RECV狀态;
- 用戶端收到伺服器的SYN+ACK包,向伺服器發送确認包ACK(ack=y+1),此包發送完畢,用戶端和伺服器進入ESTABLISHED狀态,完成三次握手。
- [外鍊圖檔轉存失敗,源站可能有防盜鍊機制,建議将圖檔儲存下來直接上傳(img-vb4ApSJP-1590982812328)(http://img.qiuye.online/18-9-19/67777489.jpg)]
- 為什麼需要三次握手,第二次會出現什麼問題?
- 防止已經失效的連接配接請求又被封包段傳輸到主機,進而産生錯誤,使得主機持續等待發來的資料,造成資源浪費。
4次揮手
TCP連接配接的兩個程序中任意一個都能終止該連接配接,連接配接關閉需要4步。假設用戶端發起一個關閉請求:
1.用戶端發送一個FIN封包(首部中的FIN比特被置位)
2.伺服器傳回一個對FIN封包的确認封包
3.伺服器發送一個FIN封包(首部中的FIN比特被置位)
4.用戶端傳回一個對FIN封包的确認封包
MSL(最長分節生命期)是任何IP資料報能夠在網際網路中存活的最長時間(IP資料報中的TTL首部為8位,具有最大TTL,即255的分組,在網絡中存在的時間不能超過MSL)。任何TCP實作都必須為MSL選擇一個值。RFC 1122的建議值是2分鐘,不過源自Berkeley的實作傳統上改用30秒。意味着TIME_WAIT狀态的持續時間再1分鐘到4分鐘之間
四次揮手是因為TCP是全雙工的,前2次揮手用于關閉一個方向的資料通道,後兩次揮手用于關閉另外一個方向的資料通道
TIME-WAIT狀态的詳細說明,主要有2個存在的理由:
- 可靠地實作TCP全雙工連接配接的終止
- 等待迷途分組在網絡中消逝
nmap:可以“偵察”打開的TCP接口、UDP接口;還能“偵察”防火牆及其配置;甚至能“偵察”應用程式及作業系統版本。
- 流程
- 主動關閉方發送一個FIN,用來關閉主動方到被動關閉方的資料傳送,也就是主動關閉方告訴被動關閉方:我已經不會再給你發資料了(當然,在fin包之前發送出去的資料,如果沒有收到對應的ack确認封包,主動關閉方依然會重發這些資料),但是,此時主動關閉方還可以接受資料。
- 被動關閉方收到FIN包後,發送一個ACK給對方,确認序号為收到序号+1(與SYN相同,一個FIN占用一個序号)。
- 被動關閉方發送一個FIN,用來關閉被動關閉方到主動關閉方的資料傳送,也就是告訴主動關閉方,我的資料也發送完了,不會再給你發資料了。
- 主動關閉方收到FIN後,發送一個ACK給被動關閉方,确認序号為收到序号+1,至此,完成四次揮手。
- [外鍊圖檔轉存失敗,源站可能有防盜鍊機制,建議将圖檔儲存下來直接上傳(img-1yNwEXJh-1590982812328)(http://img.qiuye.online/18-9-19/89768478.jpg)]
- 為什麼需要四次揮手,為什麼要等2msl再關閉?
- TCP是全雙工通信,主動斷開方發送FIN并不意味着立即關閉TCP連接配接,而是告訴對方自己沒有更多的資料要發送了,隻有當對方發完自己的資料再發送FIN後,才意味着關閉TCP連接配接;
- TIME_WAIT 狀态
- TIME_WAIT的作用
- 主動關閉的一方在發送完最後一個ACK後就會進入TIME_WAIT狀态,并停留2MSL最大封包生存時間。
-
為了實作 TCP 全雙工連接配接的可靠性關閉,用來重發可能丢失的
ACK封包;
- 為什麼需要持續2個MSL(最大封包生存時間)?
- 假設應用程式端口在進入TIME_WAIT後,2個MSL時間内并沒有收到FIN,說明應用程式最後發出的ACK已經收到了;否則會在2個MSL内再次收到ACK.。
- TIME_WAIT 次數多了會怎麼樣?為什麼 ?如何緩解?
- 在高并發短連接配接的TCP伺服器上,當伺服器處理完請求後立刻主動正常關閉連接配接。這個場景下會出現大量socket處于TIME_WAIT狀态。如果用戶端的并發量持續很高,此時部分用戶端就會顯示連接配接不上。
- 調節系統參數reuse,reclcye,負載均衡
- 回退N幀協定/滑動視窗
- 滑動視窗怎麼實作的(原理)
- 使用的技術包括:校驗和、積累确認、序号、逾時重傳
- 視窗裡包含已經發送但尚未收到确認的資料,和允許發送但尚未發送的資料
- 積累确認:表明接收方已經接收到序号及之前的所有分組,隻關注最近按序接收的分組
- 不緩存失序分組
- 你覺得這樣實作會有什麼問題->怎麼解決
- 性能問題:單個分組的差錯就會引起重傳大量分組
- 引入選擇重傳機制
- 選擇重傳确認一個隻能夠正确接收的分組而不管其是否按序
- 選擇重傳會緩存失序分組
- TCP通常會緩存失序封包,但TCP最多會重傳一個封包段,GBN會重傳n和它後繼的所有分組
- 視窗的大小如何确定
- 發送視窗是根據接收視窗和擁塞視窗的最小值确定的
- 接收視窗根據接收方的緩沖區大小決定
- 擁塞視窗根據慢啟動擁塞避免快恢複算法決定
- 擁塞避免/慢啟動/快重傳/快速恢複
- 慢啟動:
- TCP發送速率起始慢,但在慢啟動階段以指數增長,每過一個往返時間,擁塞視窗的封包段數目翻番。
- 檢測到阻塞,将慢啟動門限設定為擁塞視窗的1/2,将擁塞視窗置1,并重新開始慢啟動。
- 當擁塞視窗的值再次達到慢啟動門限時,TCP轉移到擁塞避免模式。
- 擁塞避免:
- 每個往返時間隻将擁塞視窗的值加一個MSS(最大封包段長度1460)
- 當出現逾時時,将慢啟動門限設定為擁塞視窗的1/2,并将擁塞視窗的值置1,重新開始慢啟動。
- 快速恢複:
- 如果發送端接收到到3個備援ACK,則執行快速重傳,并進入快速恢複階段。
- 将慢啟動門限設定為擁塞視窗的一半,并将擁塞視窗設定為此時門限加3(即原視窗/2+3)後進入擁塞避免狀态。
- 如果出現逾時事件,快速恢複在執行如同在慢啟動和擁塞避免中相同的動作後,遷移到慢啟動狀态。
- SYN攻擊
- SYN攻擊是什麼,怎麼處理?
- SYN攻擊屬于DOS攻擊的一種,它利用TCP協定缺陷,攻擊者通過發送大量的SYN封包端,而不完成第三次握手步驟,耗費CPU和記憶體資源。
- 配合IP欺騙,SYN攻擊能達到很好的效果,通常用戶端在短時間内僞造大量不存在的IP位址,向伺服器不斷地發送syn包,伺服器回複确認包,并等待客戶的确認,由于源位址是不存在的,伺服器需要不斷的重發直至逾時,這些僞造的SYN包将長時間占用未連接配接隊列,正常的SYN請求被丢棄,目标系統運作緩慢,嚴重者引起網絡堵塞甚至系統癱瘓。
- SYN cookie的工作原理,cookie如何計算,在哪裡傳遞
- 伺服器收到一個SYN封包段後會先生成一個初始序列号(即cookie)
- 該序号是SYN封包段的源IP、目的IP位址與端口号以及一個秘密數的一個散列函數
- 伺服器發送具有這種特殊初始序列号的SYNACK分組
- 如果伺服器收到ACK,用同樣的秘密數和源、目的IP與端口散列驗證
- 如果結果加1等于該ACK中确認号,生成一個具有套接字的全開連接配接
3.4.4 TCP擁塞控制
概念
擁塞控制就是防止過多的資料注入到網絡中,這樣可以使網絡中的路由器或鍊路不緻過載。
方法
- 慢開始( slow-start )
- 擁塞避免( congestion avoidance )
- 快重傳( fast retransmit )
- 快恢複( fast recovery )
TCP的擁塞控制圖
擁塞控制分類:
- 端到端擁塞控制:網絡層沒有為運輸層擁塞控制提供顯示支援(TCP的擁塞控制)
- 網絡輔助的擁塞控制:網絡層元件向發送方提供關于網絡中擁塞狀态的顯式回報資訊(ATM ABR)
- 直接回報:路由器通過阻塞分組直接通知發送方擁塞
- 路由器标記或更新從發送方流向接收方的分組中的某個字段來訓示擁塞,接收方收到後通知發送方
由于IP層不向端系統提供顯示的網絡擁塞回報,是以TCP必須使用端到端擁塞控制,而不是網絡輔助擁塞控制
TCP連接配接的兩方都記錄一個額外的變量:擁塞視窗(CongWin),它對一個TCP發送方能向網絡中發送流量的速率進行了限制。特别是,在一個發送方中未被确認的資料量不會超過CongWin與RcvWindow中的最小值:
LastByteSent - LastByteAcked <= min{CongWin,RcvWindow}
後面的分析假設TCP接收緩存足夠大,是以不受RcvWindow的限制,進而可以隻關注擁塞視窗
兩個擁塞訓示:
- 3次備援ACK(第一次備援是第二次收到相同ACK時,是以一共4次)
- 逾時
TCP擁塞控制算法包括三個主要部分:
1.加性增、乘性減
- 加性增:緩慢增加CongWin,每個RTT增加1個MSS,線性增長(擁塞避免)
- 乘性減:發生丢包時,設定CongWin = CongWin/2(不低于1個MSS),進而控制發送速度
2.慢啟動:TCP連接配接開始時,CongWin的初始值為1個MSS,指數型增長
3.對擁塞訓示作出反應
- 3次備援ACK:CongWin = CongWin/2,然後線性增加(擁塞避免)
- 逾時:CongWin被設定為1個MSS,然後指數增長,直到CongWin達到逾時前的一半為止
Threshold(門檻值):用于确定慢啟動将結束并且擁塞避免将開始的視窗長度,初始化為一個很大的值,每當發送一個丢包時,會被設定為丢包時CongWin的一半
3.4.5 TCP的應用場景
- web:HTTP 80
- 檔案傳輸:FTP 21 20
- 電子郵件:SMTP 25 POP3 110
- 遠端終端通路:TELNET 23 RDP 3389 遠端桌面協定
如何保證可靠傳輸?
- 差錯檢測、确認、重傳
- 序号(解決ACK受損的問題,判斷是否為重傳的):
- 接收端收到備援分組則丢棄
- 發送端收到備援ACK則重傳
- 定時器
如何檢驗丢包?
- 校驗和、确認分組、逾時重傳、序号
如何保證TCP的可靠傳輸?
- 檢驗和、重傳、積累确認、序号、确認号、定時器
TCP協定有幾大計時器
-
重傳計時器
在一個TCP連接配接中,TCP每發送一個封包段,就對此封包段設定一個逾時重傳計時器。若在收到了對此特定封包段的确認之前計時器截止期到,則重傳此封包段,并将計時器複位。
-
持續計時器
為了對付零視窗大小通知,TCP需要另一個計時器。假定接收TCP宣布了視窗大小為零。發送TCP就停止傳送封包段,直到接收TCP發送确認并宣布一個非零的視窗大小。但這個确認可能會丢失。我們知道在TCP中,對确認是不需要發送确認的。若确認丢失了,接收TCP并不知道,而是會認為它已經完成任務了,并等待着發送TCP接着會發送更多的封包段。但發送TCP由于沒有收到确認,就等待對方發送确認來通知視窗的大小。雙方的TCP都在永遠地等待着對方。要打開這種死鎖,TCP為每一個連接配接使用一個堅持計時器。當發送TCP收到一個視窗大小為零的确認時,就啟動堅持計時器。當堅持計時器期限到時,發送TCP就發送一個特殊的封包段, 叫做 探測封包段 。這個封包段隻有一個位元組的資料。它有一個序号,但它的序号永遠不需要确認;甚至在計算對其他部分的資料的确認時該序号也被忽略。探測封包段提醒對端:确認已丢失,必須重傳。
- 保活計時器
保活計時器使用在某些實作中,用來防止在兩個TCP之間的連接配接出現長時期的空閑。假定客戶打開了到伺服器的連接配接,傳送了一些資料,然後就保持靜默了。也許這個客戶出故障了。在這種情況下,這個連接配接将永遠地處理打開狀态。
- 時間等待計時器
時間等待計時器是在連接配接終止期間使用的。當TCP關閉一個連接配接時,它并不認為這個連接配接馬上就真正地關閉了。在時間等待期間中,連接配接還處于一種中間過渡狀态。這就可以使重複的FIN封包段(如果有的話)可以到達目的站因而可将其丢棄。這個計時器的值通常設定為一個封包段的壽命期待值的兩倍。
3.4.6 TCP 黏包問題
原因
TCP 是一個基于位元組流的傳輸服務(UDP 基于封包的),“流” 意味着 TCP 所傳輸的資料是沒有邊界的。是以可能會出現兩個資料包黏在一起的情況。
解決
- 發送定長包。如果每個消息的大小都是一樣的,那麼在接收對等方隻要累計接收資料,直到資料等于一個定長的數值就将它作為一個消息。
- 標頭加上包體長度。標頭是定長的 4 個位元組,說明了包體的長度。接收對等方先接收標頭長度,依據標頭長度來接收包體。
- 在資料包之間設定邊界,如添加特殊符号
\r\n
\r\n
- 使用更加複雜的應用層協定。
3.4.7 TCP 有限狀态機
TCP 有限狀态機圖檔
3.5 UDP
- UDP(User Datagram Protocol,使用者資料報協定)是 OSI(Open System Interconnection 開放式系統互聯) 參考模型中一種無連接配接的傳輸層協定,提供面向事務的簡單不可靠資訊傳送服務,其傳輸的機關是使用者資料報。
特征:
- 無連接配接
- 盡最大努力傳遞
- 面向封包
- 沒有擁塞控制
- 支援一對一、一對多、多對一、多對多的互動通信
- 首部開銷小
UDP 封包結構
UDP 首部
TCP/UDP 圖檔來源于:<https://github.com/JerryC8080/understand-tcp-udp
3.5.1 UDP實作的工作
-
複用/分解:通常應用
程式用戶端自動配置設定端口号,伺服器端配置設定一個特定的端口号
- 差錯檢測:端到端原則,在較低級别設定該功能是備援的,沒有差錯恢複
3.5.2 UDP的優點
- 應用層可以更精細的控制何時發送什麼資料(TCP擁塞時會遏制發送方發送)
- 無需建立連接配接,則沒有建立連接配接的時延
- 不必維護連接配接狀态:TCP要維護包括接收和發送緩存、擁塞控制參數、以及序号與确認号的參數
- 分組首部開銷小:UDP有8位元組首部,TCP有20位元組首部
可以在應用程式自身中建構可靠性機制來實作UDP應用的可靠資料傳輸。
UDP能提供運輸層最低限度的兩個服務:差錯檢測、資料傳遞。
3.5.3 UDP封包段結構
UDP首部隻有4個字段,每個字段2個位元組,一共8個位元組大小的首部
校驗和:對封包段中的所有16比特字(包括資料部分,不包括校驗和本身)的和相加(如有溢出會卷回)的結果取反就是校驗和。在接收方,會将所有16比特字的和相加,如果分組無差錯,這個和會是“1111-1111-1111-1111”(為了友善閱讀,使用’-’分隔)
許多鍊路層協定提供了差錯檢測,UDP還需提供校驗和的原因在于,不能確定所有鍊路都提供了差錯檢測。此外,即使封包段經鍊路正确地傳輸,當其存儲在某台路由器的記憶體中時,也可能引入比特差錯。既未確定逐段鍊路的可靠性,也未確定記憶體中的差錯檢測,是以UDP必須在端到端基礎上在運輸層提供差錯檢測
校驗和方法需要相對小的分組開銷。例如,TCP和UDP中的校驗和隻用了16比特。然而與常用于鍊路層的CRC(循環備援檢測)相比,他們提供相對弱的差錯保護。傳輸層使用校驗和而鍊路層使用CRC的原因是:運輸層通常在主機中作為使用者作業系統的一部分并用軟體實作,是以采用簡單而快速(如校驗和)的差錯檢測方案是重要的。另一方面,鍊路層的差錯檢測在擴充卡中用專業硬體實作,它能快速地執行更複雜的CRC操作。
- 字段含義
- 源端口号(16位)
- 目的端口号(16位)
- UDP長度(16位):備援的,IP頭部已經提供資料報長度和首部長度
- UDP檢驗和(16位):傳送中不會被修改,除非遇到NAT,計算時加入僞頭部,包含源IP與目的IP,以驗證是否正确的到達目的地
- 資料
3.5.4 UDP的應用場景
- 域名位址轉換:DNS
- 路由選擇表的更新:RIP
- 遠端檔案伺服器:NFS
- 網絡管理資料:SNMP
- TFTP 簡單檔案傳輸協定 不支援身份認證
- DHCP
UDP為什麼不可靠,怎麼解決UPD的可靠性問題?
- 不需要建立連接配接就可以開始傳輸,沒有確定傳遞和流量控制機制,沒有擁塞控制機制。
- 要在應用層實作類似與TCP的可靠連接配接的技術,比如确認與重傳機制。
2.UDP中一個包的大小最大能多大?
- 以太網(Ethernet)資料幀的長度必須在46-1500位元組之間,這是由以太網的實體特性決定的.這個1500位元組被稱為鍊路層的MTU(最大傳輸單元).但這并不是指鍊路層的長度被限制在1500位元組,其實這這個MTU指的是鍊路層的資料區.
- 并不包括鍊路層的首部和尾部的18個位元組.是以,事實上,這個1500位元組就是網絡層IP資料報的長度限制.因為IP資料報的首部為20位元組,是以IP資料報的資料區長度最大為1480位元組.
- 而這個1480位元組就是用來放TCP傳來的TCP封包段或UDP傳來的UDP資料報的.又因為UDP資料報的首部8位元組,是以UDP資料報的資料區最大長度為1472位元組.這個1472位元組就是我們可以使用的位元組數。
為什麼UDP有時比TCP更有優勢?
- 網速的提升給UDP的穩定性提供可靠網絡保障,丢包率很低,如果使用應用層重傳,能夠確定傳輸的可靠性。
- TCP為了實作網絡通信的可靠性,使用了複雜的擁塞控制算法,建立了繁瑣的握手過程,由于TCP内置的系統協定棧中,極難對其進行改進。
- 采用TCP,一旦發生丢包,TCP會将後續的包緩存起來,等前面的包重傳并接收到後再繼續發送,延時會越來越大,基于UDP對實時性要求較為嚴格的情況下,采用自定義重傳機制,能夠把丢包産生的延遲降到最低,盡量減少網絡問題對遊戲性造成影響。
TCP 與 UDP 的差別
- TCP 面向連接配接,UDP 是無連接配接的;
- TCP 提供可靠的服務,也就是說,通過 TCP 連接配接傳送的資料,無差錯,不丢失,不重複,且按序到達;UDP 盡最大努力傳遞,即不保證可靠傳遞
- TCP 的邏輯通信信道是全雙工的可靠信道;UDP 則是不可靠信道
- 每一條 TCP 連接配接隻能是點到點的;UDP 支援一對一,一對多,多對一和多對多的互動通信
- TCP 面向位元組流(可能出現黏包問題),實際上是 TCP 把資料看成一連串無結構的位元組流;UDP 是面向封包的(不會出現黏包問題)
- UDP 沒有擁塞控制,是以網絡出現擁塞不會使源主機的發送速率降低(對實時應用很有用,如 IP 電話,實時視訊會議等)
- TCP 首部開銷20位元組;UDP 的首部開銷小,隻有 8 個位元組
4.網絡層
- IP(Internet Protocol,網際協定)是為計算機網絡互相連接配接進行通信而設計的協定。
- ARP(Address Resolution Protocol,位址解析協定)
- ICMP(Internet Control Message Protocol,網際控制封包協定)
- IGMP(Internet Group Management Protocol,網際組管理協定)
4.1網絡層功能和服務
網絡層的3個重要功能:
1.轉發:當一個分組到達某路由器的一條輸傳入連結路時,路由器将分組移動到适當輸對外連結路的過程
2.選路:當分組從發送方傳至接收方時,網絡層決定這些分組所采用的路由或路徑的過程
3.連接配接建立:ATM等非網際網路的網絡層體系結構要求從源到目的地沿着所選的路徑建立連接配接
虛電路和資料報網絡:
- 虛電路(VC)網絡:面向連接配接的,資料按需到達,分組不會丢失,路由器為進行中的連接配接維持連接配接狀态資訊
- 資料報網絡:無連接配接的,但在轉發表中維持了轉發狀态資訊。網際網路是資料報網絡(資料報網絡中,通常每1~5分鐘左右更新一次轉發表,因為轉發表會被修改,是以從一個端系統到另一個端系統發送一系列分組可能在通過網絡時走不同的路徑,進而無序到達)
4.2轉發
使用最長字首比對來比對路由表中的表項,決定轉發出口
路由器
路由器由4部分組成:
- 輸入端口
- 交換結構
- 輸出端口
- 選路處理器:維護有選路資訊與轉發表,并執行路由器中的網絡管理功能
1)輸入端口
- 查找/轉發子產品:對于路由器的轉發功能是至關重要的。許多路由器中,都是在這确定一個到達的分組經交換結構轉發到哪個輸出端口。雖然轉發表是由選路處理器計算的,但通常一份轉發表的影子拷貝會被存放在每個輸入端口,而且會被更新。是以,就可以在每個輸入端口本地做出轉發決策,而無需調用中央選路處理器,進而可以避免在路由器中的某個單點産生轉發處理的瓶頸
2)交換結構
一個分組可能會在進入交換結構時暫時阻塞,這是由于來自其它輸入端口的分組正在使用該交換結構
- 經記憶體交換:分組到達輸入端口時,端口會通過中斷向選路處理器發出信号,于是分組被拷貝到處理器記憶體中。選路處理器則從分組首部中取出目的位址,在轉發表中找出适當的輸出端口,并将分組拷貝到輸出端口的緩存中
- 經一根總線交換:經一根共享總線将分組直接傳送到輸出端口,不需要選路處理器的幹預。因為總線是共享的,故一次隻能有一個分組通過總線傳送
- 經一個互連網絡交換:到達某個輸入端口的分組沿着連到輸入端口的水準總線穿行,直至該水準總線與連到所希望的輸出端口的垂直總線的交叉點
3)輸出端口
輸出端口處理取出存放在輸出端口記憶體中的分組并将其傳輸到輸對外連結路上。當交換結構将分組傳遞給輸出端口的速率超過輸對外連結路速率時,就需要排隊與緩存管理功能
4)排隊
輸入端口和輸出端口都能形成分組隊列,随着隊列的增長,路由器的緩存空間将會最終耗盡,出現丢包
輸出端口排隊:當所有輸入端口的分組發往同一個輸出端口并且交換結構速率足夠大而輸出端口的分組傳輸速率不高時,分組會在該輸出端口排隊。排隊的後果是,輸出端口上的一個分組排程程式必須在這些排隊的分組中選一個來傳送,分組排程程式在提供服務品質保證方面起着關鍵作用
輸入端口排隊:如果交換結構速率不高,不同輸入端口的隊首分組需要發往同一個輸出端口,此時交換結構需要選擇其中一個輸入端口的分組進行發送。是以,其它輸入端口中的分組會阻塞産生排隊。在隊首分組之後的分組,也會因為隊首分組阻塞而被阻塞,即使它們需要轉發到的輸出端口此時處于空閑。這種現象叫做作線路前部阻塞(HOL)
4.3選路
- 第一跳路由器 = 預設路由器 = 源路由器
- 目的路由器:目的主機的預設路由器
源主機到目的主機選路的問題可歸結為從源路由器到目的路由器的選路問題
4.3.1 全局選路算法(LS算法)
全局選路算法用完整的、全局性的網絡資訊來計算從源到目的地之間的最低費用路徑。由于具有全局狀态資訊,是以這種算法又常被稱為鍊路狀态算法
- Dijkstra算法
4.3.2 分布式選路算法(距離向量算法)
以疊代的、分布式的方式計算出最低費用路徑。和全局選路算法的差別在于,沒有節點擁有關于所有網絡鍊路費用的完整資訊,每個節點僅有與其直接相連鍊路的費用資訊
- 距離向量算法(DV)
– 分布式:每個節點從一個或多個直接相連的鄰居接收某些資訊,執行計算,然後将計算結果發回鄰居
– 疊代:上述過程持續到鄰居之間沒有更多的資訊要交換為止
– 異步:不要求所有節點互相之間步伐一緻
DV使用公式:dx(y) = minv{c(x,v)+dv(y)} 更新x到y的距離(dx(y)是從x到y的最低費用路徑的費用,minv是指取遍x的所有鄰居)
好消息傳的快,壞消息傳的慢:
- 好消息傳的快
– t0時:y檢測到距x的費用由4變為1,更新其距離向量,并通知鄰居
– t1時:z收到來自y的更新封包并更新了其距離向量,計算出到x的新最低費用(5減為2)
– t2時:y收到來自z的更新并更新其距離表,y的最低費用未改變,不發送封包,算法終止
- 壞消息傳的慢
– t0時:y檢測到距x的費用由4變為60,y更新其到x的距離為6(途經z,因為z的距離表中記錄到x的距離為5),這是分布式的角度,從全局角度看,這個距離是錯的,但分布式中節點的狀态資訊有效。開始出現選路環路,即為到達x,y通過z選路,z又通過y選路,不停來回反複
– t1時:y将到達x的新費用告知z
– t2時:z收到y的消息,z計算出從x到x是50,從y到x是7,是以更新到x的最低費用為7,并通知y這個改變
– 上述過程會一直反複,直到z最終算出它經由y的路徑費用大于50為止(此時到x不途經y),y将經由z到x(如果費用增加到10000甚至更多,開銷可想而知)
4.3.3 網際網路中的選路
随着路由器數目變大,選路資訊的計算、存儲及通信的開銷逐漸高得驚人,數億台主機中存儲選路資訊需要巨大容量的記憶體。在公共網際網路上所有路由器上廣播LS更新的開銷将導緻沒有剩餘帶寬供發送資料分組使用。距離向量算法在如此大的路由器中的疊代将肯定永遠不會收斂。可以将路由器組織成自治系統(AS)來解決
自治系統(AS):一組處于相同的管理與技術控制下的路由器集合(ISP和AS之間是什麼關系?通常一個ISP中的路由器和互連它們的鍊路構成了單個AS,但許多ISP将它們的網絡劃分為多個AS)
網際網路中的選路協定:
- AS之間
- 邊界網關協定(BGP/BGP4)
- BGPv4是一種外部的路由協定。可認為是一種進階的距離向量路由協定。
- 路由器對使用179端口的半永久TCP連接配接交換選路資訊
- 每條TCP連接配接的兩台路由器被稱為BGP對等方
- 發送BGP封包的“TCP連接配接”稱為BGP會話(跨越兩個AS之間的BGP會話稱為eBGP,同一AS中兩個路由器間的BGP會話稱為内部BGP會話)
- BGP中,目的地是CIDR化的字首,表示一個子網或子網集合(假設有多個子網與一個AS相連,AS會聚合這些字首,來向相鄰的AS通告聚合後的單一字首,如果到達相同字首有多個路由,BGP會使用一些規則消除直到留下一條路由)
- 在BGP網絡中,可以将一個網絡分成多個自治系統。自治系統間使用eBGP廣播路由,自治系統内使用iBGP在自己的網絡内廣播路由。
- BGP路由選擇方法是基于距離向量路由選擇,與傳統的距離向量(1個單獨的度量,如跳數)協定不同,BGP将AS外部路徑的度量複雜化。
- BGP系統的主要功能是和其他BGP系統交換網絡可達資訊。網絡可達資訊包括列出的AS資訊。這些資訊有效地構造了AS互聯的拓樸圖并由此清除了路由環路,同時在AS級别上可實施政策決策。
- BGP特點:
- BGP是一種外部路由協定,與OSPF、RIP不同,其着眼點不在于發現和計算路由,而在于控制路由的傳播和選擇最好的路由。
- BGP通過攜帶AS路徑資訊,可以徹底的解決路由循環問題。
- 為了控制路由的傳播和路由的選擇,為路由附帶屬性資訊。
-
使用TCP作為其傳輸層協定,提高了協定的可靠性。端口号TCP
179。
- BGP-4支援CIDR(無類别域間選路),CIDR的引入簡化了路由聚合,減化了路由表。
- BGP更新時隻發送增量路由,減少了BGP傳播路由占用的帶寬。
- 提供了豐富的路由政策。
- 邊界網關協定(BGP/BGP4)
- AS内部
- 選路資訊協定(RIP)
- 運作于UDP之上的應用層協定
- 使用DV選路算法,使用跳數作為費用測度,“跳”是從源路由器到目的子網的子網數,一條路徑的最大費用被限制為15,進而限制了使用RIP的AS規模。
- 大約每30秒通過RIP響應封包(也稱為RIP通告)交換距離向量資訊
- 距離矢量協定
- 距離向量:RIP發送的封包包含一個距離向量(跳數)。每個路由器都根據它接收到鄰站的這些距離向量來更新自己的路由表。
- 工作過程
- 初始化:在啟動一個路由守護程式時,它先判斷啟動了哪些接口,并在每個接口上發送一個請求封包,要求其他路由器發送完整路由表。在點對點鍊路中,該請求是發送給其他終點的。如果網絡支援廣播的話,這種請求是以廣播形式發送的。目的UDP端口号是520(這是其他路由器的路由守護程式端口号)
- 接收到請求:如果這個請求是剛才提到的特殊請求,那麼路由器就将完整的路由表發送給請求者。否則,就處理請求中的每一個表項:如果有連接配接到指名位址的路由,則将度量設定成我們的值,否則将路徑成本設為16(度量為16是一種稱為"無窮大"的特殊值,它意味着沒有到達目的的路由)。然後發出響應。
- 接收到響應:使響應生效,可能會更新路由表。可能會增加新表項,對已有表項進行修改,或者将已有表項删除。
- 定期選路更新:每過30秒,所有或部分路由器會将其完整路由表發送給相鄰路由器。發送路由表可以是廣播形式的(如在以太網上),或是發送給點對點鍊路的其他終點。
-
觸發更新:每當一條路由的度量發生變化時,就對它進行更新。不需要發送完整的路由表,而隻需要發送那些變化的表項。每條路由都有與之相關的定時器。如果運作RIP的系統發現一條路由在
3分鐘内未更新,就将該路由的度量設定成無窮大( 16),并标注為删除。這意味着已經在 6個30秒更新時間裡沒收到通告該路由的路由器的更新了。再過 60秒,将從本地路由表中删除該路由,以保證該路由的失效已被傳播開。
- RIP的優缺點
- 算法簡單,配置簡單,适合用在小型網絡之中
- 無法區分非零部分是子網部分還是主機位址
- 這種方法看起來很簡單,但它有一些缺陷。首先,RIP沒有子網位址的概念。例如,如果标準的B類位址中16bit的主機号不為0,那麼RIP無法區分非零部分是一個子網号,或者是一個主機位址。有一些實作中通過接收到的RiP資訊,來使用接口的網絡掩碼,而這有可能出錯。
- 可能會發生路由環路在路由器或鍊路發生故障後,需要很長的一段時間才能穩定下來。這段時間通常需要幾分鐘。在這段建立時間裡,可能會發生路由環路。在實作RIP時,必須采用很多微妙的措施來防止路由環路的出現,并使其盡快建立。
- 度量最大為15,限制網絡大小
- 采用跳數作為路由度量忽略了其他一些應該考慮的因素。同時度量最大值為15,則限制了可以使用RIP的網絡的大小。
- 開放最短路徑優先(OSPF):直接作為IP協定的載荷
- 直接承載在IP分組中,必須自己實作可靠封包傳輸、鍊路狀态廣播等功能
- 使用LS選路算法,鍊路費用是由網絡管理者配置的
- 通常用于較頂層的ISP中,而RIP通常用于較低層的ISP中
- 至少每隔30分鐘廣播一次鍊路狀态(即使狀态未發生改變)
- 核心是一個使用泛洪鍊路狀态資訊的鍊路狀态協定和一個Dijkstra最低費用路徑算法。每個路由器主動地測試與其鄰站相連鍊路的狀态,将這些資訊發送給它的其他鄰站,而鄰站将這些資訊在自治系統中傳播出去。每個路由器接收這些鍊路狀态資訊,并建立起完整的路由表。
- OSPF與RIP的不同
- 鍊路狀态協定比距離向量協定收斂的更快。收斂的意思是在路由發生變化後,例如在路由關閉或鍊路出故障後,可以穩定下來。
- OSPF直接使用IP,對于IP首部的protocol字段,OSPF有其自己的值。
- OSPF較RIP的優點
- OSPF可以對每個IP服務類型計算各自的路由集。這意味着對于任何目的,可以有多個路由表表項,每個表項對應着一個IP服務類型。
- 給每個接口指派一個無維數的費用。可以通過吞吐率、往返時間、可靠性或其他性能來進行指派。可以給每個IP服務類型指派一個單獨的費用。
- 當對同一個目的位址存在着多個相同費用的路由時,OSPF在這些路由上平均配置設定流量。我們稱之為流量平衡。
- OSPF支援子網:子網路遮罩與每個通告路由相連。這樣就允許将一個任何類型的IP位址分割成多個不同大小的子網。到一個主機的路由是通過全1子網路遮罩進行通告的。預設路由是以IP位址為0.0.0.0、網絡掩碼為全0進行通告的。
- 路由器之間的點對點鍊路不需要每端都有一個IP位址,我們稱之為無編号網絡。這樣就可以節省IP位址。
- 采用了一種簡單鑒别機制。可以采用類似RIP-2的方法指定一個明文密碼。
- OSPF采用多點傳播,而不是廣播形式,以減少不參與OSPF的系統負載。
- 一些常見的其他問題
- OSPF的實作過程以及五種分組類型
- hello封包的作用,hello封包是基于UDP還是TCP?
- OSPF的負載均衡是怎麼做的?
- OSPF的使用場景
- OSPF和rip的本質差別是什麼?OSPF一定比RIP收斂快嗎?
-
ospf
是基于鍊路狀态的路由協定,主要以帶寬作為選路的依據
- RIP 是基于跳數的路由協定,以跳數作為選路的依據
- 選路資訊協定(RIP)
4.4 IP(網際協定)
IP 位址分類:
-
IP 位址 ::= {<網絡号>,<主機号>}
| IP 位址類别 | 網絡号 | 網絡範圍 | 主機号 | IP 位址範圍 |
| A 類 | 8bit,第一位固定為 0 | 0 —— 127 | 24bit | 1.0.0.0 —— 127.255.255.255 |
| B 類 | 16bit,前兩位固定為 10 | 128.0 —— 191.255 | 16bit | 128.0.0.0 —— 191.255.255.255 |
| C 類 | 24bit,前三位固定為 110 | 192.0.0 —— 223.255.255 | 8bit | 192.0.0.0 —— 223.255.255.255 |
| D 類 | 前四位固定為 1110,後面為多點傳播位址 | |||
| E 類 | 前五位固定為 11110,後面保留為今後所用 |
IP 資料報格式:
4.4.1 網際網路三大元件
1.IP協定
2.選路元件
3.報告資料報中的差錯和對某些網絡層資訊請求進行響應的設施
4.4.2 資料報格式
下圖為一個IPv4資料報的格式:
- 版本号:IP協定的版本,路由器根據版本号确定如何解釋剩餘部分
- 首部長度:一個IPV4資料報可包含一些可選項,是以需要用4比特确定資料部分實際從哪開始,大多數IP資料報不包含可選項,有20位元組的首部
- 服務類型:可以使不同類型(實時與非實時等)的IP資料報區分開來
- 資料報長度:IP資料報的總長(16bit,首部+資料,是以IPv4資料報的最大大小是65535位元組)
- 壽命(TTL):8位,用以確定資料報不會永遠在網絡中循環,每經過一台路由器減1,減為0時丢棄
- 上層協定:指明了資料部分應該交給哪個運輸層協定(UDP(6)、TCP(17))
- 首部校驗和:首部中每2個位元組作為一個數,和的反碼存入校驗和字段中。路由器一般會丢棄檢測出的錯誤資料報。每台路由器上都必須重新計算并更新校驗和,因為TTL及選項字段可能會改變
- 選項:在IPv6中已不再使用
除此之外,首部中的以下3個字段用于IP資料報分片的辨別
- 辨別:識别分片的序号
- 标志:最後一個分片的标志為0,其餘分片的标志為1(設定DF位表示不允許分片,可用于路徑MTU發現)
- 比特片偏移:該分片起始資料在原資料報中的偏移量/8
IPv4要求的最小鍊路MTU是68位元組,這允許最大IPv4首部(20位元組固定長度+最多40位元組選項部分)拼接最小的片段(IPv4首部中片段偏移字段以8個位元組為機關)
4.4.3 IP資料報分片
一個鍊路層幀能承載的最大資料量叫做最大傳輸單元(MTU)(以太網可承載不超過1500位元組的資料),因為每個IP資料報封裝在鍊路層幀中,再從一台路由器運輸到下一台路由器,故鍊路層協定MTU嚴格地限制着IP資料報的長度。發送方與目的地路徑上的每段鍊路可能使用不同的鍊路層協定,每種協定可能具有不同的MTU,如果轉發表查找決定的對外連結路的MTU比該IP資料報的長度小,則需要對IP資料報進行分片。片在到達目的地運輸層以前需要被組裝,如果一個或多個片沒有到達目的地,則該不完整的資料報被丢棄
分片可以通過4.2中介紹的IP資料報中的辨別、标志、比特片偏移來識别
4.4.4 IPv4編址
主機與實體鍊路之間的邊界叫做接口,一個IP位址在技術上是與一個接口相關聯的,而不是與包括該接口的主機或路由器相關聯的
IP位址編址格式:點分十進制,一個接口的IP位址的組成部分需要由其連接配接的子網來決定。互連主機的接口與路由器一個接口的網絡形成一個子網:
IP編址為子網配置設定一個位址:223.1.1.0/24,其中/24記法稱為子網路遮罩。其它要連到223.1.1.0/24網絡的主機都要求其位址形式為223.1.1.xxx
除此之外,子網還包括互連路由器接口的網段
1)分類編制
在無類别域間選路之前,IP位址的配置設定政策采用分類編制,網絡分為下面3類
- A類網絡:網絡部分被限制長度為8比特
- B類網絡:網絡部分被限制長度為16比特
- C類網絡:網絡部分被限制長度為24比特
分類編制的問題在于:對于一個組織,配置設定一個B類網絡可能太大,配置設定一個C類網絡可能太小,這樣配置設定B類網絡就會造成位址空間的迅速消耗,以及大量的位址浪費。這個問題類似于作業系統記憶體管理中固定分區的問題
2)無類别域間選路(CIDR)
32比特的IP位址被劃分為2部分,a.b.c.d/x,前x比特構成了IP位址的網絡部分,被稱為該位址的網絡字首
組織外部的路由器僅考慮字首比特,大大減少了路由器中的轉發表的長度。剩餘32-x比特用于區分組織内部裝置,當組織内部的路由器轉發分組時,才會考慮這些比特
IP位址由網際網路名字與号碼配置設定機構(ICANN)管理,非盈利的ICANN不僅配置設定IP位址,還管理DNS根伺服器、解決配置設定域名與域名糾紛,ICANN向地區性網際網路注冊機構配置設定位址,這些機構一起形成了ICANN位址支援組織,處理本地域内的位址配置設定/管理
4.4.5 DHCP(動态主機配置協定)
一個組織一旦獲得一塊位址,就可以為該組織内的主機和路由器接口配置設定獨立的IP位址
DHCP可以提供以下服務:
- 為主機配置設定IP位址
- 擷取子網路遮罩
- 擷取第一跳路由器位址(常稱為預設網關)
- 提供本地DNS伺服器的位址(記錄在/etc/resolv.conf檔案中)
由于DHCP具有能将主機連接配接進一個網絡的自動化網絡相關方面的能力,故它又常被稱為即插即用協定
每個子網擁有一台DHCP伺服器,如果某個子網沒有DHCP伺服器,則需要一個知道用于該網絡的一台DHCP伺服器位址的DHCP中繼代理(通常是一台路由器)
DHCP協定的4個步驟:
1.DHCP伺服器發現:新到的用戶端在68号端口使用UDP廣播(255.255.255.255)DHCP發現封包,源位址為0.0.0.0
2.DHCP伺服器提供:子網中收到DHCP請求封包的DHCP伺服器使用DHCP提供封包作出響應,提供IP位址、網絡掩碼、IP位址租用期(通常設定為幾個小時或幾天)
- DHCP請求:用戶端從多個伺服器的響應中選擇一個,并用一個DHCP請求封包對選中的伺服器進行響應,回顯配置參數(這一步目的位址使用廣播位址是因為在DHCP伺服器提供時,伺服器為客戶預配置設定了IP位址,是以,客戶有責任通知不采用的伺服器,好讓它們釋放預配置設定的位址)
4.DHCP ACK:伺服器用DHCP ACK封包對DHCP請求封包進行響應,證明所要求的參數
DHCP有不足之處:每當一個節點連到一個新子網時,都要從DHCP得到一個新的IP位址,這樣當一個移動節點在子網直接移動時,就不能維持與遠端應用之間的連接配接。移動IP是一種對IP基礎設施的擴充,允許移動節點在子網之間移動時能使用其單一永久的位址
4.4.6 NAT(網絡位址轉換)
NAT适用這樣一種場景:由于每個IP使能的裝置都需要一個IP位址,如果一個子網已經獲得了一塊IP位址,當連入裝置增加時,IP位址可能不足
NAT主要通過NAT使能路由器來解決上述問題。同時,位址空間10.0.0.0/8是在RFC 1918中保留的3部分IP位址空間之一,可以用于專用網絡或具有專用位址的地域(具有專用位址的地域是指其位址僅對該網絡中的裝置有意義的網絡),關鍵問題是:專用位址對于外部網絡無效,使用專用位址的裝置如何與外部網絡通信?為了解決這個問題,NAT使能路由器中儲存有一個NAT轉換表:
NAT使能路由器對外界的行為就像一個具有單一IP位址的單一裝置,通過端口号來辨別一個使用專用位址的裝置
- 當專用裝置與外界通信時,NAT使能路由器為其生成一個新的源端口号,并使用連入廣域網一側接口的IP位址作為源位址發送資料報,同時會将這個映射關系記錄在NAT轉換表中
- 當有資料報到達時,NAT使能路由器通過查找NAT轉換表中的映射關系,改寫目的IP和端口号,向專用網絡轉發資料報
私有IP網段:
- 10.0.0.0 ~ 10.255.255.255
- 172.16.0.0 ~ 172.31.255.255
- 192.168.0.0 ~ 192.168.255.255
NAT有很多争議:1)端口号是用于編址程序的方法,不是用于編址主機的;2)路由器應該處理最多達第三層的分組;3)NAT違反了所謂的“端到端原則”;4)解決IP位址短缺的方法應該是IPv6,而不是像NAT這樣一種權宜之計;但是不管喜歡與否,NAT已成為網際網路一個重要的元件
4.4.7 ICMP(網際網路控制封包協定)
ICMP 封包格式:
應用:
- PING(Packet InterNet Groper,分組網間探測)測試兩個主機之間的連通性
- TTL(Time To Live,生存時間)該字段指定 IP 包被路由器丢棄之前允許通過的最大網段數量
ICMP用于主機和路由器彼此互動網絡層資訊。最典型的用途是差錯報告,但其用途不僅限于此(如源抑制,用于擁塞控制)
ICMP通常被認為是IP的一部分,但從體系結構上講,它是位于IP之上,因為ICMP封包承載在IP分組中,作為IP有效載荷
ICMP的類型和編碼:
Traceroute:允許使用者跟蹤從一台主機到世界上任意一台其他主機之間的路由,使用ICMP封包實作。發送一系列不可達UDP端口号的UDP封包段,每個封包段封裝後的資料報TTL字段逐1遞增,TTL為n的資料報到達第n跳路由器時,由于TTL過期,路由器會生成ICMP封包響應,由此可以獲得第n跳路由器的IP和名字,當一個資料報最終到達目的主機時,由于UDP端口不可達,目的主機生成一個ICMP封包,訓示此錯誤資訊,進而Traceroute知道不需要再發送探測分組了,是以獲得了到達目的主機的所有路由數量、辨別以及RTT。
4.4.8 IPv6
1)IPv6資料報格式
IPv6引入了稱為任播位址的新位址,這種位址可以使一個資料報能傳遞給一組主機中的任意一個
定長的40位元組首部允許更快的處理IP資料報
- 版本号:IPv6将該字段值設定為6
- 流量類型:與IPv4中的”服務類型“字段含義相同,區分不同類型資料報(實時/非實時)
- 有效載荷:資料部分的位元組數(16bit,不包括首部,是以IPv6資料報的最大大小是65535+40=65575位元組)
- 下一個首部:應該傳遞給運輸層的哪個協定
- 跳限制:同TTL
IPv6不允許在中間路由器上進行分片與重新組裝,這種操作隻能在源與目的地上進行。如果一台路由器收到的IPv6資料報因太大而不能轉發到對外連結路上,則隻需丢掉該資料報,并傳回一個”分組太大“的ICMP差錯封包。是以IPv6中沒有IPv4用于分片相關的3個字段
IPv6的關注快速處理分組,由于運輸層提供了差錯檢測,IP設計者可能覺得沒必要再在網絡層進行差錯檢測,是以去掉了首部校驗和字段
IPv4中的選項字段并沒有作為IPv6的首部字段出現,但其并未消失,而是可能出現在可能出現在首部中由”下一個首部“指出的位置上
IPv6要求的最小鍊路MTU為1280位元組,IPv6可以運作在MTU小于此最小值的鍊路上,不過需要特定于鍊路的分片和重組功能,以使得這些鍊路看起來具有至少為1280位元組的MTU。IPv6隻有主機對其産生的資料報分片,IPv6路由器不對其轉發的資料報執行分片
2)從IPv4向IPv6遷移
雖然能處理IPv6的系統可做成向後相容的,即能發送和接收IPv4資料報,但已設定的IPv4使能的系統不能處理IPv6資料報,要解決這個問題可以使用雙棧(即IPv6節點也具有完整的IPv4實作,這樣的節點在RFC 4213中被稱為IPv6/IPv4節點)
一種雙棧方法是建隧道:
假定2個IPv6節點要使用IPv6通信(圖中的B和E),但經由IPv4路由器而互連,将中間IPv4路由器的集合稱為一個隧道
借助于隧道,在該隧道發送端的IPv6節點可将整個IPv6資料報放在一個IPv4資料報的資料字段中。于是該IPv4資料報的目的位址設為隧道接收端的IPv6節點(同時具有IPv6和IPv4位址),然後通過隧道傳輸,隧道接收端的IPv6節點E最終收到該IPv4資料報,并确定IPv4資料報含有一個IPv6資料報,提取出後再為IPv6資料報選路,轉發
為什麼TCP/IP在運輸層與網絡層都執行差錯檢測?
IP層隻對IP首部計算檢驗和,TCP/UDP檢驗和是對整個封包段進行的
- TCP/UDP與IP不一定同屬于一個協定棧
内部網關協定
- RIP(Routing Information Protocol,路由資訊協定)
- OSPF(Open Sortest Path First,開放最短路徑優先)
外部網關協定
- BGP(Border Gateway Protocol,邊界網關協定)
IP多點傳播
- IGMP(Internet Group Management Protocol,網際組管理協定)
- 多點傳播路由選擇協定
VPN 和 NAT
- VPN(Virtual Private Network,虛拟專用網)
- NAT(Network Address Translation,網絡位址轉換)
路由表包含什麼?
- 網絡 ID(Network ID, Network number):就是目标位址的網絡 ID。
- 子網路遮罩(subnet mask):用來判斷 IP 所屬網絡
- 下一跳位址/接口(Next hop / interface):就是資料在發送到目标位址的旅途中下一站的位址。其中 interface 指向 next hop(即為下一個 route)。一個自治系統(AS, Autonomous system)中的 route 應該包含區域内所有的子網絡,而預設網關(Network id:
0.0.0.0
0.0.0.0
根據應用和執行的不同,路由表可能含有如下附加資訊:
- 花費(Cost):就是資料發送過程中通過路徑所需要的花費。
- 路由的服務品質
- 路由中需要過濾的出/入連接配接清單
5.鍊路層
主要信道:
- 點對點信道
- 廣播信道
點對點信道
- 資料單元 ———— 幀
三個基本問題:
- 封裝成幀:把網絡層的 IP 資料報封裝成幀,
SOH - 資料部分 - EOT
- 透明傳輸:不管資料部分什麼字元,都能傳輸出去;可以通過位元組填充方法解決(沖突字元前加轉義字元)
- 差錯檢測:降低誤碼率(BER,Bit Error Rate),廣泛使用循環備援檢測(CRC,Cyclic Redundancy Check)
點對點協定(Point-to-Point Protocol):
- 點對點協定(Point-to-Point Protocol):使用者計算機和 ISP 通信時所使用的協定
廣播信道
廣播通信:
- 硬體位址(實體位址、MAC 位址)
- 單點傳播(unicast)幀(一對一):收到的幀的 MAC 位址與本站的硬體位址相同
- 廣播(broadcast)幀(一對全體):發送給本區域網路上所有站點的幀
- 多點傳播(multicast)幀(一對多):發送給本區域網路上一部分站點的幀
5.1鍊路層提供的服務
鍊路層可能提供的服務包括:
- 成幀:将網絡資料報封裝成幀
- 鍊路接入:媒體通路控制(MAC)協定規定了幀在鍊路上傳輸的規則
- 可靠傳遞:可靠傳遞服務通常用于易産生高差錯率的鍊路,對于低比特差錯的鍊路,可靠傳遞可能被認為是一種不必要的開銷,是以不提供此服務
- 流量控制:沒有流量控制,可能會造成緩存區溢出
- 差錯檢測和糾正:奇偶校驗,檢驗和,CRC校驗
- 半雙工和全雙工:全雙工時,鍊路兩端的節點可以同時傳輸分組
5.1.1 差錯檢測和糾錯技術
在發送節點,為了避免比特差錯,使用**差錯檢測和糾錯比特(EDC)**來增強資料的可靠性。
差錯檢測和糾正技術有時使接收方檢測到已經出現的比特差錯,但并非總是這樣。即使采用差錯檢測比特,也還是可能有未檢出比特差錯的情況
是以,主要是選擇一個差錯檢測方案,使得這種事件發生的機率很小。可以使用下列3種技術進行差錯檢測:
1.奇偶校驗:隻需包含1個附加比特。
– 對于偶校驗,選擇一個值使得所有比特中1出現偶數次
– 對于奇校驗,選擇一個值使得所有比特中1出現基數次 接收方通過檢測1出現的次數判斷是否出現差錯。如果出現偶數個比特差錯,則檢驗不出。可以使用二維化的方案(詳見教材)進行優化
2.校驗和:通常更多的應用于運輸層。将資料分為多個k比特的序列,相加(可能復原)後取反,作為校驗和。接收方對所有k比特(包括校驗和)的序列相加,結果的任意比特如果出現0,則檢測為出現比特差錯
3.循環備援檢測**(CRC)**:發送方和接收方協商一個r+1比特的生成多項式(G),要起其最高比特位為1。發送方通過在d比特的資料後附加r比特,使得整個(d+r)比特的值能夠被G整除。接收方用G去除(d+r)比特,如果餘數非0,則出現差錯(附加r比特的計算詳見教材)
5.2媒體通路控制(MAC)協定
5.2.1 點對點協定(PPP)
點對點協定(PPP)用于點對點鍊路,點對點鍊路由鍊路一端的單個發送方和鍊路另一端的單個接收方組成。通常住宅主機撥号鍊路就是用的PPP,是以它是目前部署最廣泛的鍊路層協定之一。
5.2.2 多路通路協定
多路通路協定用于廣播鍊路,廣播鍊路能夠讓多個發送和接收節點都連接配接到相同的、單一的、共享的廣播信道上。多路通路協定用于協調多個發送和接收節點對一個共享廣播信道的通路
1.信道劃分協定:帶寬限制:R/N
– TDM(時分多路複用):對于N個節點的信道,傳輸速率為R bps,TDM将時間劃分為時間幀,并進一步劃分每個時間幀為N個時隙,每個節點在特定的時隙内傳輸(消除了碰撞,非常公平;但節點被限制與R/N bps的平均速率,即使隻有一個節點有資料要發送)
– FDM(頻分多路複用):在R bps的信道中建立了N個較小的R/N bps信道,每個節點使用一個較小的信道傳輸(消除了碰撞,公平;但節點被限制與R/N bps的平均速率,即使隻有一個節點有資料要發送)
– CDMA(碼分多址):每個節點配置設定一種不同的編碼,每個節點使用其唯一的編碼來對發送的資料進行編碼(如果精心選擇編碼,不同節點能同時傳輸)
2.随機接入協定:全部速率
– 純ALOHA:幀到達節點時,立刻傳輸。如果發生碰撞,節點将立即(在完全傳輸碰撞幀後)以機率p重傳。否則,等待一個幀傳輸時間,再以機率p重傳…(信道有效傳輸速率實際不是R bps,而是時隙ALOHA的一半,詳見教材)
– 時隙ALOHA:時間被劃分為時隙,每個節點的時間同步,幀的傳輸隻在時隙的開始時進行。如果發生碰撞,在下一個時隙開始時以機率p重傳,否則等待一個時隙再以機率p重傳…(信道有效傳輸速率實際不是R bps,而是0.37R bps,詳見教材)
– CSMA(載波偵聽多路通路):發送前先偵聽信道,如果沒有其它節點在使用信道,則傳輸資料。CSMA沒有碰撞檢測,即使發生碰撞,也将傳輸完碰撞幀(由于節點間資料傳輸存在時延,很可能一個傳輸正在信道中但是由于還未到達是以檢測到信道空閑,此時傳輸最終會發生碰撞)
– CSMA/CD(具有碰撞檢測的載波偵聽多路通路):先偵聽信道,如果沒有其它節點在使用信道,則傳輸資料。但是有碰撞檢測,如果發生碰撞,會停止傳輸剩下的資料,等待一個随機時間(通常比傳輸一幀短)後,再進行嘗試
3.輪流協定
– 輪詢協定:指定節點之一為主節點。主節點以循環的方式輪詢每個節點。告訴每個節點能夠傳輸的最大幀數,然後讓節點傳輸幀,主節點通過觀察信道上是否缺乏信号來決定一個節點合适完成了幀的發送(消除了困擾随機接入協定的碰撞和空時隙,效率很高;但引入了輪詢延時,同時主節點發生故障将使信道不可用)
– 令牌傳遞協定:節點間通過令牌傳遞信道使用權,如果沒有資料發送,立即傳遞令牌給下一節點(一個節點的故障可能會使整個信道崩潰。或者如果一個節點忘記釋放令牌,必須調用某些恢複步驟使令牌傳回到循環中來)
5.3鍊路層編制
5.3.1 MAC位址
長度為6位元組,共48比特,通常用十六進制表示法,位址的每個位元組被表示為一對十六進制數
- 每個擴充卡具有一個唯一的MAC位址,不随位置發生變化(就像人的身份證,而IP則像人的郵政位址)
- 一台路由器的每個接口都有一個ARP子產品和一個擴充卡
MAC位址配置設定:當一個公司要生産擴充卡時,它支付象征性的費用購買一塊MAC位址空間,IEEE配置設定這塊位址時,固定前24比特,讓公司自己為每個擴充卡生成後24比特的唯一組合
5.3.2 ARP(位址解析協定)
- 提供将IP位址轉換為鍊路層位址的機制(ARP隻為同一子網上的節點解析IP位址,DNS為網際網路中任何地方的主機解析主機名): 1. 每個節點的ARP子產品都在它的RAM中有一個ARP表,包含IP位址到MAC位址的映射關系,每個表項還包含TTL字段,表示表項過期時間(ARP表是自動建立的,如果某節點與子網斷開連接配接,它的表項最終會從留在子網中的節點的表中删除。通常一個表項的過期時間是20分鐘) 2. 主機向其ARP子產品提供一個IP位址,ARP子產品傳回IP位址對應的MAC位址。
- ARP資料報格式
- 工作原理
- 查詢ARP表中有沒有該目的主機的表項
- 構造一個ARP查詢分組,用MAC廣播位址(全F)發送給全區域網路,比對的主機發送一個響應ARP分組
- 查詢主機更新ARP表,發送IP資料報
- 查詢ARP幀是在廣播幀中發送的,響應ARP封包在标準幀中發送
- 以太網首部(14位元組)加4位元組的CRC和1500位元組的MTU,最大幀長1518,最小幀長為64,最小有效載荷46位元組
- 以太網目的位址(6位元組)
- 以太網源位址(6位元組)
- 幀類型(2)位元組:即協定類型
- CRC(4位元組)在有效載荷後面
- ARP請求/應答(28位元組)
- 硬體類型(2位元組):以太網
- 協定類型(2位元組):IP協定
- 硬體位址長度(1位元組)
- 協定位址長度(1位元組)
- op(1位元組):請求/應答
- 發送端以太網位址(6位元組)
- 發送端IP位址(4位元組)
- 目的以太網位址(6位元組)
- 目的IP位址(4位元組)
- 填充位(18位元組):以太網規定最小資料長度為46位元組
如果相應表項尚未存在ARP表中? 1. 查詢節點構造ARP查詢分組,包含有查詢節點和目的節點的IP位址,擴充卡在鍊路層幀中封裝這個ARP分組,廣播幀 2. 子網中的所有其他擴充卡接收到幀,将幀中的ARP分組向上傳遞給ARP子產品,每個節點檢查自身IP是否與ARP查詢分組中的目的IP位址相同,相同的傳回一個ARP響應分組3. 查詢節點接收到ARP分組,獲得目的MAC位址,并更新自身的ARP表。
如何發送資料報到子網以外?
假設主機1要向主機2發送資料報,應該使用什麼MAC位址?如果使用49-BD-D2-C7-56-2A作為目的MAC位址,由于子網内任何一個擴充卡的MAC位址都不比對,是以這個資料報将會死亡。正确的步驟如下:
1.主機1通過ARP擷取路由器接口111.111.111.110的MAC位址,将資料報封裝成幀,轉發
2.路由器的接口111.111.111.110收到幀,由于MAC位址比對,擴充卡擷取幀中的資料報上傳給網絡層
3.路由器通過查找轉發表将資料報通過交換結構轉發到輸出接口222.222.222.220
4.輸出接口222.222.222.220通過ARP擷取子網中主機2的MAC位址
5.獲得主機2的MAC位址後,将資料報傳遞給擴充卡,封裝成幀,最終發送到主機2
5.4以太網
雖然20世紀80年代和90年代早期,以太網面臨着其他LAN技術包括令牌環、FDDI、ATM的挑戰,但是至今,以太網仍是最流行的有線區域網路技術。
所有的以太網技術都向網絡層提供無連接配接服務、不可靠服務。
5.4.1 以太網幀結構
- 前同步碼:8位元組。以太網幀以一個8位元組的前同步碼字段開始。前7個位元組的值都是10101010,最後一個位元組是10101011。前7個位元組用于“喚醒”接收擴充卡,并且将其時鐘與發送方的時鐘同步,第8個位元組的最後兩個1告訴接收擴充卡,“重要的内容”就要來了,是以接收擴充卡知道接下來的6個位元組是目的位址
- 類型:網絡層協定類型
- 資料:46~1500位元組。承載了IP資料報,以太網的最大傳輸單元(MTU)是1500位元組,IP資料報最小46位元組,如果不夠會填充(如果填充,在目的端填充也會上傳到網絡層,通過資料報首部的長度字段去除填充)
- 循環備援檢測**(CRC)**:提供差錯檢測與糾正,具體見1.1。如果校驗成果,并不會發送肯定确認。如果校驗失敗,也不會發生否定确認,隻是丢棄該幀
頭資訊有14位元組,尾部校驗和FCS占4位元組。是以,一個标準的以太網資料幀大小是1518。
5.4.2 鍊路層交換機
現代以太網LAN使用了一種星型拓撲,每個節點與中心交換機相連
- 交換機的任務是接收傳入連結路層幀并将它們轉發到對外連結路
- 交換機自身對節點透明:某節點向另一節點尋址一個幀,順利地将該幀發送進LAN,而不知道這個幀經過了某個交換機的接收與轉發
交換機具有如下性質:
- 消除碰撞:交換機緩存幀并且絕不會在網段上同時傳輸多于一個幀。交換機的最大聚合帶寬是所有接口速率之和
- 異質的鍊路:交換機将鍊路彼此隔離,LAN中的不同鍊路能夠以不同的速率運作,并且能夠在不同的媒體上運作
1)交換機轉發與過濾
- 過濾:交換機決定一個幀是應該轉發還是應該丢棄
- 轉發:決定一個幀應該被導向哪個接口
過濾和轉發都借助于交換機表:
假設具有目的位址DD-DD-DD-DD-DD-DD的幀從交換機的x接口到達:
- 如果表中沒有針對DD-DD-DD-DD-DD-DD的表項,則向除了x的其它所有接口廣播幀
- 如果表中有針對DD-DD-DD-DD-DD-DD的表項
- 1)接口等于x:(說明幀的目的地和幀處于同一子網,意味着該幀已經在包含目的位址的LAN網段廣播過了)該幀執行過濾功能
- 2)接口為y,不等于x:将幀轉發到接口y的輸出緩存區
2)自學習(即插即用)
交換機表是自動、動态、自治地建立的,沒有來自網絡管理者或配置協定的任何幹預。換句話說,交換機是自學習的
1.交換機表初始為空
2.源位址為DD-DD-DD-DD-DD-DD的幀從接口x到達時,1)如果不存在則建立一項;2)存在則更新目前時間
3.如果一段時間後,在x接口沒有來自DD-DD-DD-DD-DD-DD的幀,則将該表項删除
3)交換機與路由器對比
- 交換機
- 優點
- 即插即用
- 相對高的分組過濾、轉發速率
- 缺點
- 交換網絡的活躍拓撲限制為一棵生成樹(為了防止廣播幀的循環)
- 對廣播風暴不提供任何保護措施(如果某主機故障,沒完沒了傳輸廣播幀流,交換機會轉發所有這些幀,使得整個以太網崩潰)
- 路由器
- 優點
- 分組不會被限制在一棵生成樹上,進而能用各種拓撲結構來建構網際網路
- 對廣播風暴提供了防火牆保護
- 缺點
- 不是即插即用(需要人為配置IP位址)
- 對分組的處理時間更長(必須處理高達第3層的字段)
通常,由幾百台主機組成的小網絡通常有幾個LAN網段,對于這些小網絡,交換機就足夠了,因為它們不要求IP位址的任何配置就能使流量局部化并增加總吞吐量。但是在由幾千台主機組成的更大網絡中,通常在網絡中還包括路由器。路由器提供了更健壯的流量隔離方式和對廣播風暴的控制,并在網絡的主機之間使用更“智能的”路由
【QA】
1.為什麼運輸層使用檢驗和而鍊路層使用CRC呢?
- 運輸層差錯檢驗用軟體實作,采用簡單快速的檢驗和的方式。
- 鍊路層的差錯檢測在擴充卡中采用專用硬體實作。
2.為什麼網絡層和鍊路層都需要位址?
- 保持各層的獨立,區域網路是為任意網絡層協定而設計的,不隻用于IP和網際網路。
- 如果擴充卡使用IP位址,則擴充卡不能友善的支援其他網絡層協定,且IP位址必須存儲在擴充卡的RAM中。
- 如果擴充卡中不适用任何位址,則主機将被區域網路上發送的每個幀中斷。
- 如果網絡層使用MAC位址,無法建構高效的路由選擇方案,增加一個附加層的位址尋址,可以使得裝置更易于移動和維修
6.實體層
- 傳輸資料的機關 ———— 比特
- 資料傳輸系統:源系統(源點、發送器) --> 傳輸系統 --> 目的系統(接收器、終點)
通道:
- 單向通道(單工通道):隻有一個方向通信,沒有反方向互動,如廣播
- 雙向交替通行(半雙工通信):通信雙方都可發消息,但不能同時發送或接收
- 雙向同時通信(全雙工通信):通信雙方可以同時發送和接收資訊
通道複用技術:
- 頻分複用(FDM,Frequency Division Multiplexing):不同使用者在不同頻帶,所用使用者在同樣時間占用不同帶寬資源
- 時分複用(TDM,Time Division Multiplexing):不同使用者在同一時間段的不同時間片,所有使用者在不同時間占用同樣的頻帶寬度
- 波分複用(WDM,Wavelength Division Multiplexing):光的頻分複用
- 碼分複用(CDM,Code Division Multiplexing):不同使用者使用不同的碼,可以在同樣時間使用同樣頻帶通信
7.網絡錯誤排查
- 聯系ping等檢查網絡是否通暢來考察你對問題的追溯程度,比如網絡通,但是拿不到伺服器上的資源,怎麼辦,防火牆封閉了端口?如果端口也開了呢,怎麼辦,dns解析有問題?怎麼弄?
- tcpdump抓到的包如何分析?
- 寫入到.pcap檔案中,使用wireshark或packetyzer檢視分析
- 在你們的運維平台上重新整理了一條資源如何檢測這條資源有沒有重新整理成功?
- 網易雲音樂的評論無法加載,如何排查?說出思路,各業務子產品監控名額QPS均無抖降點,但是問題依舊存在,為什麼?
- 如何在linux上添加路由?我添加了一條路由之後還是ping不通,可能的原因有哪些?
- 出不去:網關不通,出去的路被防火牆檔了
- 回不來:被丢棄,回來的報被擋了
8.Socket網絡程式設計
- 有哪些系統調用?
- Server:socket、bind、listen、accept、read、write、read、…、close
- Client: socket、connect、write、read、write、…、close
- 建立連接配接的過程
- 伺服器調用socket()、bind()、listen()函數完成初始化後,調用accept()阻塞等待。
- 用戶端調用socket()初始化後,調用connect()發出SYN段并阻塞等待伺服器應答。
- 伺服器應答一個SYN-ACK段,用戶端收到後從connect()傳回,同時應答一個ACK段,伺服器收到後從accept()傳回,TCP鍊路建立。
- 資料傳輸的過程
- 伺服器從accept()傳回後立即調用read(),讀socket就像讀管道一樣,如果沒有資料到達就阻塞等待。
- 這時用戶端調用write()發送請求給伺服器,
- 伺服器收到後從read()傳回,對用戶端的請求進行處理,在此期間用戶端調用read()阻塞等待伺服器的應答。
- 伺服器調用write()将處理結果發回給用戶端,再次調用read()阻塞等待下一條請求,
- 用戶端收到後從read()傳回,發送下一條請求,如此循環下去。
- 關閉連接配接的過程
- 如果用戶端沒有更多請求了,就調用close()關閉連接配接,就像寫端關閉的管道一樣,伺服器的read()傳回0。
- 這樣伺服器就知道用戶端關閉了連接配接,也調用close()關閉連接配接。
- 注意,任何一方調用close()後,連接配接的兩個傳輸方向都關閉,不能再發送資料了。如果一方調用shutdown()則連接配接處于半關閉狀态,仍可接收對方發來的資料。
- close是一次就能直接關閉嗎?
- 半關閉狀态shut_down
Socket 中的 read()、write() 函數
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count); read()
- read 函數是負責從 fd 中讀取内容。
- 當讀成功時,read 傳回實際所讀的位元組數。
- 如果傳回的值是 0 表示已經讀到檔案的結束了,小于 0 表示出現了錯誤。
- 如果錯誤為 EINTR 說明讀是由中斷引起的;如果是 ECONNREST 表示網絡連接配接出了問題。
write()
- write 函數将 buf 中的 nbytes 位元組内容寫入檔案描述符 fd。
- 成功時傳回寫的位元組數。失敗時傳回 -1,并設定 errno 變量。
- 在網絡程式中,當我們向套接字檔案描述符寫時有倆種可能。
- (1)write 的傳回值大于 0,表示寫了部分或者是全部的資料。
- (2)傳回的值小于 0,此時出現了錯誤。
- 如果錯誤為 EINTR 表示在寫的時候出現了中斷錯誤;如果為 EPIPE 表示網絡連接配接出現了問題(對方已經關閉了連接配接)。
Socket 中 TCP 的三次握手建立連接配接
我們知道 TCP 建立連接配接要進行 “三次握手”,即交換三個分組。大緻流程如下:
- 用戶端向伺服器發送一個 SYN J
- 伺服器向用戶端響應一個 SYN K,并對 SYN J 進行确認 ACK J+1
- 用戶端再想伺服器發一個确認 ACK K+1
隻有就完了三次握手,但是這個三次握手發生在 Socket 的那幾個函數中呢?請看下圖:
從圖中可以看出:
- 當用戶端調用 connect 時,觸發了連接配接請求,向伺服器發送了 SYN J 包,這時 connect 進入阻塞狀态;
- 伺服器監聽到連接配接請求,即收到 SYN J 包,調用 accept 函數接收請求向用戶端發送 SYN K ,ACK J+1,這時 accept 進入阻塞狀态;
- 用戶端收到伺服器的 SYN K ,ACK J+1 之後,這時 connect 傳回,并對 SYN K 進行确認;
- 伺服器收到 ACK K+1 時,accept 傳回,至此三次握手完畢,連接配接建立。
Socket 中 TCP 的四次握手釋放連接配接
上面介紹了 socket 中 TCP 的三次握手建立過程,及其涉及的 socket 函數。現在我們介紹 socket 中的四次握手釋放連接配接的過程,請看下圖:
圖示過程如下:
- 某個應用程序首先調用 close 主動關閉連接配接,這時 TCP 發送一個 FIN M;
- 另一端接收到 FIN M 之後,執行被動關閉,對這個 FIN 進行确認。它的接收也作為檔案結束符傳遞給應用程序,因為 FIN 的接收意味着應用程序在相應的連接配接上再也接收不到額外資料;
- 一段時間之後,接收到檔案結束符的應用程序調用 close 關閉它的 socket。這導緻它的 TCP 也發送一個 FIN N;
- 接收到這個 FIN 的源發送端 TCP 對它進行确認。
這樣每個方向上都有一個 FIN 和 ACK。
歡迎通路我的網站:
BruceOu的哔哩哔哩
BruceOu的首頁
BruceOu的部落格
接收更多精彩文章及資源推送,請訂閱我的微信公衆号: